









梯度下降
整体的推导过程非常简单,但可能有些读者更习惯看代码,那么我也贴心的附上整个公式推导的代码,一步步调试更适合程序员学习方法~~O(∩_∩)O~ ,可以直接跳转到第二节配合着第一节的公式推导仔细观看,只需要10分钟直观了解梯度下降算法(本文只是梯度下降的一个简单实例来讲解,方便后续理解更复杂网络中梯度下降算法怎么运转,如果您迟迟没有开始了解,认为其其他作者写的太难,不妨从我这由易到难)。
1. 简单的线性回归的梯度下降
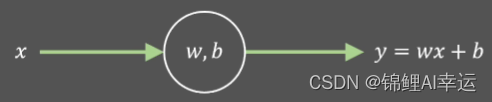
1.1 初始化
线 性 模 型 函 数 :
y
=
w
x
+
b
y = wx + b
y=wx+b (1)
损 失 函 数 :
L
=
1
2
(
y
−
y
g
t
)
2
L=\frac{1}{2}\left(y-y_{g t}\right)^2
L=21(y−ygt)2 (2)
随机初始化权重 :
w
0
=
0.8
w_0=0.8
w0=0.8
b
0
=
0.2
b_0=0.2
b0=0.2
初始化后线性模型 :
y
=
0.8
x
+
0.2
y = 0.8x + 0.2
y=0.8x+0.2 (3)
学习率 :
α
=
0.1
\alpha =0.1
α=0.1
一组真实数据:
(
x
,
y
g
t
)
=
(
1.5
,
0.8
)
(x, y_{g t})=(1.5, 0.8)
(x,ygt)=(1.5,0.8)
我们把他喂入到线性模型中训练一次,观察正向传播和反向传播的过程,其中重点看看反向传播中的梯度下降算法起到什么作用。
1.2 正向传播
将真实数据: ( x , y g t ) = ( 1.5 , 0.8 ) (x, y_{g t})=(1.5, 0.8) (x,ygt)=(1.5,0.8) 中的 x x x代入初始化好的线性模型公式(3)中,得到模型算的 y y y:
y = 0.8 × 1.5 + 0.2 = 1.4 = y 0 y = 0.8 × 1.5 + 0.2 =1.4=y_0 y=0.8×1.5+0.2=1.4=y0
1.3 反向传播
梯度: (把权重 w w w与偏置 b b b当做会更新变量,那么线性方程公式(1)就是关于 w w w和 b b b的影响的函数,我们是使用损失函数 公式(2) 来修调整公式(3) 中的权重 w w w与偏置 b b b, 所以对公式(2) 中的L求梯度采用链式求导法则求偏导值,可求出关于 w w w和 b b b的梯度,并乘上学习率,公式计算过程如下):
∂ L ∂ w = ∂ L ∂ y ∂ y ∂ w = ( y − y g t ) x = ( 1.4 − 0.8 ) × 1.5 = 0.9 ∂ L ∂ b = ∂ L ∂ y ∂ y ∂ b = y − y g t = 1.4 − 0.8 = 0.6 \begin{aligned} &\frac{\partial L}{\partial w}=\frac{\partial L}{\partial y} \frac{\partial y}{\partial w}=\left(y-y_{g t}\right) x = (1.4 - 0.8)×1.5 = 0.9 \\ &\frac{\partial L}{\partial b}=\frac{\partial L}{\partial y} \frac{\partial y}{\partial b}=y-y_{g t} = 1.4 - 0.8 = 0.6 \end{aligned} ∂w∂L=∂y∂L∂w∂y=(y−ygt)x=(1.4−0.8)×1.5=0.9∂b∂L=∂y∂L∂b∂y=y−ygt=1.4−0.8=0.6
更新
w
,
b
w,b
w,b一次为
w
1
,
b
1
w_{1} , b_{1}
w1,b1:
w
1
=
w
−
α
∂
L
∂
w
=
0.8
−
0.1
×
0.9
=
0.71
b
1
=
b
−
α
∂
L
∂
b
=
0.2
−
0.1
×
0.6
=
0.14
w_{1} = w - \alpha \frac{\partial L}{\partial w} = 0.8 - 0.1×0.9=0.71 \\ b_{1} = b - \alpha \frac{\partial L}{\partial b} = 0.2 - 0.1×0.6 = 0.14
w1=w−α∂w∂L=0.8−0.1×0.9=0.71b1=b−α∂b∂L=0.2−0.1×0.6=0.14
得到反向传播梯度后的线性模型:
y = 0.71 x + 0.14 y = 0.71x + 0.14 y=0.71x+0.14
1.4 最后对比更新前后的模型loss
将真实数据:
(
x
,
y
)
=
(
1.5
,
0.8
)
(x, y)=(1.5, 0.8)
