







基于视频的行人重识别-01
1.认识mars数据集
研究视频行人重识别基本上都绕不过mars数据集,作为视频行人重识别比较认可的数据集,各个顶刊的优秀论文都是在提高mars数据集的rank。
那么首先,让我们来认识一下这个数据集:
数据集地址
info文件
我们把上面链接中的内容下载下来,然后解压后按照下列这种方式保存:
 那么接下来,解释一下这些文件夹中的内容:
那么接下来,解释一下这些文件夹中的内容:
1.1 bbox_train
bbox_train文件夹中,有625个子文件夹(代表着625个行人id),共包含了8298个小段轨迹(tracklets),总共包含509,914张图片。
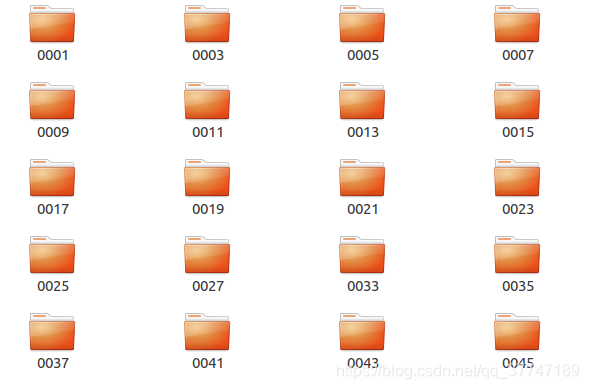 注意一点:这里文件夹的名字不是连续的!
注意一点:这里文件夹的名字不是连续的!
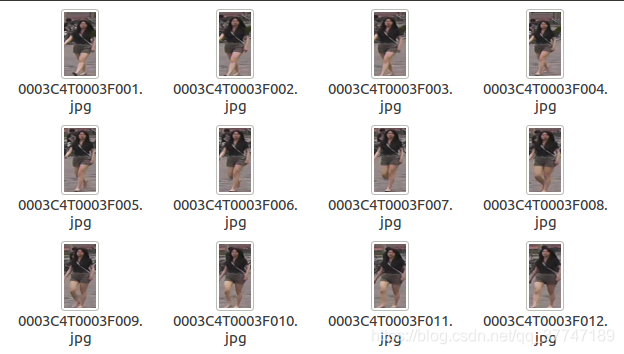
打开任意一个文件夹可以看到这些内容:(文件名后边会解释)
1.2 bbox_test
bbox_test文件夹中共有636个子文件夹(代表着636个行人id),共包含了12180个小段轨迹(tracklets),总共包含681,089张图片。在实验中这个文件夹被划分为图库集(gallery)+ 查询集(query)。在info文件夹中会解释这件事。
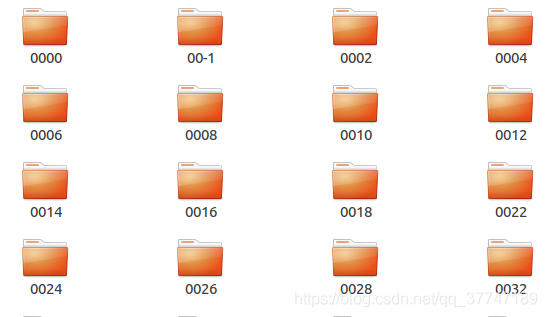 注意也都不是连续的!!!!
注意也都不是连续的!!!!
名称为00-1子文件夹表示无用的图片集,他们对应的行人id被设为**-1**,一般在算法中直接无视pid = -1的图片。

