







词表示
把自然语言中最基本的语言单元——词转换为机器能够理解的
词表示能完成以下两个能力

词相似度计算
词与词之间语义的关系
近义词&上位词

使用近义词或上位词表示的问题

遗漏差异
遗漏新的释义
带有主观性
数据吸收
需要大量人工构建
One-Hot Representation
常用的,把每个词表示成一个独立的符号
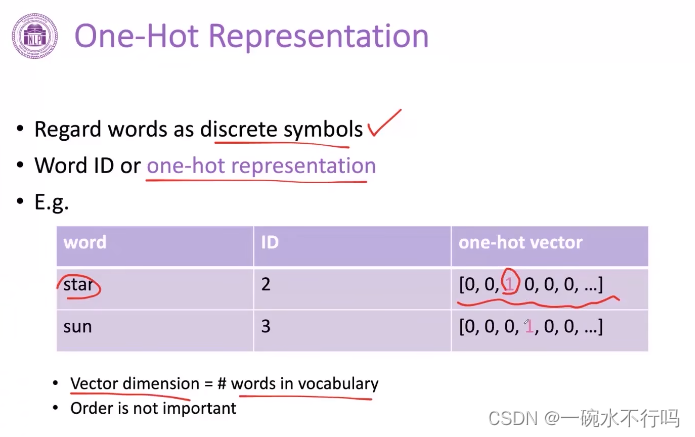
One-Hot Representation的问题
假设词与词之间的向量是正交的,所以任意两个词进行相似的计算都等于零

represent word by context
为了解决上面的问题,所谓的contextual representation 上下文表示
利用这个词的上下文来表示这个词,例如:要表示下图中的star,从上下文中找出一些词shining\cold\night

Co-Occurrence Counts
使用向量,表示的是这个词的上下文到底出现了多少次
得到上下文(词)的稠密的向量,在这个空间里,利用稠密的向量计算词之间的相似度

Co-Occurrence Counts的问题
词表变得越来越大,存储的需求也就变得特别大
对于出现频度特别少的词,它的上下文或者语境的词变得很稀疏,影响对词的表示效果

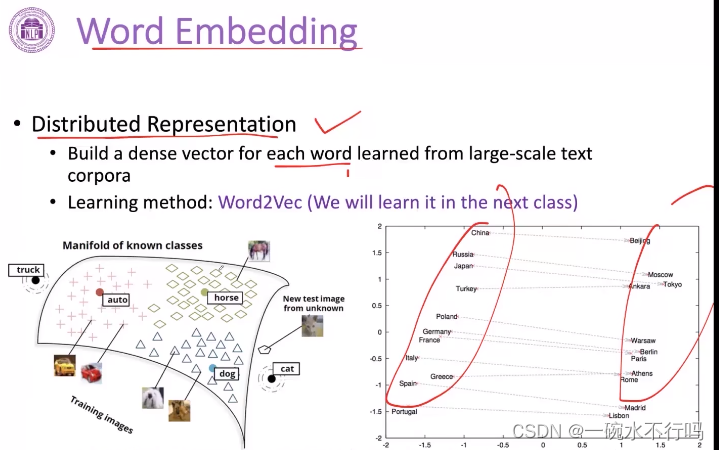
Word Embedding
分布式表示
建立起一个低维的稠密的向量空间,把每个词都学到这个空间里面,用这个空间里面的某一个位置所对应的向量来表示词。在这个空间里,就可以自动得学习出来一些国家和首都存在一些相对稳定的关系(见下图)。这种低维向量,可以利用大规模的数据自动去学习的。
代表性工作:Word2Vec
NLP Basic Language Modeling
语言模型:能有能力根据前文去预测下一个词到底是什么
机器能够学习语言模型,就能更好理解词的意思,也能更好地做出回复

语言模型的能力:
1.去计算一个序列的词成为一句话的概率是多大(联合概率)
2.根据前面的句子,预测下面要说的话

如何达到上面的能力:
假设:未来的词只会受到前面词的影响
一个句子的联合概率等于前面已经出现的词的条件概率之积

如何进行语言模型的构建?
N-gram Model
对 language model一个具体的建模
统计前面出现了几个词之后,后面出现的那个词的频度

N-gram背后大致遵守markov的假设:
一个联合概率,只考虑前面有限的几个词

N-gram的问题
1.在实际使用中,一般只使用N等于1或2,没有考虑更长的上下文
2.没有办法误理解这些词之间的相似度

Neural Languge Model
分布式表示,来建构这种前文和当前词的预测条件概率
















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