(x,y)=(1.5,0.8)带入到初始化权值的公式与反向传播一轮的公式中:(为了区分后续的结果,设初始化函数正向传播的结果为
y
0
y_{0}
y0,更新后的为
y
1
y_{1}
y1)
y
=
0.8
x
+
0.2
=
1.4
=
y
0
y
=
0.71
x
+
0.14
=
0.71
×
1.5
+
0.14
=
1.205
=
y
1
y = 0.8x + 0.2 = 1.4 = y_{0}\\ y = 0.71x + 0.14 = 0.71× 1.5 + 0.14 = 1.205 =y_{1}
y=0.8x+0.2=1.4=y0y=0.71x+0.14=0.71×1.5+0.14=1.205=y1
将两者代入损失函数公式(2)中,:
L
0
=
1
2
(
y
−
y
g
t
)
2
=
1
2
(
1.4
−
0.8
)
2
=
0.18
L
1
=
1
2
(
y
−
y
g
t
)
2
=
1
2
(
1.205
−
0.8
)
2
=
0.0820125
L_{0}=\frac{1}{2}\left(y-y_{g t}\right)^2 = \frac{1}{2}\left(1.4-0.8\right)^2 = 0.18\\ L_{1}=\frac{1}{2}\left(y-y_{g t}\right)^2 = \frac{1}{2}\left(1.205-0.8\right)^2 = 0.0820125
L0=21(y−ygt)2=21(1.4−0.8)2=0.18L1=21(y−ygt)2=21(1.205−0.8)2=0.0820125
显然
0.0820125
<
0.18
0.0820125 < 0.18
0.0820125<0.18 ,说明喂入数据后,经过模型训练,梯度下降算法更新权重后,所得的loss值越来越小,效果变好了!!!
2.上述公式推导代码
为了便于大家方便读懂,采用常规训练的模板格式。
import torch
def loss_func(y_true: torch.Tensor, y_pre: torch.Tensor):
square = 1 / 2 * (y_true - y_pre) ** 2
return square.mean()
def train(Epoch):
for i in range(Epoch):
# 线性模型
y_pre = w * x + b
loss = loss_func(y, y_pre)
loss.backward()
# 更新
print("对权值w求偏导值为: {} --- 对权值b求偏导值为: {}".format(w.grad, b.grad))
w.data -= w.grad * alpha
b.data -= b.grad * alpha
# 清除梯度值
w.grad.data.zero_()
b.grad.data.zero_()
print('Epoch {}, loss is {:.4f}. 更新后的权重: w = {:.2f}, b = {:.2f}'.format(i, loss.item(), w.item(), b.item()))
print("第一轮更新w, b后的再次正向传播所得到的损失值为: {} \n".format(loss_func(y, w * x + b)))
if __name__ == '__main__':
# 初始化权重w, b
w = torch.tensor([0.8], requires_grad=True)
b = torch.tensor([0.2], requires_grad=True)
# 给出一组真实数据( x, y ) = ( 1.5, 0.8 )
train_data = [torch.tensor([1.5], requires_grad=True), torch.tensor([0.8], requires_grad=True)]
x, y = train_data
# 设置学习率 α = 0.1
alpha = 0.1
# =====-----开始训练train-----=====
train(Epoch=1)
那么按照上述的公式推导,训练Epoch=1所得出的日志数据与推导过程无误:
对权值w求偏导值为: tensor([0.9000]) — 对权值b求偏导值为: tensor([0.6000]) -----<1.3节前可见数值>
Epoch 0, loss is 0.1800. 更新后的权重: w = 0.71, b = 0.14 -----<1.3节中可见数值>
第一轮更新w, b后的再次正向传播所得到的损失值为: 0.08201246708631516 -----<1.4节末可见数值>
3.进阶训练多组数据
import torch
class LinearRegression:
def __init__(self):
