






目录
1 词表示:
1.1 词表示含义:
把人类的词表示为机器所能理解的词。
1.2 词表示目标:
- 计算词之间的相似度;
- 揭示词之间的关系。

1.3 表示词的词义的方法:
1.3.1 用一组相关的同义词(上位词):

缺点:可能有些词之间有非常细微的差异;错失新的词义(需要人工进行标注);存在主观性;数据稀疏;需要大量人工。
1.3.2 独热表示法:

缺点:
- 当词库中的词数量非常多时,会造成“维度灾难”。
- 任意两个词向量是正交的,计算出的相似度都是0,也即无法度量词语之间的相似性。
1.3.3 用上下文的词间接表示:
统计词在文章中出现的频数,然后通过频数进行计算得到相似度
缺点:存储需求大;对于频率少的词可能会产生稀疏问题。
1.3.4 词嵌入:
将每一个词都用一个词向量表示,然后映射到一个向量空间中,这样子向量空间中的每个点都可以表示一个词。
2 语言模型:
2.1 语言模型的含义:
有能力根据前文去预测下一个词是什么。
2.2 所要具备的两个能力:
- 计算多个词组合在一起成为一个合法句子的概率(词的联合概率)
- 根据前文去预测下一个词是什么(词的条件概率)
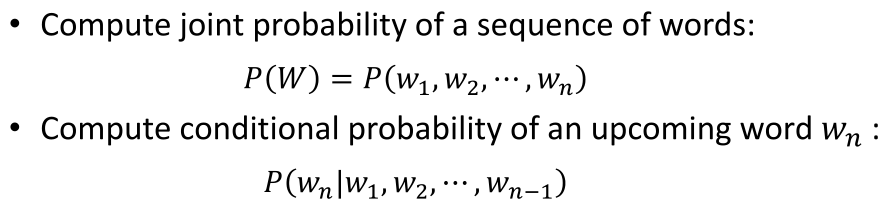
2.3 联合概率和条件概率的关系:
假设前提:一个词出现的概率只会受到他前面出现的词的影响(马尔可夫假设)。

2.4 N-gram模型:
计算下一个词可能出现的概率,在一个大规模数据集中进行统计频次,计算公式如下:

N=2->Bigram; N=3->Trigram
缺点:N一般只能选取2或者3;没有办法识别词之间的相似度(语法、语义)。
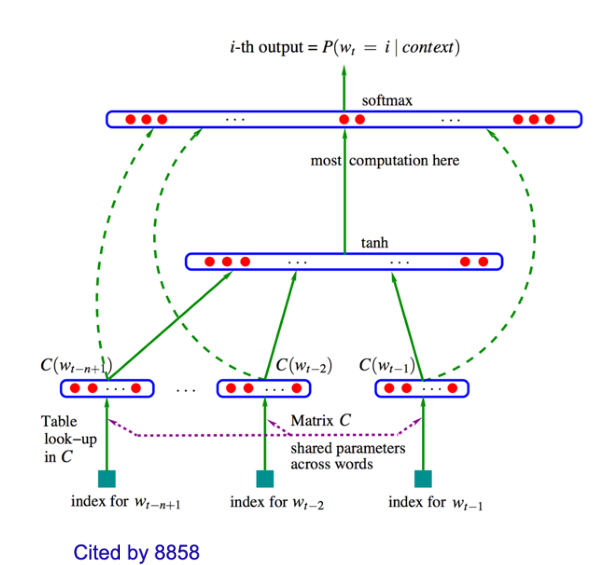
2.5 Neural模型:
不同于N-gram模型直接将词作为一个符号来看,在Neural模型中,每个词都被抽象为一个具体的低维向量,相似的词对应的向量也会比较相似。(可以运用大数据文本去对向量的权重进行不断调整)















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









