







Apache Storm
背景介绍
流计算:将大规模流动数据在不断变化的运动过程中实现数据的实时分析,捕捉到可能有用的信息,并把结果发送到下一计算节点。
主流流计算框架:Kafka Streaming、Apache Storm、Spark Streaming、Flink DataStream等。
- Kafka Streaming:是一套基于Kafka-Streaming库的一套流计算工具jar包,具有简单容易集成等特点。
- Apache Storm:流处理框架实现对流数据流的处理和状态管理等操作。
- Spark Streaming:是基于Spark 离散 RDD 的小批量内存计算,因为计算速度比较快,被认定为实时
流|批处理。- Flink DataStream:Stateful Computations over Data Streams,Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能,在流处理领域中借鉴了Storm和SparkStreaming的优势作为第三代流处理框架。
What is Apache Storm?
Apache Storm提供了一种基于Topology流计算概念,该概念等价于hadoop的mapreduce计算,但是不同于MapReduce计算因为MR计算会最终终止,但是Topology计算会一直运行下去,除非用户执行storm kill指令该计算才会终止.Storm提供了高可靠/可扩展/高度容错的流计算服务 ,该服务可以保证数据|Tuple可靠性处理(至少一次|精确1次)处理机制.可以方便的和现用户的服务进行集成,例如:HDFS/Kafka/Hbase/Redis/Memcached/Yarn等服务集成.Storm的单个阶段每秒钟可以处理100万条数据|Tuple
Storm 架构

nimbus:计算任务的主节点,负责分发代码/分配任务/故障检测 Supervisor任务执行.
supervisor:接受来自Nimbus的任务分配,启动Worker进程执行计算任务.
zookeeper:负责Nimbus和Supervisor协调,会使用zk存储nimbus和supervisor进程状态信息,这就导致了Nimbus和Supervisor是无状态的可以实现任务快速回复,即而让流计算达到难以置信的稳定.
Worker:是Supervisor专门为某一个Topology任务启动的一个Java 进程,Worker进程通过执行Executors(线程)计算任务,一个Executor执行1~n个Task.一旦Topology被kill,该Topology下的所有worker进程退出.
注意:只有Nimbus和Supervisor进程是常驻内存的,worker进程是在Topology提交的运行的时候才会启动,如果大家有Map Reduce编程经验,大家可以将nimbus理解为ResourceManager、Supervisor等价于NodeManager、Worker等价于Container
Storm环境
Storm 编译
由于Storm在和消息队列Kafka整合的的时候,存在bugSTORM-3046为了后期的使用方便这里,需要大家下载storm-1.2.3源码包,然后通过Maven编译。
编译Storm
[root@CentOS ~]# tar -zxf apache-maven-3.3.9-bin.tar.gz -C /usr/
[root@CentOS ~]# vi .bashrc
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
M2_HOME=/usr/apache-maven-3.3.9
STORM_HOME=/usr/apache-storm-1.2.3
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin:$STORM_HOME/bin:$M2_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
export STORM_HOME
export M2_HOME
[root@CentOS ~]# source .bashrc
[root@CentOS ~]# tar -zxf storm-1.2.3.tar.gz
[root@CentOS ~]# cd storm-1.2.3
[root@CentOS storm-1.2.3]# mvn clean package install -DskipTests=true
[root@CentOS storm-1.2.3]# cd storm-dist/binary
[root@CentOS binary]# mvn package -Dgpg.skip=true
在编译前,需要在本地的maven仓库的的repository\org\fusesource\sigar\1.6.4目录下添加一个文件
hyperic-sigar-1.6.4.zip.因为Storm在编译storm-metrics模块的时候需要从https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/magelan/hyperic-sigar-1.6.4.zip下载该文件,然后将该文件放置在本地仓库,因为国内一些原因,无法访问google,需要翻墙才能访问,因此这里需要大家自行将该文件下载下来,并且提前放置在repository\org\fusesource\sigar\1.6.4目录下即可。下载地址:链接:https://pan.baidu.com/s/1r7AXOu63f5YeQZv-qnvUXQ 提取码:oiqz

指令执行结束后,在storm-1.2.3/storm-dist/binary/target目录下会产生apache-storm-1.2.3.tar.gz文件.该文件为Storm运行文件。
Maven依赖问题
进入storm-1.2.3的文件后再pom.xml问价中添加两个配置
部署配置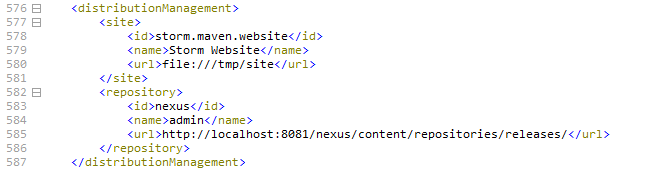
<distributionManagement>
<site>
<id>storm.maven.website</id>
<name>Storm Website</name>
<url>file:///tmp/site</url>
</site>
<repository>
<id>nexus</id>
<name>admin</name>
<url>http://localhost:8081/nexus/content/repositories/releases/</url>
</repository>
</distributionManagement>
配置该属性的目的是,在编译完成storm之后,用户可以执行deploy将storm-1.2.3依赖部署到maven私服。
源码插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>3.0.1</version>
<configuration>
<attach>true</attach>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
添加以上插件目的是为了在部署到nexus的时候,系统会自动的将源码也部署上去。然后执行以下脚本,耐心等待,即可将该版本的所有依赖 jar和源码jar部署到私服上了。
[root@CentOS storm-1.2.3]# mvn deploy -DskipTests=true

Storm安装
- 安装JDK,要求1.8+,配置JAVA_HOME
[root@CentOS ~]# rpm -ivh jdk-8u171-linux-x64.rpm
Preparing... ########################################### [100%]
1:jdk1.8 ########################################### [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
[root@CentOS ~]# vi .bashrc
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
[root@CentOS ~]# source .bashrc
- 配置主机名和IP映射关系
[root@CentOS ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.38.129 CentOS
- 关闭防火墙
[root@CentOS ~]# vi /etc/hosts
[root@CentOS ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOS ~]# chkconfig iptables off
- 安装Zookeeper
[root@CentOS ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr/
[root@CentOS ~]# mkdir zkdata
[root@CentOS ~]# cp /usr/zookeeper-3.4.6/conf/zoo_sample.cfg /usr/zookeeper-3.4.6/conf/zoo.cfg
[root@CentOS ~]# vi /usr/zookeeper-3.4.6/conf/zoo.cfg
tickTime=2000
dataDir=/root/zkdata
clientPort=2181
[root@CentOS ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start zoo.cfg
JMX enabled by default
Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@CentOS ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh status zoo.cfg
JMX enabled by default
Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: standalone
- 安装配置Storm
[root@CentOS ~]# tar -zxf apache-storm-1.2.2.tar.gz -C /usr/
[root@CentOS ~]# vi .bashrc
STORM_HOME=/usr/apache-storm-1.2.3
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin:$STORM_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
export STORM_HOME
[root@CentOS ~]# source .bashrc
[root@CentOS ~]# vi /usr/apache-storm-1.2.3/conf/storm.yaml
storm.zookeeper.servers:
- "CentOS"
storm.local.dir: "/usr/apache-storm-1.2.3/storm-stage"
nimbus.seeds: ["CentOS"]
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 启动Storm
[root@CentOS ~]# nohup storm nimbus >/dev/null 2>&1 &
[root@CentOS ~]# nohup storm supervisor >/dev/null 2>&1 &
[root@CentOS ~]# nohup storm ui >/dev/null 2>&1 &
启动storm ui是Storm计算的状态页面,用户可以访问该页面完成对Topology任务的管理和并行度参数察看等。
- 检测启动成功
[root@CentOS ~]# jps
1682 nimbus
1636 QuorumPeerMain
2072 Jps
1721 Supervisor
1772 core

Topology
Topologies:包含实时计算的逻辑,一个完成Topology(任务),是由Spout和Bolt连接形成一个计算图表Graph(DAG).Spout和Bolt组件通过stream grouping|Shuffle方式连接起来.
Streams:Streams是一些列无止境的Tuples,这些Tuple都有schema ,该Schema描述了Tuple中的filed的名字.
Streams <==> List<Tuple> + Schema(field1,field2,...)
元组 元素构成数组+ 命名元素|schema
Tuple t=new Tuple(new Object[]{zhangsan,18,true})
String name=t.getStringByField("name");
Boolean sex=t.getBooleanByField("sex");
Spouts:负责产生Tuple,是Streams源头.通常是通过Spout读取外围系统的数据,并且将数据封装成Tuple,并且将封装Tuple发射|emit到Topology中.IRichSpout|BaseRichSpout
Bolts:所有的Topology中的Tuple是通过Bolt处理,Bolt作用是用于过滤/聚合/函数处理/join/存储数据到DB中等.
IRichBolt|BaseRichBolt,IBasicBolt|BaseBasicBolt,IStatefulBolt | BaseStatefulBolt
参考:http://storm.apache.org/releases/1.2.2/Concepts.html
入门案例
public class TopologyBuilderTests {
public static void main(String[] args) throws Exception {
//1.创建TopologyBuilder,编制Topology任务
TopologyBuilder builder=new TopologyBuilder();
Config config = new Config();
config.setDebug(false);
config.setNumAckers(0);
config.setNumWorkers(2);
//2.设置Spout,不间断的向streams中发射字符串
builder.setSpout("WordSpout",new WordSpout());
//3.设置Bolt用于处理上游的Tuple,并将一行文本拆解成单个字符
builder.setBolt("LineSplitBolt",new LineSplitBolt(),2)
.setNumTasks(4)
.shuffleGrouping("WordSpout");
//4.将上游的字符按照 word分区的形式发送给Bolt计算字符和字符出现的次数
builder.setBolt("WordCountBolt",new WordCountBolt(),4)
.fieldsGrouping("LineSplitBolt",new Fields("word"));
//5.按照word分区接收来自上游Bolt的输出,将结果打印在控制台
builder.setBolt("WordPrintBolt",new WordPrintBolt(),3)
.fieldsGrouping("WordCountBolt", new Fields("word"));
//6.将编制的Topology提交
StormSubmitter.submitTopology("Hello World",config,builder.createTopology());
}
}
WordSpout
public class WordSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] lines={"this is a test demo",
"Strom is easy to learn"};
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
@Override
public void nextTuple() {
Utils.sleep(1000);
String line = lines[new Random().nextInt(lines.length)];
collector.emit(new Values(line));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
LineSplitBolt
public class LineSplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String[] words = input.getStringByField("line").split("\\W+");
for (String word : words) {
collector.emit(new Values(word));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WordCountBolt
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
private Map<String,Integer> wordMap;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
wordMap=new HashMap<String,Integer>();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
int count=0;
if(!wordMap.containsKey(word)){
count=1;
}else{
count=wordMap.get(word)+1;
}
wordMap.put(word,count);
collector.emit(new Values(word,count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
}
WordPrintBolt
public class WordPrintBolt extends BaseRichBolt {
@Override
public void prepare(Map stormConf,TopologyContext context, OutputCollector collector) { }
@Override
public void execute(Tuple input) {
System.out.println(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) { }
}
- 任务提交
远程提交
[root@CentOS ~]# storm jar xxx.jar 入口类全限定名
仿真提交
//测试环境
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("Hello World",config,topology);
将StormSubmitter更改为LocalCluster即可
- 查看任务列表
[root@CentOS ~]# storm list
Topology_name Status Num_tasks Num_workers Uptime_secs
-------------------------------------------------------------------
Hello World ACTIVE 12 2 58
- 删除Topology
[root@CentOS ~]# storm kill 'Hello World'
Storm 任务并行度
分析入门案例的代码Storm集群在接收到以上的Topology之后会尝试将任务拆解成4个阶段,并且得到如下矢量状态执行图:

可以在Storm UI页面中看到共计启动10个线程运行12个Task.
