










目录
开篇寄语
气如云气,自我纵横。
天地洞明,万物可兵。
魔方导读
目标检测(Object Detection)是计算机视觉四大基本任务之一,目的是解决“是什么,在哪里”的问题。作为图像理解和计算机视觉的基石,目标检测是解决图像分割、目标追踪、视频内容理解、图像描述和行为识别等更复杂更高阶的视觉任务的基础。因此,本文整理了目标检测发展二十多年来的优秀算法,包括基于深度学习的Anchor-free、One-stage和Two-stage等目标检测方法。通过本文可快速了解目标检测的发展脉络及相关领域算法!!!
由魔方智能CV空间调研、整理、创作或转载,如有侵权,请联系后台作相应处理!!
往期回顾:
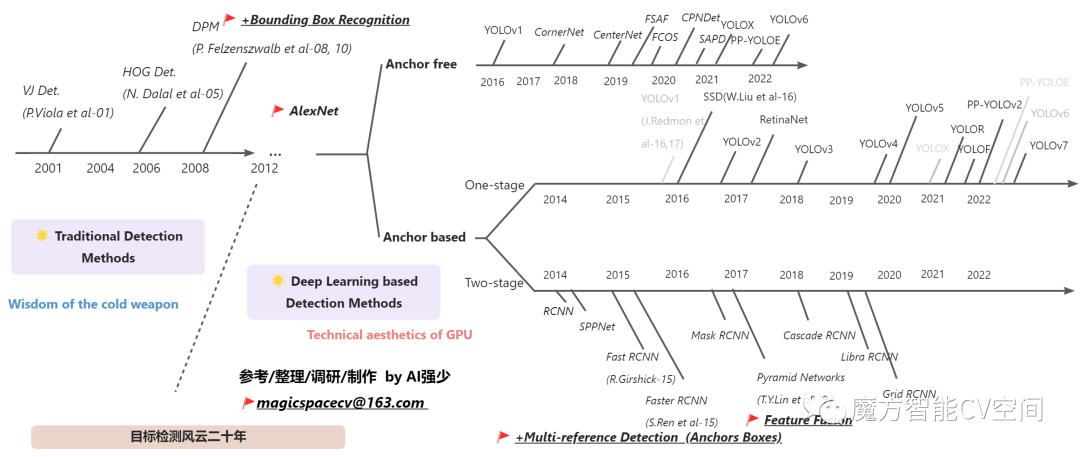
以2012年作为分水岭,目标检测在过去二十多年的发展过程中可大致分为两个时期:传统目标检测方法与基于深度学习的目标检测方法。传统的目标检测方法的代表作主要有三个:Viola Jones Detectors、HOG Detector、Deformable Part-based Model(DPM),在这里不进行过多介绍,接下来重点汇总基于深度学习的目标检测方法。
Anchor-free目标检测算法
1.1 YOLOv1
论文:《You Only Look Once: Unified, Real-Time Object Detection》
论文链接:https://arxiv.org/pdf/1506.02640.pdf
代码链接:https://github.com/AlexeyAB/darknet
参考:https://zhuanlan.zhihu.com/p/364367221
【简介】
(1)以当前视角看,YOLOv1是One-stage开山之作,同时也是最早的Anchor-free通用检测器;
(2)因其简洁的网络结构和GPU实时检测速度而一鸣惊人;
(3)最大特点:仅使用一个卷积神经网络端到端地实现物体检测,打破了R-CNN的“垄断”地位,为目标检测领域带来了巨大的变革!
(4)核心思想:就是在每个网格上做预测,如果某物体的Ground Truth中心点坐标落入到某个格子,那么这个格子就负责检测出这个物体。
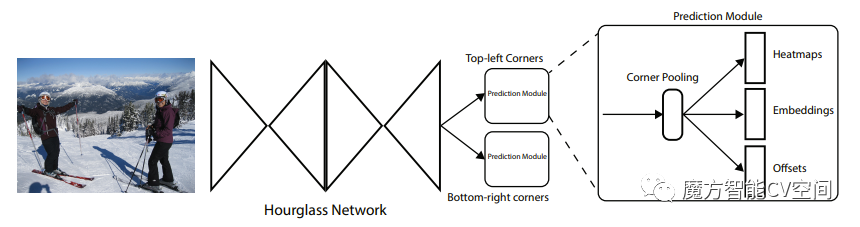
1.2 CornerNet
论文:《CornerNet: Detecting Objects as Paired Keypoints》
论文链接:https://arxiv.org/abs/1808.01244
代码链接:https://github.com/princeton-vl/CornerNet
【简介】
(1)将目标检测问题当作关键点检测问题来解决;
(2)通过检测bounding box的左上角和右下角两个关键点得到预测框;
(3)CornerNet算法中没有Anchor的概念;
(4)整个检测网络的训练是从头开始的,不受预训练模型的限制.