而名称0000子文件夹中,他们对应的行人id被设为0,表示干扰因素,对检索准确性产生负面影响。
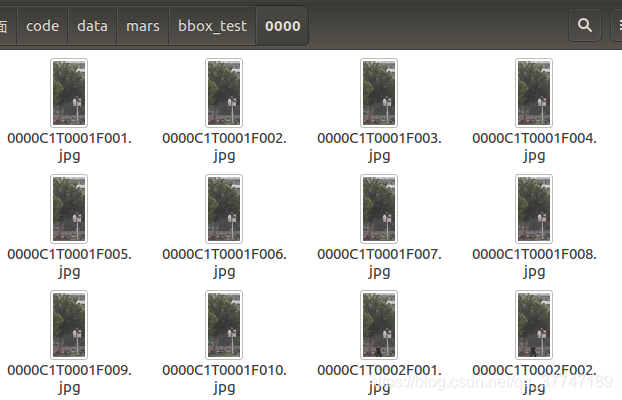
1.3 info
info文件夹中包含了5个子文件,包含了整个数据集的信息,目的是方便使用数据集。
1.3.1 train_name.txt
这个txt文件里,按照顺序存放bbox_train文件夹里所有图片的名称,一共有509,914行(对应509914张图片)。
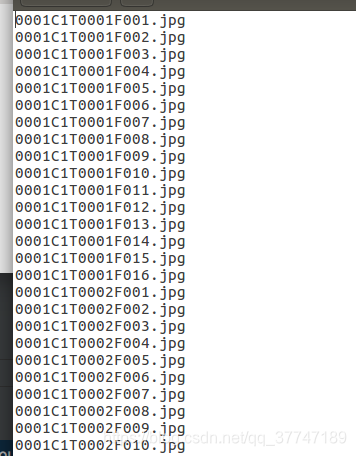 图片名称解释:
图片名称解释:
0001 C1 T0001 F0001.jpg为例。
0001表示的行人的id,也就是 bbox_train文件夹中对应的 0001子文件夹名;
C1表示摄像头的id,说明这张图片是在第1个摄像头下拍摄的(一共有6个摄像头);
T0001表示关于这个行人视频段中的第1个小段视频(tracklet);
F0001表示在这张图片是在这个小段视频(tracklet)中的第1帧。在每个小段视频(tracklet)中,帧数从 F0001开始。
1.3.2 test_name.txt
同样地,在这个txt文件中,按照顺序存放bbox_test文件夹里所有图片的名称,一共有681,089行。
1.3.3 tracks_train_info.mat
.mat格式的文件是matlab保存的文件,用matlab打开后可以看到是一个8298 * 4的矩阵。
矩阵每一行代表着一个tracklet(轨迹);
第一列和第二列代表着图片的序号(开始、结束),这个序号与 train_name.txt文件中的行号一一对应;
第三列是行人的id,也就是 bbox_train文件夹中对应的 子文件夹名;
第4列是对应的摄像头id(一共有6个摄像头)。
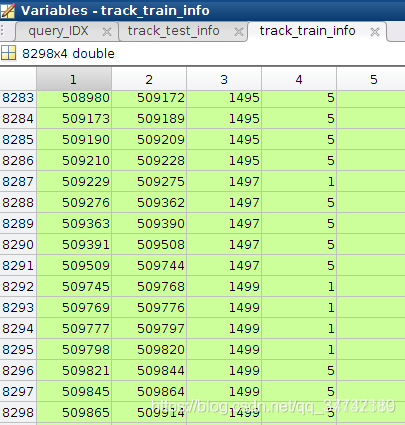
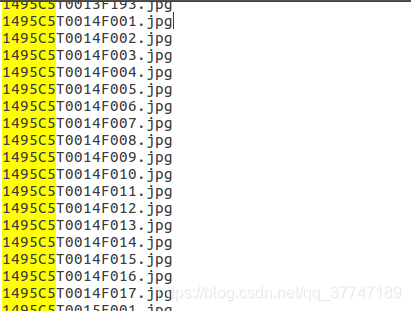 注意对照两张图片~
注意对照两张图片~
1.3.4 tracks_train_info.mat
这个文件用matlab打开后可以看到是一个12180 * 4的矩阵。
矩阵每一行代表着一个tracklet;
第一列和第二列代表着图片的序号,这个序号与 test_name.txt 文件中的行号一一对应;
第三列是行人的id,也就是 bbox_test文件夹中对应的 子文件夹名;;
第4列是对应的摄像头id(一共有6个摄像头)。
和上面的类似~
1.3.5 query_IDX.mat
这个文件用matlab打开后可以看到是一个1 * 1980的矩阵(挑了1980个查询id),可以看到每一列是对应上面 tracks_test_info.mat文件中的第几行。
比如1978列中的值为12177,对应的是 tracks_test_info.mat文件中的第12177行(一行对应一个tracks)。
而12177行中,可以看到其id=1496(行人id)。不难发现同样id=1496的行还有12166, 12167等(一个行人对应了多段轨迹)。
其实这说明在 名称为1496子文件夹中(行人id为1496),有多个小段视频(tracklet)。
值得注意的是, 并不是所有查询集的id,图库都有对应的相同id行人的行。在1980个查询id中,有效的id(在图库中存在相同id的行)数 = 1840。
也就是说,有些文件夹里只有1个tracklet。

1.4 总结
总的来说 :
- 一个训练集会对应多个行人id,一个id会对应多个tracks,一个tracks又对应着多张图片。
- 训练集和测试级没有重复的行人id
- 测试集中挑选的部分作为query
2.mars数据集管理data_manager
前面介绍行人重识别的时候,也同样有这一部分,目地在于把硬盘中的mars数据集,封装到dataset中。
方法大多数都相同,就直接贴代码了:
# 导入相关包
from __future__ import print_function, absolute_import
import os
import glob
import re
import sys
import urllib
import tarfile
import zipfile
import os.path as osp
from scipy.io import loadmat
import numpy as np
import random
from utils.util import mkdir_if_missing, write_json, read_json
"""Dataset classes"""
# 定义类方法
class Mars(object):
"""
MARS
Reference:
Zheng et al. MARS: A Video Benchmark for Large-Scale Person Re-identification. ECCV 2016.
Dataset statistics:
# identities: 1261
# tracklets: 8298 (train) + 1980 (query) + 9330 (gallery)
# cameras: 6
Args:
min_seq_len (int): tracklet with length shorter than this value will be discarded (default: 0).
"""
# 设置mars路径 这个要根据自己文件夹中存放数据集的位置
root = '/home/user/桌面/code/data/mars'
# 读取对应文件夹路径
train_name_path = osp.join(root, 'info/train_name.txt')
test_name_path = osp.join(root, 'info/test_name.txt')
track_train_info_path = osp.join(root, 'info/tracks_train_info.mat'< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









