





基于网络表示学习(Network Representation Learning)的复杂网络中有影响力节点识别
一个节点所属的社区越多,节点可以影响的社区就越多。 节点的网络约束系数可以看作是社区中的传播速度。 节点的约束系数越小,节点传播信息的速度就越快
1、背景知识
1.1 网络表示学习(NRL)模型
网络表示学习旨在学习网络中每个顶点的分布式向量表示。 它也越来越被认为是网络分析的一个重要方式。 网络表示学习任务可以大致抽象为以下四大类:(a)节点分类,(b)链路预测,©聚类,(d)可视化。
研究者们提出了网络表示学习的BIGCLAM详情戳这里模型,该模型还涵盖了重叠社区检测。该模型假设社区的重叠往往比不重叠部分更密集地连接。

如上图,顶部的圆圈代表社区,底部的正方形代表图形的节点,边缘表示节点社区从属关系。节点对社区的权重越高,节点就越有可能连接到该社区中的成员。每个社区以概率
1
−
e
x
p
(
−
F
u
c
∗
F
v
c
)
1-exp(-F_{uc }* F_{vc} )
1−exp(−Fuc∗Fvc)在节点
u
u
u和节点
v
v
v之间创造连边。其中
F
u
c
F_{uc}
Fuc是节点
u
u
u对社区
c
c
c的非负权重值。此外,该模型假设每个社区独立地创建边。举个栗子,上图a图中节点
u
u
u和节点
v
v
v都同时属于社区A和B。而在上图b中,
F
u
A
F_{uA}
FuA和
F
u
B
F_{uB}
FuB分别代表了节点
u
u
u隶属于社区A和B的权重值。在社区A中。节点
u
u
u和节点
v
v
v之间存在连边的概率为
1
−
e
x
p
(
−
F
u
A
∗
F
v
A
)
1-exp(-F_{uA}* F_{vA} )
1−exp(−FuA∗FvA),当然,在社区B中则是
1
−
e
x
p
(
−
F
u
B
∗
F
v
B
)
1-exp(-F_{uB}* F_{vB} )
1−exp(−FuB∗FvB)。故节点
u
u
u和节点
v
v
v之间存在连边的概率为
1
−
e
x
p
(
−
∑
c
∈
A
,
B
F
u
c
∗
F
v
c
)
1-exp(-\sum_{c \in A, B}F_{uc}* F_{vc} )
1−exp(−∑c∈A,BFuc∗Fvc)。
给定
G
=
(
V
,
E
)
G=(V,E)
G=(V,E)以及非负矩阵
F
∈
R
N
∗
K
F \in R^{N* K}
F∈RN∗K,其中
N
N
N是节点的数目,
K
K
K是社区的数目。BIGCLAM通过以概率
p
(
u
,
v
)
p(u,v)
p(u,v)在节点对
u
,
v
∈
V
u,v \in V
u,v∈V之间产生边
(
u
,
v
)
(u,v)
(u,v)来生成图G:

其中
F
u
F_u
Fu是节点
u
u
u的权重向量,向量中的每个值都代表了该节点与对应社区的权重。该模型旨在通过最大似然寻找网络G的最可能的隶属因子矩阵
F
^
\hat{F}
F^:

其中

我们取似然的对数,称之为对数似然

倒数第二个公式是该模型的优化对象。在取得
F
^
\hat{F}
F^之后,该模型会对节点隶属的社区进行判断。设定一个阈值,当
F
u
c
F_{uc}
Fuc大于该阈值,则认为节点
u
u
u隶属于社区
c
c
c。基于BIGCLAM模型,我们假设社区中的节点重叠在社区之间起着“桥梁”作用。 由于这些节点属于多个社区,通过这些节点的信息可以很容易地传播到其他社区。
1.2 网络约束系数(Network constraint coefficient)
“structural hole”——有着完整信息源的个体桥梁
下图中(a)就是节点E的 structural hole。节点E的位置使它成为三个不同节点之间的桥梁或“代理。

通过形成structural hole 来形成网络约束系数:

其中
Γ
(
i
)
\Gamma_{(i)}
Γ(i)是节点
i
i
i的邻居,
ρ
i
j
=
1
N
(
i
)
\rho_{ij}= \frac{1}{N(i)}
ρij=N(i)1是节点i在与节点j关系中投入精力占比,其中
N
(
i
)
N(i)
N(i)是节点i的度。从上面可以看出,约束系数较小的节点度较大,邻域之间的连接稀疏。 因此,约束系数较小的节点将有更多的机会将信息传播到网络的很大一部分。 节点的约束系数越小,节点传播信息的速度就越快。
2、提出的方法
我们考虑节点的传播容量和传播速度来评估它的影响,用OC表示:
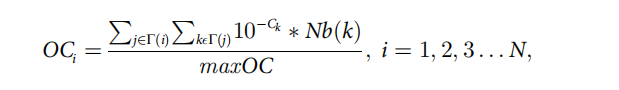
其中
C
k
C_k
Ck是网络制约系数,maxOC 是归一化因子,
N
b
(
k
)
Nb(k)
Nb(k)是节点k所属的社区数目。为了识别网络中有影响的节点,我们需要知道每个节点所属的社区总数及其约束系数。 首先,我们使用BIGCLAM模型来检测重叠社区,并计算每个节点所属的社区总数。 第二,我们计算每个节点的网络约束系数














 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