1.3 CenterNet
论文:《Objects as Points》
论文链接:https://arxiv.org/pdf/1904.07850.pdf
代码链接:https://github.com/xingyizhou/CenterNet
【简介】
传统目标检测将物体定义为沿着坐标轴的边界框,对所有可能的物体进行穷举搜索,再进行分类。这种方法耗时耗力,且需要额外的后处理过程。本文将物体建模为单个点——BBox的中心点,用关键点估计找到中心点,并且回归输出物体其他属性,如:尺寸,3D位置,旋向,甚至位姿。本文方法称为CenterNet,一种端到端具有多种优点的目标检测方法,达到了速度与准确率的平衡.
1.4 FSAF
论文:《Feature Selective Anchor-Free Module for Single-Shot Object Detection》
论文链接:https://arxiv.org/pdf/1903.00621v1.pdf
代码链接:https://github.com/xuannianz/FSAF
【简介】
我们激励并提出功能选择性Anchor-free(FSAF)模块,这是一种简单有效的单点目标检测器构建块。可以将其插入具有特征金字塔结构的单发检测器。FSAF模块解决了传统基于锚的检测带来的两个限制:1)启发式引导特征选择; 2)基于重叠的锚点采样。FSAF模块的一般概念是在线特征选择,用于选择多级Anchor-free分支。具体地,Anchor-free分支附接到特征金字塔的每个级别,从而允许以任意锚的Anchor-free方式进行盒编码和解码。在训练过程中,我们会为每个实例动态分配最合适的功能级别。在推理时,FSAF模块可以通过并行输出预测与基于Anchor的分支共同工作。我们通过Anchor-free分支的简单实现和在线特征选择策略来实例化此概念。在COCO检测的实验结果表明,我们的FSAF模块比Anchor-based的模块性能更好,同时速度更快。当与Anchor-based的分支联合使用时,FSAF模块在各种设置下都大幅提高了基线RetinaNet,同时引入了几乎免费的推理开销。最终得到的最佳模型可以达到44.6%的最新mAP,优于COCO上所有现有的单激发检测器。
1.5 FCOS
论文:《FCOS: Fully Convolutional One-Stage Object Detection》
论文链接:https://arxiv.org/pdf/1904.01355v5.pdf
代码链接:https://github.com/tianzhi0549/FCOS/
【简介】
(1)最大优势不需要先验框,大大降低了样本量和参数量,计算量也大大降低;
(2)对于小目标检测的效果也不错,通过多尺度检测,增加可以预测的框的数;
(3)最大创新在于center-ness模块,这是其区别于YOLOv1的主要部分。
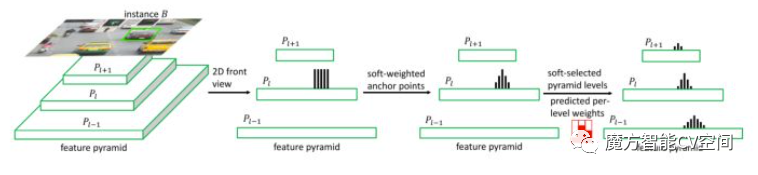
1.6 SAPD
论文:《Soft Anchor-Point Object Detection》
论文链接:https://arxiv.org/pdf/1911.12448v2.pdf
代码链接:https://github.com/xuannianz/SAPD
【简介】
(1)针对anchor-point检测算法的优化问题,论文提出了SAPD方法;
(2)对不同位置的anchor point使用不同损失权重,并且对不同特征金字塔层进行加权共同训练,去除大部分人为制定的规则,更加遵循网络本身的权值进行训练。
One-Stage目标检测算法
1.1 YOLOv1
论文:《You Only Look Once: Unified, Real-Time Object Detection》
论文链接:https://arxiv.org/pdf/1506.02640.pdf
代码链接:https://github.com/AlexeyAB/darknet
【YOLOv1的缺点】
(1)每个cell只预测两个bbox和一个类别,这限制了能预测重叠或邻近物体的数量,比如当两个物体的中心点都落在这个cell中,但这个cell只能预测一个类别;
(2)不像Faster R-CNN一样预测offset,YOLOv1是直接预测bbox的位置,这就增加了训练的难度;
(3)YOLOv1是根据训练数据来预测bbox的,当测试数据中的物体出现了训练数据中物体没有的长宽比时,YOLOv1的泛化能力低;
(4)经过多次下采样,最终得到的feature的分辨率比较低,可能会影响到物体的定位;
