







在专栏上一期中,我们谈了 Kafka 当前的定位问题,Kafka 不再是一个单纯的消息引擎系统,而是能够实现精确一次(Exactly-once)处理语义的实时流处理平台。
你可能听说过 Apache Storm、Apache Spark Streaming 抑或是 Apache Flink,它们在大规模流处理领域可都是响当当的名字。令人高兴的是,Kafka 经过这么长时间的不断迭代,现在已经能够稍稍比肩这些框架了。我在这里使用了“稍稍”这个字眼,一方面想表达 Kafka 社区对于这些框架心存敬意;另一方面也想表达目前国内鲜有大厂将 Kafka 用于流处理的尴尬境地,毕竟 Kafka 是从消息引擎“半路出家”转型成流处理平台的,它在流处理方面的表现还需要经过时间的检验。
如果我们把视角从流处理平台扩展到流处理生态圈,Kafka 更是还有很长的路要走。前面我提到过 Kafka Streams 组件,正是它提供了 Kafka 实时处理流数据的能力。但是其实还有一个重要的组件我没有提及,那就是 Kafka Connect。
我们在评估流处理平台的时候,框架本身的性能、所提供操作算子(Operator)的丰富程度固然是重要的评判指标,但框架与上下游交互的能力也是非常重要的。能够与之进行数据传输的外部系统越多,围绕它打造的生态圈就越牢固,因而也就有更多的人愿意去使用它,从而形成正向反馈,不断地促进该生态圈的发展。就 Kafka 而言,Kafka Connect 通过一个个具体的连接器(Connector),串联起上下游的外部系统。
整个 Kafka 生态圈如下图所示。值得注意的是,这张图中的外部系统只是 Kafka Connect 组件支持的一部分而已。目前还有一个可喜的趋势是使用 Kafka Connect 组件的用户越来越多,相信在未来会有越来越多的人开发自己的连接器。
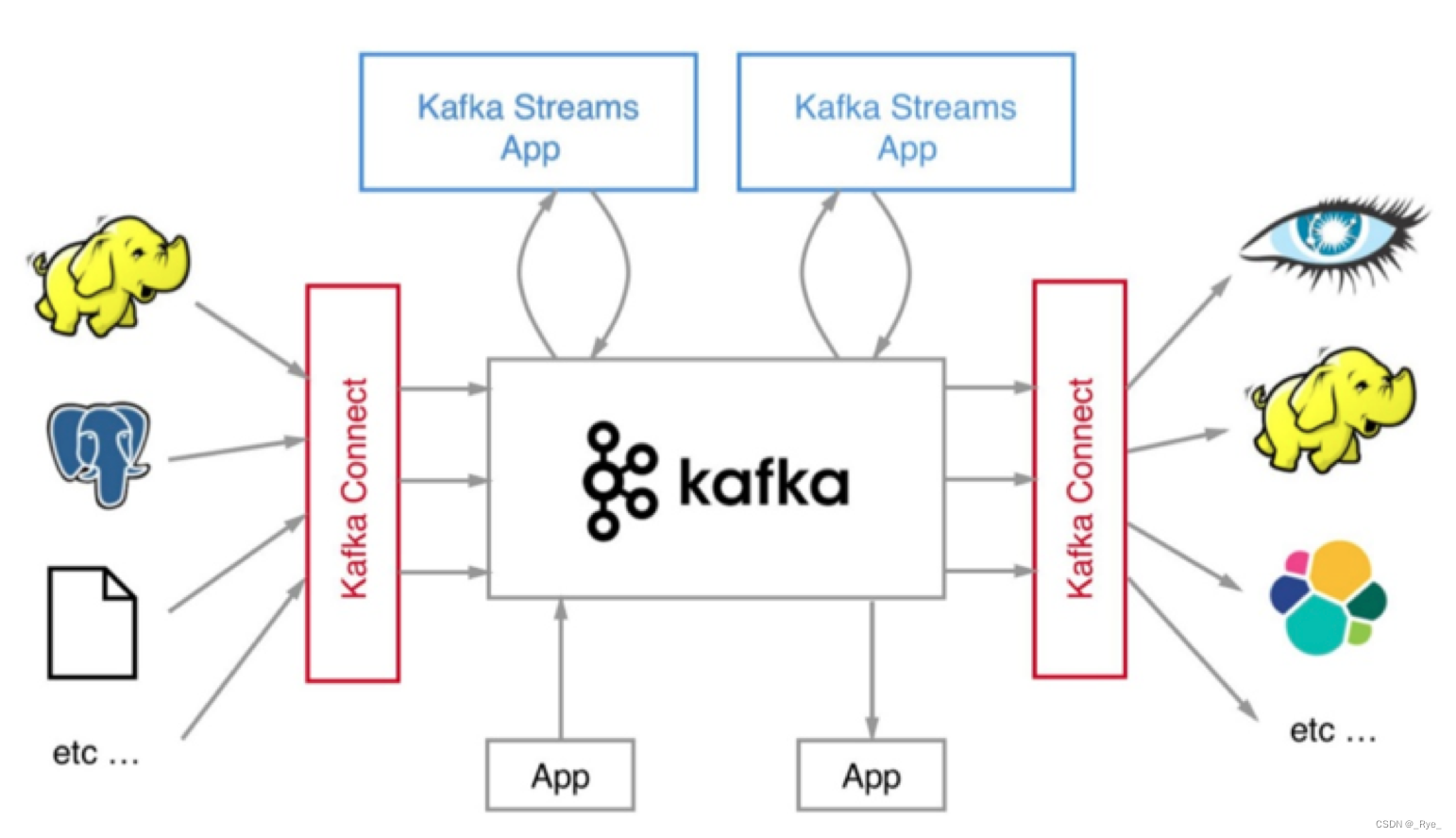
说了这么多你可能会问这和今天的主题有什么关系呢?其实清晰地了解 Kafka 的发展脉络和生态圈现状,对于指导我们选择合适的 Kafka 版本大有裨益。下面我们就进入今天的主题——如何选择 Kafka 版本?
你知道几种 Kafka?
咦? Kafka 不是一个开源框架吗,什么叫有几种 Kafka 啊? 实际上,Kafka 的确有好几种,这里我不是指它的版本,而是指存在多个组织或公司发
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