在用户提交一个任务的时候,Storm 首先会根据用户设定的config.setNumWorkers方法启动Woker服务,由Worker进程负责对整个Topology的任务并行度进行均分。也就说一个并行度就代表1个线程。在上诉入门案例中系统启动了2个Work服务,该Worker服务负责将负责这10个线程的执行。其中LineSplitBolt并行度设置为2但是Task设置为4,Storm会启动两个线程实例化4个LineSplitBolt负责将Spout发射的字符串拆分成字符。

现在可以将入门案例任务执行绘制如下:

storm rebalance
[root@CentOS ~]# storm rebalance 'Hello World' -w 5 -n 4

[root@CentOS ~]# storm rebalance 'Hello World' -w 5 -n 2 -e LineSplitBolt=4

参考:http://storm.apache.org/releases/1.2.2/Understanding-the-parallelism-of-a-Storm-topology.html
消息的可靠性保障
Storm 消息Tuple可以通过一个叫做__ackerBolt去监测整个Tuple Tree是否能够被完整消费,如果消费超时或者失败该__acker会调用Spout组件的fail方法,要求Spout重新发送Tuple.默认__ackerBolt并行度是和Worker数目一直,用户可以通过config.setNumAckers(0);关闭Storm的Acker机制。
Acker机制使用策略
//Spout在发射 tuple 的时候必须提供msgID
collector.emit(new Values(line),i);
//所有的下游的Bolt,必须锚定当前tuple,并且在处理完后,必须调用ack方法
try {
//锚定 当前 tuple
collector.emit(tuple,new Values(word,count));
//给上游应答
collector.ack(tuple);
} catch (Exception e) {
//通知失败
collector.fail(tuple);
}
Spout ack方法只有当TupleTree 被完整处理后才会被
__ackerBolt调用Spout#ack方法,但是Spout#Fail调用有两种情形:①当下游有任何一个Bolt调用了
collector.fail(tuple);②
__acker监测超时默认时间30 secs系统都会调用fail方法.
当启用Storm的Ack机制之后,处理的每个Tuple都必须被ack或fail。 因为Storm使用内存来跟踪每个元组,因此如果没有ack/fail每个Tuple,那么__ackerBolt最终会耗尽内存。
WordSpout写法
public class WordSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] lines={"this is a test demo",
"Strom is easy to learn"};
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
@Override
public void nextTuple() {
Utils.sleep(1000);
int msgId = new Random().nextInt(lines.length);
String line = lines[msgId];
//启动Acker机制
collector.emit(new Values(line),msgId);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
@Override
public void ack(Object msgId) {
//Tuple被完整处理系统回调
}
@Override
public void fail(Object msgId) {
//Tuple处理失败或者超时回调
}
}
LineSplitBolt
public class LineSplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String[] words = input.getStringByField("line").split("\\W+");
try {
for (String word : words) {
//设定Input锚定
collector.emit(input,new Values(word));
}
//进行确认Ack
collector.ack(input);
} catch (Exception e) {
//失败通知
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
在开启可靠传输之后,所有的Bolt都必须遵循这种ack和fail机制,为了方便Storm提供了IBasicBolt/BaseBasicBolt类帮助用户简化开发步骤,以上代码可以更改为:
public class LineSplitBolt extends BaseBasicBolt {
private OutputCollector collector;
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String[] words = input.getStringByField("line").split("\\W+");
for (String word : words) {
collector.emit(new Values(word));
}
}
}
如果可以重放元组,我如何使我的应用程序正常工作?
与软件设计一样,答案是“它取决于”具体的应用场景。如果你真的想要一次语义使用Trident API。在某些情况下,与大量分析一样,丢弃数据是可以的,因此通过将acker bolt的数量设置为0 Config.TOPOLOGY_ACKERS来禁用容错。但在某些情况下,您希望确保所有内容都至少处理过一次。如果所有操作都是幂等的,或者重复删除可能会发生,那么这尤其有用。
去除Storm可靠性,提升性能方案?
- 在Spout发射tuple时候,不提供msgID
- 在config设置config.setNumAckers(0);
- 取消在Bolt端的锚定,第一个bolt执行ack方法.
如何防止Spout挂起的Tuple数目过多,导致Topology内存紧张?
config.setMaxSpoutPending(100);
设置一个spout task上面最多有多少个没有处理(ack/fail)的tuple,防止tuple队列过大, 只对可靠任务起作用.
可靠机制算法原理解析
T1 ^ T2 ^ Tn … ^T1 ^ T2 … Tn =0
http://storm.apache.org/releases/1.2.2/Guaranteeing-message-processing.html
Storm 容错机制(了解)
Nimbus和Supervisor都是stateless ,即使服务宕机,机器可以通过Zookeeper和本地磁盘数据对任务进行恢复.如果Worker宕机会用Supervisor重新启动Worker进行,如果Supervisor宕机会有Nimbus将任务分配其他的Supervisor进行调度.
参考:http://storm.apache.org/releases/1.2.2/Daemon-Fault-Tolerance.html
Storm 状态管理
概述
Storm提供了一种机制使得Bolt可以存储和查询自己的操作的状态,目前Storm提供了一个默认的实现,该实现基于内存In-Memory实现,除此之外还提供了基于Redis/Memcached和Hbase等的实现.Storm提供了IStatefulBolt|BaseStatefulBolt 用于实现Bolt的状态管理.
public class WordCountBolt extends BaseStatefulBolt<KeyValueState> {
private KeyValueState<String,Integer> state;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext tc, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
//获取word值,如果没有返回默认值 1
Integer count = state.get(word, 0);
state.put(word,count+1);
//设置锚定
collector.emit(tuple,new Values(word,count+1));
//设置ack应答
collector.ack(tuple);
}
@Override
public void initState(KeyValueState keyValueState) {
this.state=keyValueState;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
}
Storm默认实现使用InMemoryKeyValueState,该种方式在JVM退出的时候,无法持久化Bolt状态,因此通常在开发环境下会使用Redis或者Hbase充当存储.