(5)损失函数的设计存在缺陷,使得物体的定位误差有点大,尤其在不同尺寸大小的物体处理上还有待加强。
1.2 SSD
论文:《SSD: Single Shot MultiBox Detector》
论文链接:https://arxiv.org/pdf/1512.02325v5.pdf
代码链接:https://github.com/weiliu89/caffe/tree/ssd
【简介】
(1)SSD是一个One-stage的统一目标检测框架;
(2)SSD 网络模型的特征提取网络是改进 VGG16 网络而来的,通过在 VGG16 网络后面增加几组卷积层增大小特征的特征图;
(3)利用不同尺度的特征图进行目标的检测,经过 SSD 网络特征提取后,会得到两个尺度的特征图,用两个尺度中较大的识别小目标,而较小的识别大目标,提高小目标的识别准确率。

1.3 YOLOv2
论文:《YOLO9000:Better, Faster, Stronger》
论文链接:https://arxiv.org/pdf/1612.08242v1.pdf
代码地址:https://github.com/AlexeyAB/darknet
参考:https://zhuanlan.zhihu.com/p/124269512
【简介】
(1)在YOLOv1基础上,进行了大量改进,提出了YOLOv2和YOLO9000,重点解决YOLOv1召回率和定位精度方面的不足;
(2)是一个先进的目标检测算法,比它之前的算法检测速度更快。同时可以适应多种尺寸的图片输入,并且能在精度和速度之间进行很好的权衡;
(3)借鉴了Faster R-CNN的思想,引入Anchor机制,利用K-means聚类的方法在训练集中聚类计算出更好的Anchor模板,大大提高了算法的召回率;
(4)结合图像细粒度特征,将浅层和深层特征相连,有助于对小目标的检测;
(5)YOLO9000 使用 WorldTree 来混合不同资源的训练数据,并使用联合优化技术在ImageNet和COCO数据集上进行训练,能够实时地检测超9000种物体。
1.4 RetinaNet
论文:《Focal Loss for Dense Object Detection》
论文链接:https://arxiv.org/pdf/1708.02002v2.pdf
代码链接:
https://github.com/facebookresearch/detectron
【简介】
(1)该论文最大贡献在于提出了Focal Loss用于解决类别不均衡的问题,从而创造了RetinaNet;
(2)精度上超越Two-stage网络,在速度上超越one-stage网络的速度,首次实现一阶段网络对二阶段网络的全面超越;
(3)产生精度差异的主要原因:类别失衡(Class Imbalance);
(4)Focal loss的目的:消除类别不均衡+挖掘难例样本。
1.5 YOLOv3
论文:《YOLOv3: An Incremental Improvement》
论文链接:https://arxiv.org/pdf/1804.02767v1.pdf
代码链接:https://pjreddie.com/darknet
【简介】
(1)创新点:a.新的网络结构Darknet-53;b.融合FPN;c.用逻辑回归替代softmax作为分类器;
(2)“分而治之”,从YOLOv1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样;
(3)采用**“leaky ReLU”**作为激活函数;
(4)从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后;
(5)多尺度训练,在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。

1.6 YOLOv4
论文:《YOLOv4: Optimal Speed and Accuracy of Object Detection》
论文链接:https://arxiv.org/pdf/2004.10934v1.pdf
代码链接:https://github.com/AlexeyAB/darknet
【简介】
(1)构建了一个简单且高效的目标检测模型,降低了训练门槛;
(2)验证了先进的Bag-of-Freebies和Bag-of-Specials方法在训练期间的影响;
(3)修改了最先进的方法,并且使其更为有效,适合单GPU训练,包括CBN、PAN、SAM等,从而使得YOLOv4能够在一块GPU上就可以训练起来。
1.7 YOLOv5