self.w = torch.tensor([0.8], requires_grad=True)
self.b = torch.tensor([0.2], requires_grad=True)
def forward(self, x):
y = self.w * x + self.b
return y
def parameters(self):
return [self.w, self.b]
def __call__(self, x):
return self.forward(x)
class Optimizer:
def __init__(self, parameters, lr):
self.parameters = parameters
self.lr = lr
def step(self):
for para in self.parameters:
para.data -= para.grad * self.lr
def zero_grad(self):
for para in self.parameters:
para.grad.data.zero_()
def loss_func(y_true: torch.Tensor, y_pre: torch.Tensor):
square = 1 / 2 * (y_true - y_pre) ** 2
return square.mean()
def train(Epoch, lr):
model = LinearRegression()
opt = Optimizer(model.parameters(), lr)
for epoch in range(Epoch):
output = model(x_train)
loss = loss_func(y_train, output)
loss.backward()
opt.step()
opt.zero_grad()
print('Epoch {}, loss is {:.4f}. 当前的权值: w = {:.2f}, b = {:.2f}'.format(epoch+1, loss.item(), model.w.item(), model.b.item()))
if __name__ == '__main__':
# 用线性公式构造简单的训练样本
x_train = torch.rand(100)
y_train = x_train * 2 + 3
# 设置学习率 α = 0.1
alpha = 0.1
# =====-----开始训练train-----=====
train(Epoch=15, lr=alpha)
因为我们输入值: x_train是随机出来的数据,真实值:y_train 是由x_train * 2 + 3得来的,所以模型的
w
w
w应该越趋向于更新至
2
2
2,
b
b
b应该趋向于
3
3
3。
Epoch 1, loss is 5.8310. 当前的权值: w = 0.98, b = 0.54
Epoch 2, loss is 4.4496. 当前的权值: w = 1.13, b = 0.84
Epoch 3, loss is 3.3955. 当前的权值: w = 1.27, b = 1.10
Epoch 4, loss is 2.5912. 当前的权值: w = 1.39, b = 1.32
Epoch 5, loss is 1.9776. 当前的权值: w = 1.49, b = 1.52
Epoch 6, loss is 1.5093. 当前的权值: w = 1.58, b = 1.69
Epoch 7, loss is 1.1520. 当前的权值: w = 1.66, b = 1.85
Epoch 8, loss is 0.8794. 当前的权值: w = 1.73, b = 1.98
Epoch 9, loss is 0.6714. 当前的权值: w = 1.79, b = 2.09
Epoch 10, loss is 0.5127. 当前的权值: w = 1.84, b = 2.20
Epoch 11, loss is 0.3915. 当前的权值: w = 1.89, b = 2.28
Epoch 12, loss is 0.2991. 当前的权值: w = 1.93, b = 2.36
Epoch 13, loss is 0.2286. 当前的权值: w = 1.96, b = 2.43
Epoch 14, loss is 0.1748. 当前的权值: w = 1.99, b = 2.49
Epoch 15, loss is 0.1337. 当前的权值: w = 2.02, b = 2.54


















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