RedisState
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>1.2.2</version>
</dependency>
config.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.redis.state.RedisKeyValueStateProvider");
Map<String,Object> stateConfig=new HashMap<String,Object>();
Map<String,Object> redisConfig=new HashMap<String,Object>();
redisConfig.put("host","CentOS");
redisConfig.put("port",6379);
stateConfig.put("jedisPoolConfig",redisConfig);
ObjectMapper objectMapper=new ObjectMapper();
config.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
将结果存储到Redis-RedisStoreBolt
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder()
.setHost("CentOS").setPort(6379).build();
RedisStoreMapper storeMapper = new WordCountStoreMapper();
RedisStoreBolt storeBolt = new RedisStoreBolt(poolConfig, storeMapper);
RedisStoreMapper
public class WordCountStoreMapper implements RedisStoreMapper {
private RedisDataTypeDescription description;
public WordCountStoreMapper() {
description = new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.SORTED_SET, "zwordscount");
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return description;
}
@Override
public String getKeyFromTuple(ITuple iTuple) {
return iTuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple iTuple) {
return iTuple.getIntegerByField("count")+"";
}
}
HbaseState
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hbase</artifactId>
<version>1.2.2</version>
</dependency>
config.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.hbase.state.HBaseKeyValueStateProvider");
Map<String,Object> hbaseConfig=new HashMap<String,Object>();
hbaseConfig.put("hbase.zookeeper.quorum", "CentOS");
config.put("hbase.conf", hbaseConfig);
ObjectMapper objectMapper=new ObjectMapper();
Map<String,Object> stateConfig=new HashMap<String,Object>();
stateConfig.put("hbaseConfigKey","hbase.conf");
stateConfig.put("tableName","baizhi:state");
stateConfig.put("columnFamily","cf1");
config.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
**将计算结果存储到Hbase-**HBaseBolt
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("word")
.withColumnFields(new Fields("word"))
.withCounterFields(new Fields("count"))
.withColumnFamily("cf1");
HBaseBolt hbaseBolt = new HBaseBolt("baizhi:t_word_count", mapper)
.withConfigKey("hbase.conf");
Map<String,Object> hbaseConfig=new HashMap<String,Object>();
hbaseConfig.put("hbase.zookeeper.quorum", "CentOS");
config.put("hbase.conf", hbaseConfig);
Storm状态管理实现机制
参考:http://storm.apache.org/releases/1.2.2/State-checkpointing.html
Distributed RPC
Storm的DRPC真正的实现了并行计算.Storm Topology接受用户的参数进行计算,然后最终将计算结果以Tuple形式返回给用户.
搭建DRPC服务器
vi /usr/apache-storm-1.2.2/conf/storm.yaml
storm.zookeeper.servers:
- "CentOS"
storm.local.dir: "/usr/apache-storm-1.2.2/storm-stage"
nimbus.seeds: ["CentOS"]
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
drpc.servers:
- "CentOS"
storm.thrift.transport: "org.apache.storm.security.auth.plain.PlainSaslTransportPlugin"
启动DRPC服务器
[root@CentOS ~]# nohup storm drpc >/dev/null 2>&1 &
[root@CentOS ~]# nohup storm nimbus >/dev/null 2>&1 &
[root@CentOS ~]# nohup storm supervisor >/dev/null 2>&1 &
[root@CentOS ~]# nohup storm ui >/dev/null 2>&1 &
配置Maven依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>${storm.version}</version>
</dependency>
public class WordCountRedisLookupMapper implements RedisLookupMapper {
/**
*
* @param input 输入的Tuple
* @param value Redis查询到的值
* @return:将 返回的结果封装成 values
*/
@Override
public List<Values> toTuple(ITuple input, Object value) {
Object id = input.getValue(0);
List<Values> values = Lists.newArrayList();
if(value == null){
value = 0;
}
values.add(new Values(id, value));
return values;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "num"));
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.HASH, "wordcount");
}
@Override
public String getKeyFromTuple(ITuple tuple) {
return tuple.getString(1);
}
@Override
public String getValueFromTuple(ITuple tuple) {
return null;
}
}
---
public class TopologyDRPCStreeamTest {
public static void main(String[] args) throws Exception {
//1.创建TopologyBuilder,编制Topology任务
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("count");
Config conf = new Config();
conf.setDebug(false);
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder()
.setHost("192.168.38.129").setPort(6379).build();
RedisLookupMapper lookupMapper = new WordCountRedisLookupMapper();
RedisLookupBolt lookupBolt = new RedisLookupBolt(poolConfig, lookupMapper);
builder.addBolt(lookupBolt,4);
StormSubmitter.submitTopology("drpc-demo", conf, builder.createRemoteTopology());
}
}
---
public class TestDRPCTests {
public static void main(String[] args) throws TException {
Config conf = new Config();
conf.put("storm.thrift.transport", "org.apache.storm.security.auth.plain.PlainSaslTransportPlugin");
conf.put(Config.STORM_NIMBUS_RETRY_TIMES, 3);
conf.put(Config.STORM_NIMBUS_RETRY_INTERVAL, 10);
conf.put(Config.STORM_NIMBUS_RETRY_INTERVAL_CEILING, 20);
DRPCClient client = new DRPCClient(conf, "192.168.38.129", 3772);
String result = client.execute("count", "hello");
System.out.println(result);
}
}
Storm 集成 Kafka/Redis
Maven 依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>${storm.version}</version>
</dependency>
链接Kafka
TopologyBuilder tp=new TopologyBuilder();