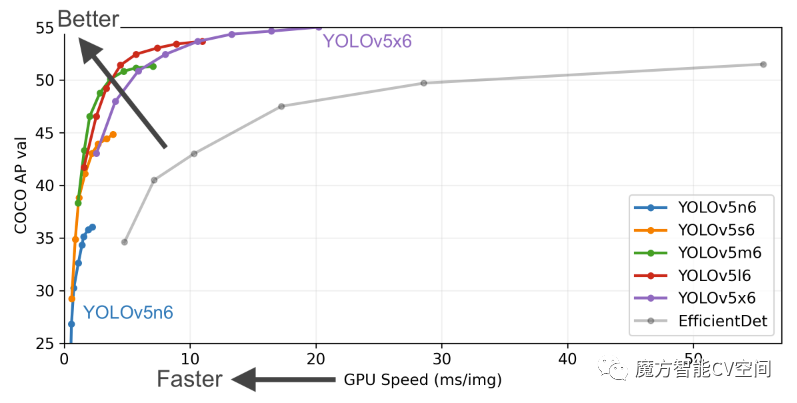
代码链接:https://github.com/ultralytics/yolov5
【特点】
(1)考虑了邻域的正样本Anchor匹配策略,增加了正样本;
(2)通过灵活的配置参数,可以得到不同复杂度的模型;
(3)通过一些内置的超参数优化策略,提升整体性能;
(4)和yolov4一样,都用了Mosaic增强,提升小物体的检测性能。
1.8 YOLOX
论文:《YOLOX: Exceeding YOLO Series in 2021》
论文链接:https://arxiv.org/pdf/2107.08430v2.pdf
代码链接:
https://github.com/Megvii-BaseDetection/YOLOX
【简介】
(1)本论文中介绍了YOLO系列的一些经验改进,形成了一个新的高性能检测器——YOLOX;
(2)将YOLO检测器切换为Anchor-free并进行其他先进的检测技术**,即decoupled head** 和领先的标签分配策略 SimOTA,以在大量模型中实现最先进的结果。
(3)支持ONNX、TensorRT、NCNN和OpenVINO**的部署版本。
1.9 PP-YOLOE
论文:《PP-YOLOE: An evolved version of YOLO》
论文链接:https://arxiv.org/pdf/2203.16250v2.pdf
代码链接:
https://github.com/PaddlePaddle/PaddleDetection
【简介】
(1)首先PP-YOLOE-l 在COCO数据集上达到了51.4mAP。相比较PP-YOLOv2提升1.9AP和13.35%的速度,相比较YOLOX提升1.3AP和24.96%的速度;
(2)主要的改进点是:anchor-free,powerful backbone and neck,TAL动态label assign,ET-head。
1.10 YOLOv6
技术文章【官方】:
https://mp.weixin.qq.com/s/RrQCP4pTSwpTmSgvly9evg
代码链接:https://github.com/meituan/YOLOv6
【简介】
美团视觉智能部在目标检测框架方面的优化及实践经验,针对 YOLO 系列框架,在训练策略、主干网络、多尺度特征融合、检测头等方面进行了思考和优化,设计了新的检测框架YOLOv6,初衷来自于解决工业应用落地时所遇到的实际问题。
1.11 YOLOv7
论文:《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》
论文链接:https://arxiv.org/pdf/2207.02696v1.pdf
代码链接:https://github.com/wongkinyiu/yolov7
Two-Stage目标检测算法
1.1 R-CNN
论文:《Rich feature hierarchies for accurate object detection and semantic segmentation》
论文链接:https://arxiv.org/pdf/1311.2524v5.pdf
代码链接:https://github.com/rbgirshick/rcnn
【简介】
(1)RCNN****是Two-stage算法的开山之作**,奠定了一个基础,大大提高了目标检测的效果;
(2)RCNN包含了三个主要的模块:
a. 生成类别独立的regoin proposal(区域建议),为感知器定义候选区域;
b. CNN提取固定长度的特征;
c. 线性SVM分类器进行类别的分类
1.2 Fast R-CNN
论文:《Fast R-CNN》
论文链接:https://arxiv.org/pdf/1504.08083v2.pdf
代码链接:https://github.com/rbgirshick/fast-rcnn
1.3 Faster R-CNN
论文:《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
论文链接:https://arxiv.org/pdf/1506.01497v3.pdf
代码链接:https://github.com/rbgirshick/py-faster-rcnn


















 3903
3903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









