







 本文介绍了如何使用Azure云的语音合成API和开源项目PaddleSpeech,让AI不仅能理解文本,还能生成语音并支持语音情感和角色定制。同时,讨论了语音合成技术的应用和不同工具的性能比较。
本文介绍了如何使用Azure云的语音合成API和开源项目PaddleSpeech,让AI不仅能理解文本,还能生成语音并支持语音情感和角色定制。同时,讨论了语音合成技术的应用和不同工具的性能比较。
上一讲里,我们通过 Whisper 模型,让 AI“听懂”了我们在说什么。我们可以利用这个能力,让 AI 替我们听播客、做小结。不过,这只是我们和 AI 的单向沟通。那我们能不能更进一步,让 AI 不仅能“听懂”我们说的话,通过 ChatGPT 去回答我们问的问题,最后还能让 AI 把这些内容合成为语音,“说”给我们听呢?
当然可以,这也是我们这一讲的主题,会带你一起来让 AI 说话。和上一讲一样,不仅会教你如何使用云端 API 来做语音合成(Text-To-Speech),也会教你使用开源模型,给你一个用本地 CPU 就能实现的解决方案。这样,你也就不用担心数据安全的问题了。
使用 Azure 云进行语音合成
语音合成其实已经是一个非常成熟的技术了,现在在很多短视频平台里,你听到的很多配音其实都是通过语音合成技术完成的。国内外的各大公司都有类似的云服务,比如科大讯飞、阿里云、百度、AWS Polly、Google Cloud等等。不过,今天我们先来体验一下微软 Azure 云的语音合成 API。选用 Azure,主要有两个原因。
1. 因为微软和 OpenAI 有合作,Azure 还提供了 OpenAI 相关模型的托管。这样,我们在实际的生产环境使用的时候,只需要和一个云打交道就好了。
2. 价格比较便宜,并且提供了免费的额度。如果你每个月的用量在 50 万个字符以内,那么就不用花钱。
在运行代码之前,需要先去注册一个 Azure 云的账号,并且开通微软认知服务,然后开启对应的认知服务资源,获得自己的 API Key。在这里放了对应文档的链接,照着文档一步步操作,就能完成。在下面也放上了关键步骤的截图,具体注册过程,就不一一介绍了。
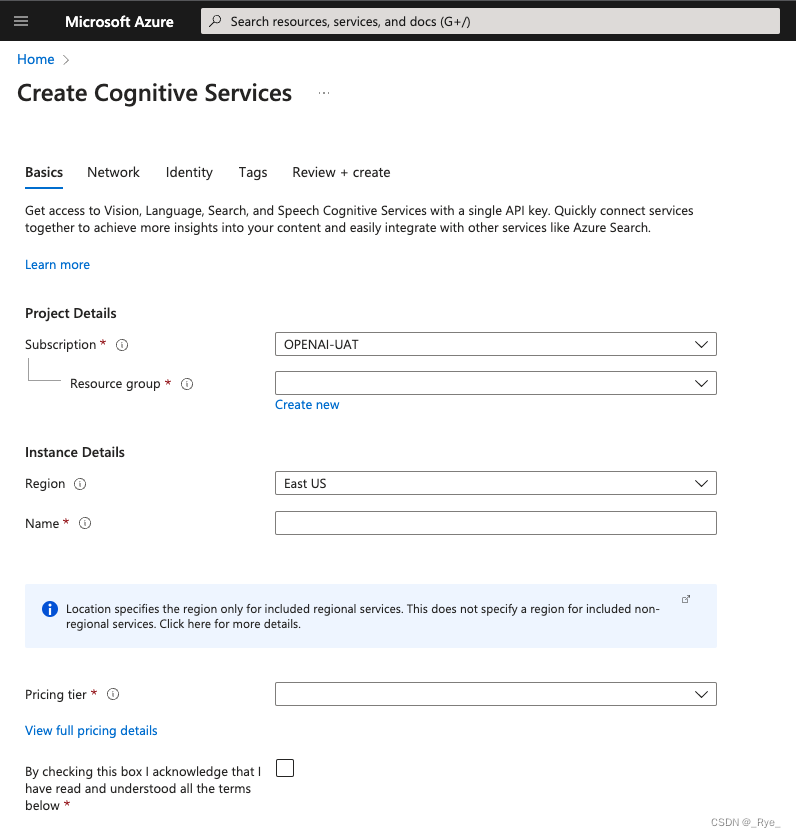
注:我选择了 East US 区域,因为这个区域也可以部署 OpenAI 的 ChatGPT 服务。

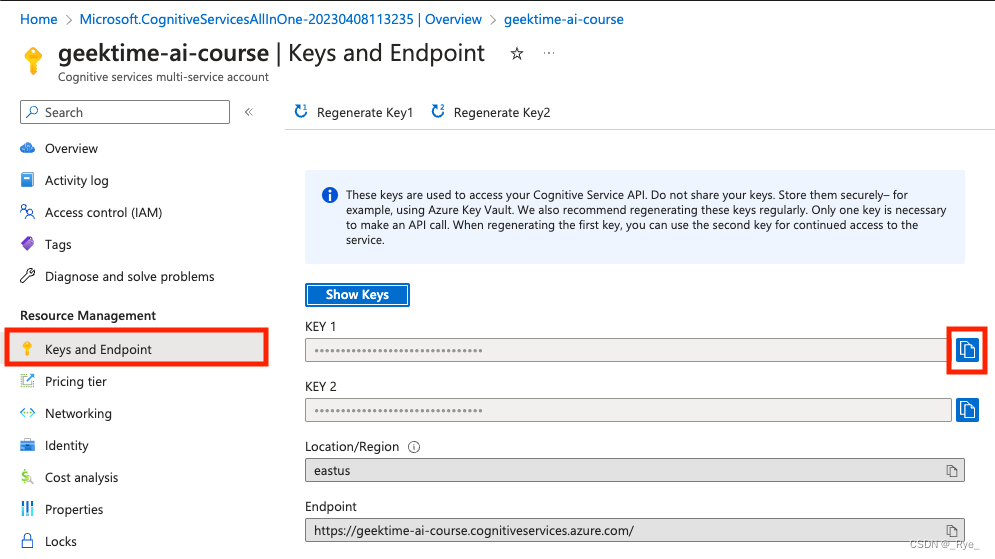
在拿到 API Key 之后,还是建议你把 API Key 设置到环境变量里面。避免你使用 Notebook 或者撰写代码的时候,不小心把自己的 Key 暴露出去,被别人免费使用。同样的,我们也在环境变量里设置一下我们使用的 Azure 服务的区域 eastus。
export AZURE_SPEECH_KEY=YOUR_API_KEY
export AZURE_SPEECH_REGION=eastus当然,也不要忘了安装对应的 Python 包
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4386
4386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