Config conf = new Config();
KafkaSpoutConfig.Builder<String,String> builder=
new KafkaSpoutConfig.Builder<String,String>("CentOS:9092,CentOS:9093,CentOS:9094",
"topic01");
// null的tuple不处理
builder.setEmitNullTuples(false);
// 设置key-value 序列化
builder.setProp(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
builder.setProp(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 设置消费组
builder.setProp(ConsumerConfig.GROUP_ID_CONFIG,"consumer_id_01");
// 设置读取策略,从上一次未提交提交偏移量开始
builder.setFirstPollOffsetStrategy(
KafkaSpoutConfig.FirstPollOffsetStrategy.UNCOMMITTED_LATEST);
// 开启Tuple的应答,只有正常应答的Tuple,对应的offset才会提交
builder.setProcessingGuarantee(KafkaSpoutConfig.ProcessingGuarantee.AT_LEAST_ONCE);
// 设置每个分区最大未提交Commit数目,如果单个分区超设置值,系统就不在继续poll对应分区的数据,
// 解决Storm压背问题问题
builder.setMaxUncommittedOffsets(2);
// 设置 KafkaSpout
tp.setSpout("KafkaSpout",new KafkaSpout<>(builder.build()));
LineSplitBolt
public class LineSplitBolt extends BaseBasicBolt {
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String[] tokens = input.getStringByField("value").split("\\W+");
for (String token : tokens) {
collector.emit(new Values(token));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
tp.setBolt("LineSplitBolt",new LineSplitBolt()).shuffleGrouping("KafkaSpout");
这里需要注意必须BaseBasicBolt,否则会导致系统重新读取Kafka信息,导致数据重复计算。
WordCountBolt
public class WordCountBolt extends BaseStatefulBolt<KeyValueState<String,Integer>> {
private KeyValueState<String,Integer> state;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = state.get(word, 0)+1;
state.put(word,count);
collector.emit(input,new Values(word,count));
collector.ack(input);
}
@Override
public void initState(KeyValueState<String, Integer> state) {
this.state=state;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
Config conf = new Config();
conf.put(Config.TOPOLOGY_STATE_PROVIDER,
"org.apache.storm.redis.state.RedisKeyValueStateProvider");
String jedisConfigJson ="{\"jedisPoolConfig\":{\"port\":6379,\"host\":\"CentOS\"}}";
conf.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,jedisConfigJson);
RedisStoreBolt
public class WordCountRedisStoreMapper implements RedisStoreMapper {
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,
"wordcount");
}
@Override
public String getKeyFromTuple(ITuple tuple) {
return tuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple tuple) {
System.out.println("tuple:\t"+tuple);
return tuple.getIntegerByField("count").toString();
}
}
JedisPoolConfig jedisPoolConfig=new JedisPoolConfig.Builder()
.setHost("CentOS")
.setPort(6379)
.setTimeout(5000)
.build();
tp.setBolt("RedisStoreBolt",
new RedisStoreBolt(jedisPoolConfig, new WordCountRedisStoreMapper()))
.fieldsGrouping("WordCountBolt",new Fields("word"));
整体代码
TopologyBuilder tp=new TopologyBuilder();
//设置Redis Store存储
Map<String,Object> stateConfig=new HashMap<String,Object>();
Map<String,Object> redisConfig=new HashMap<String,Object>();
redisConfig.put("host","CentOS");
redisConfig.put("port",6379);
stateConfig.put("jedisPoolConfig",redisConfig);
ObjectMapper objectMapper=new ObjectMapper();
Config conf = new Config();
conf.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.redis.state.RedisKeyValueStateProvider");
String jedisConfigJson =objectMapper.writeValueAsString(stateConfig);
conf.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,jedisConfigJson);
//设置Kafka链接参数
KafkaSpoutConfig.Builder<String,String> builder=new KafkaSpoutConfig.Builder<String,String>(
"CentOS:9092,CentOS:9093,CentOS:9094", "topic01");
//设置key-value 序列化
builder.setProp(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
builder.setProp(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//设置消费组
builder.setProp(ConsumerConfig.GROUP_ID_CONFIG,"consumer_id_01");
//设置读取策略,从上一次未提交提交偏移量开始
builder.setFirstPollOffsetStrategy(KafkaSpoutConfig.FirstPollOffsetStrategy.UNCOMMITTED_LATEST);
//开启Tuple的应答,只有正常应答的Tuple,对应的offset才会提交
builder.setProcessingGuarantee(KafkaSpoutConfig.ProcessingGuarantee.AT_LEAST_ONCE);
//设置每个分区最大未提交Commit偏移量,如果单个分区超设置值,系统就不在继续poll对应分区的数据,解决压背问题问题
builder.setMaxUncommittedOffsets(2);
builder.setEmitNullTuples(false);
tp.setSpout("KafkaSpout",new KafkaSpout<>(builder.build()));
tp.setBolt("LineSplitBolt",new LineSplitBolt())
.shuffleGrouping("KafkaSpout");
tp.setBolt("WordCountBolt",new WordCountBolt())
.fieldsGrouping("LineSplitBolt",new Fields("word"));
//设置Redis Store Bolt链接参数
JedisPoolConfig jedisPoolConfig=new JedisPoolConfig.Builder()
.setHost("CentOS")
.setPort(6379)
.setTimeout(5000)
.build();
tp.setBolt("RedisStoreBolt",new RedisStoreBolt(jedisPoolConfig,new WordCountRedisStoreMapper()))
.fieldsGrouping("WordCountBolt",new Fields("word"));
//任务提交
StormSubmitter.submitTopology("kafkademo",conf,tp.createTopology());
[root@CentOS ~]# storm jar storm-1.0-SNAPSHOT.jar com.baizhi.demo09.KafkaSpoutTopology --artifacts ‘org.apache.storm:storm-redis:1.2.2,org.apache.storm:storm-kafka-client:1.2.2’
Storm 窗口函数
Storm核心支持处理窗口内的一组元组。 Windows使用以下两个参数指定:
- 窗口长度- the length or duration of the window
- 滑动间隔- the interval at which the windowing slides
Sliding Window
Tuples以窗口进行分组,窗口每间隔一段滑动间隔滑动除一个新的窗口。例如下面就是一个基于时间滑动的窗口,窗口每间隔10秒钟为一个窗口,每间隔5秒钟滑动一次窗口,从下面的案例中可以看到,滑动窗口是存在一定的重叠,也就是说一个tuple可能属于1~n个窗口 。
........| e1 e2 | e3 e4 e5 e6 | e7 e8 e9 |...
-5 0 5 10 15 -> time
|<------- w1 -->|
|<---------- w2 ----->|
|<-------------- w3 ---->|
Tumbling Window
Tuples以窗口分组,窗口滑动的长度恰好等于窗口长度,这就导致和Tumbling Window和Sliding Window最大的区别是Tumbling Window没有重叠,也就是说一个Tuple只属于固定某一个window。
| e1 e2 | e3 e4 e5 e6 | e7 e8 e9 |...
0 5 10 15 -> time
w1 w2 w3
TopologyBuilder tp=new TopologyBuilder();
tp.setSpout("ClickSpout",new ClickSpout(),1);
tp.setBolt("ClickMapBolt",new ClickMapBolt(),4)
.shuffleGrouping("ClickSpout");
ClickWindowCountBolt wb = new ClickWindowCountBolt();
wb.withWindow(BaseWindowedBolt.Duration.seconds(2),
BaseWindowedBolt.Duration.seconds(1));
tp.setBolt("ClickWindowCountBolt",wb,3)
.fieldsGrouping("ClickMapBolt",new Fields("click"));
tp.setBolt("PrintClickBolt",new PrintClickBolt())
.fieldsGrouping("ClickWindowCountBolt",new Fields("click"));
LocalCluster lc=new LocalCluster();
lc.submitTopology("window",new Config(),tp.createTopology());
Trident Tutorial
Trident 是构建在Storm之上一个用于实时流处理的高级API(抽象),它允许您无缝地将高吞吐量有状态流处理与低延迟分布式查询混合在一起。Trident支持jion/聚合/分组/函数/过滤算子使用,很优雅将以上算子翻译Toplogy任务,用户无需关心翻译过程.Trident可以保证整个Topology数据处理的一致性并且保证exactly-once语义处理 ,Trident中的核心数据模型是“流”,Trident所有的针对流处理都是批量处理List[Tuple],例如:
[Tupe1,Tupe2,Tupe3,...,Tupen]
|
[Tupe1,Tupe2,Tupe3],[Tupe4,Tupe5,Tupe6] ...
Stream在集群中的节点之间进行分区,并且应用于流的操作跨每个分区并行运行。
Trident和Kafka整合
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>${storm.version}</version>
</dependency>
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String, String> kafkaTridentSpoutOpaque = buildKafkaTridentSpoutOpaque(conf,"topic01");
topology.newStream("kafka",kafkaTridentSpoutOpaque)
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
StormSubmitter.submitTopology("demo01",conf,topology.build());
public static KafkaTridentSpoutOpaque<String,String> buildKafkaTridentSpoutOpaque(Config conf,String topic){
//开启事务控制,否则系统不会提交offset STORM-2675 在1.2.0以前无法正常运行
conf.put(Config.TRANSACTIONAL_ZOOKEEPER_PORT,2181);
conf.put(Config.TRANSACTIONAL_ZOOKEEPER_SERVERS, Arrays.asList(new String[]{"CentOS"}));
//注意如果是1.2.2以前版本存在bug STORM-3064 在1.2.3和2.0.0版本已经修复
String servers="CentOS:9092,CentOS:9093,CentOS:9094";
KafkaSpoutConfig.Builder<String,String> builder=
new KafkaSpoutConfig.Builder<String,String>(servers,topic);
builder.setProp(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
builder.setProp(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
builder.setProp(ConsumerConfig.GROUP_ID_CONFIG,"consumer_id_00");
builder.setRecordTranslator(new DefaultRecordTranslator<String,String>());
//如果消费者第一次消费,则从latest位置,如果不是则从上一次未提交为位置
builder.setFirstPollOffsetStrategy(
KafkaSpoutConfig.FirstPollOffsetStrategy.UNCOMMITTED_LATEST);
//设置offset为手动提交,只有事务提交的时候offset才提交
builder.setProcessingGuarantee(KafkaSpoutConfig.ProcessingGuarantee.AT_LEAST_ONCE);
//如果每个分区中累计达到有2个未提交的Record,系统将停止poll数据
builder.setMaxUncommittedOffsets(2);
return new KafkaTridentSpoutOpaque<String,String>(builder.build());
}
[root@CentOS ~]# storm jar storm-lowlevel-1.0-SNAPSHOT.jar com.jiangzz.demo10.TridentTopologyTests --artifacts ‘org.apache.storm:storm-kafka-client:1.2.3’
或者在项目中添加插件,该插件会将项目依赖的jar包都打包提交。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
Trident API
each
该函数的作用是将流的数据一个个的传递给function处理,这些function分为BaseFunction、BaseFilter
BaseFunction:该函数的作用是给Tuple修改属性。
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String, String> kafkaTridentSpoutOpaque = buildKafkaTridentSpoutOpaque(conf,"topic01");
topology.newStream("kafka",kafkaTridentSpoutOpaque)
.each(new Fields("value"), new BaseFunction() {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String[] token = tuple.getStringByField("value").split("\\W+");
collector.emit(new Values(token[2]));
}
},new Fields("sex"))
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input.getFields()+"\t"+input);
}
});
new LocalCluster().submitTopology("demo01",conf,topology.build());
输入:
1 zhangsan true 12
2 lisi false 25
输出:
1 zhangsan true 12, true
2 lisi false 25, false
BaseFilter:过滤结果,将不满足要求的Tuple移除。
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String, String> kafkaTridentSpoutOpaque = buildKafkaTridentSpoutOpaque(conf,"topic01");
topology.newStream("kafka",kafkaTridentSpoutOpaque)
.each(new Fields("value"), new BaseFilter() {
@Override
public boolean isKeep(TridentTuple tuple) {
return tuple.getStringByField("value").contains("error");
}
})
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input.getFields()+"\t"+input);
}
});
new LocalCluster().submitTopology("demo01",conf,topology.build());
>error hello world
>this is an error messgae
>this is not message
>hello error tests
Map
将Tuple转换为某种形式的Tuple,负责将上游的Tuple转换为新的Tuple,如果不提供Fields,则用户不能修改原有Tuple的元素个数。
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String, String> kafkaTridentSpoutOpaque = buildKafkaTridentSpoutOpaque(conf,"topic01");
topology.newStream("kafka",kafkaTridentSpoutOpaque)
.map(new MapFunction() {
@Override
public Values execute(TridentTuple input) {
String value = input.getStringByField("value");
return new Values(value);
}
},new Fields("value"))
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input.getFields()+"\t"+input);
}
});
new LocalCluster().submitTopology("demo01",conf,topology.build());
flatMap
将一个Tuple转换为多个Tuple。
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String, String> kafkaTridentSpoutOpaque = buildKafkaTridentSpoutOpaque(conf,"topic01");
topology.newStream("kafka",kafkaTridentSpoutOpaque)
.flatMap(new FlatMapFunction() {
@Override
public Iterable<Values> execute(TridentTuple input) {
String[] tokens = input.getStringByField("value").split(" ");
String[] hobbies = tokens[1].split(",");
String user=tokens[0];
List<Values> vs=new ArrayList<Values>();
for (String hobby : hobbies) {
vs.add(new Values(user,hobby));
}
return vs;
}
},new Fields("user","hobby"))
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input.getFields()+"\t"+input);
}
});
new LocalCluster().submitTopology("demo01",conf,topology.build());
project
指定需要获取的filed
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String, String> kafkaTridentSpoutOpaque = buildKafkaTridentSpoutOpaque(conf,"topic01");
topology.newStream("kafka",kafkaTridentSpoutOpaque)
.project(new Fields("partition","offset","value"))
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input.getFields()+"\t"+input);
}
});
new LocalCluster().submitTopology("demo01",conf,topology.build());
partition & partitionAggregate
TridentTopology topology = new TridentTopology();
Config conf = new Config();
topology.newStream("kafka",buildKafkaTridentSpoutOpaque(conf,"topic01"))
.parallelismHint(3)
.flatMap(new FlatMapFunction() {
@Override
public Iterable<Values> execute(TridentTuple input) {
String value = input.getStringByField("value");
String[] words = value.split(" ");
List<Values> vs=new ArrayList<Values>();
for (String word : words) {
vs.add(new Values(word,1));
}
return vs;
}
},new Fields("word","count"))
.partition(new PartialKeyGrouping(new Fields("word")))
.parallelismHint(4)
.partitionAggregate(new Fields("word","count"),new WordCountAggregator(),
new Fields("word","count"))
.each(new Fields("word", "count"), new BaseFilter() {
@Override
public boolean isKeep(TridentTuple tuple) {
return true;
}
})
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
new LocalCluster().submitTopology("demo01",conf,topology.build());
WordCountAggregator计算逻辑
public static class WordCountAggregator extends BaseAggregator<Map<String,Integer>>{
@Override
public Map<String, Integer> init(Object batchId, TridentCollector collector) {
return new HashMap<String,Integer>();
}
@Override
public void aggregate(Map<String, Integer> val, TridentTuple tuple, TridentCollector collector) {
System.out.println("aggregate:"+tuple+"\t"+this+"\t"+val);
String word = tuple.getStringByField("word");
Integer count=tuple.getIntegerByField("count");
if(val.containsKey(word)){
count= val.get(word)+count;
}
val.put(word,count);
}
@Override
public void complete(Map<String, Integer> val, TridentCollector collector) {
for (Map.Entry<String, Integer> entry : val.entrySet()) {
collector.emit(new Values(entry.getKey(),entry.getValue()));
}
val.clear();
}
}
Trident State
Trident以容错方式管理状态,以便在重试和失败时状态更新是幂等的。这使您可以推理Trident拓扑,就好像每条消息都被精确处理一次。在进行状态更新时,可以实现各种级别的容错。
Redis
persistentAggregate
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String,String> kafkaTridentSpoutOpaque=
KafkaSpoutUitls.buildKafkaSpoutOpaque(conf,"topic01");
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder()
.setHost("CentOS")
.setPort(6379)
.build();
Options<OpaqueValue> options=new Options<OpaqueValue>();
options.dataTypeDescription=new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,"mapstate");
options.serializer=new JSONOpaqueSerializer();
topology.newStream("kakfaspout",kafkaTridentSpoutOpaque)
.map((t)-> new Values(t.getStringByField("value")),new Fields("line"))
.flatMap(line->{
String[] words = line.getStringByField("line").split(" ");
List<Values> values=new ArrayList<Values>();
for (String word : words) {
values.add(new Values(word));
}
return values;
},new Fields("word"))
.parallelismHint(3)
.groupBy(new Fields("word"))
.persistentAggregate(RedisMapState.opaque(poolConfig,options),new Fields("word"),new WordCountReducerAggregator(),null);
new LocalCluster().submitTopology("TestTridentDemo",conf,topology.build());
public static class WordCountReducerAggregator implements ReducerAggregator<Long>{
@Override
public Long init() {
return 0L;
}
@Override
public Long reduce(Long curr, TridentTuple tuple) {
return curr+1;
}
}
这里必须注意泛型不能是Integer,必须修改为Long否则重启报错,这算是Storm的一个目前的一个Bug
newStaticState
RedisRetriveStateFactory
public class RedisRetriveStateFactory implements StateFactory {
@Override
public State makeState(Map conf, IMetricsContext metrics, int partitionIndex, int numPartitions) {
return new RedisMapState();
}
}
RedisMapState
public class RedisMapState implements State {
private Jedis jedis=new Jedis("CentOS",6379);
private JSONOpaqueSerializer jsonOpaqueSerializer=new JSONOpaqueSerializer();
@Override
public void beginCommit(Long txid) {
}
@Override
public void commit(Long txid) {
}
public List<Long> batchRetive(List<TridentTuple> args) {
String[] keys=new String[args.size()];
for(int i=0;i<args.size();i++){
keys[i]=args.get(i).getStringByField("word");
}
List<Long> longs=new ArrayList<Long>(args.size());
for (String key : keys) {
String v=jedis.hget("mapstate",key);
if(v!=null){
OpaqueValue opaqueValue = jsonOpaqueSerializer.deserialize(v.getBytes());
long l = Long.parseLong(opaqueValue.getCurr().toString());
longs.add(l);
}else{
longs.add(0L);
}
}
return longs;
}
}
RedisMapStateQueryFunction
public class RedisMapStateQueryFunction implements QueryFunction<RedisMapState,Long> {
@Override
public List<Long> batchRetrieve(RedisMapState state, List<TridentTuple> args) {
return state.batchRetive(args);
}
@Override
public void execute(TridentTuple tuple, Long result, TridentCollector collector) {
collector.emit(new Values(result));
}
@Override
public void prepare(Map conf, TridentOperationContext context) {
}
@Override
public void cleanup() {
}
}
TridentTopologyTests
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String, String> kafkaTridentSpoutOpaque = KafkaSpoutUitls.buildKafkaSpoutOpaque(conf,"topic01");
//自定义State
StateFactory stateFactory = new RedisRetriveStateFactory();
TridentState state = topology.newStaticState(stateFactory);
topology.newStream("kafka",kafkaTridentSpoutOpaque)
.flatMap(new FlatMapFunction() {
@Override
public Iterable<Values> execute(TridentTuple input) {
String[] split = input.getStringByField("value").split(" ");
List<Values> values=new ArrayList<Values>();
for (String s : split) {
values.add(new Values(s));
}
return values;
}
},new Fields("word"))
.stateQuery(state, new Fields("word"),new RedisMapStateQueryFunction(),new Fields("count")).peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
new LocalCluster().submitTopology("demo01",conf,topology.build());
Window
TridentTopology topology = new TridentTopology();
Config conf = new Config();
KafkaTridentSpoutOpaque<String, String> kafkaTridentSpoutOpaque = buildKafkaTridentSpoutOpaque(conf,"topic01");
WindowsStoreFactory wsf=new InMemoryWindowsStoreFactory();
topology.newStream("kafka",kafkaTridentSpoutOpaque)
.project(new Fields("value"))
.flatMap(new FlatMapFunction() {
@Override
public Iterable<Values> execute(TridentTuple input) {
String[] values = input.getStringByField("value").split("\\W+");
List<Values> vs=new ArrayList<Values>();
for (String value : values) {
vs.add(new Values(value,1));
}
return vs;
}
},new Fields("word","count"))
.tumblingWindow(
BaseWindowedBolt.Duration.seconds(10),
wsf,
new Fields("word","count"),
new WordCountAggregator(),
new Fields("word","count")
)
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input.getFields()+"\t"+input);
}
});
new LocalCluster().submitTopology("demo01",conf,topology.build());
WordCountAggregator
public static class WordCountAggregator extends BaseAggregator<TridentToplogyDemo.CountState> {
@Override
public CountState init(Object batchId, TridentCollector tridentCollector) {
return new CountState();
}
@Override
public void aggregate(CountState state, TridentTuple tridentTuple, TridentCollector tridentCollector) {
boolean exits = state.count.containsKey(tridentTuple.getStringByField("word"));
int count=0;
if(exits){
count = state.count.get(tridentTuple.getStringByField("word"));
count=count+1;
}else{
count=1;
}
state.count.put(tridentTuple.getStringByField("word"),count);
}
@Override
public void complete(CountState state, TridentCollector tridentCollector) {
Set<Map.Entry<String, Integer>> entries = state.count.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
tridentCollector.emit(new Values(entry.getKey(),entry.getValue()));
}
}
}
Storm 集群搭建

- 时钟同步
- 安装JDK
- 安装zk集群(正常启动)
- 配置主机名和IP映射关系
- 安装配置Storm
[root@CentOSX ~]# tar -zxf apache-storm-1.2.2.tar.gz -C /usr/
[root@CentOSX ~]# vi .bashrc
`STORM_HOME=/usr/apache-storm-1.2.2`
HBASE_MANAGES_ZK=false
HBASE_HOME=/usr/hbase-1.2.4
HADOOP_HOME=/usr/hadoop-2.6.0
HADOOP_CLASSPATH=/root/mysql-connector-java-5.1.44.jar
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:`$STORM_HOME/bin`
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
export HADOOP_CLASSPATH
export HBASE_HOME
export HBASE_MANAGES_ZK
`export STORM_HOME`
[root@CentOSX ~]# source .bashrc
[root@CentOSX ~]# vi /usr/apache-storm-1.2.2/conf/storm.yaml
storm.zookeeper.servers:
- "CentOSA"
- "CentOSB"
- "CentOSC"
storm.local.dir: "/usr/apache-storm-1.2.2/storm-stage"
nimbus.seeds: ["CentOSA","CentOSB","CentOSC"]
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
drpc.servers:
- "CentOSA"
- "CentOSB"
- "CentOSC"
storm.thrift.transport: "org.apache.storm.security.auth.plain.PlainSaslTransportPlugin"
- 启动 Storm 集群
[root@CentOSA ~]# nohup storm ui >/dev/null 2>&1 &
[root@CentOSX ~]# nohup storm nimbus >/dev/null 2>&1 &
[root@CentOSX ~]# nohup storm supervisor >/dev/null 2>&1 &
[root@CentOSX ~]# nohup storm drpc >/dev/null 2>&1 &
更多精彩内容关注

---------------------
作者:麦田里的守望者·
来源:CSDN
原文:https://blog.csdn.net/weixin_38231448/article/details/89354492
版权声明:本文为作者原创文章,转载请附上博文链接!















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









