







知识拓展-python与统计学
1.Descriptive statistics 描述性统计
2.Inferential statistics 推断性统计:步骤如下:
sample样本(sample statistic样本统计) --sampling抽样(estimate估计)–> 总体population(parameter参数)
1)sampling 先抽样
2)estimate 然后估计:
- 1.Point estimation
- 例如:想了解一个学校学生的身高情况,就可以随机抽取一部分学生测量他们的身高,得到一个平均值,再用这个样本的均值去估计整体学生的身高情况,就是点估计
- 2.Confidence interval
- 区间估计就是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减估计误差得到。 另外一种说法,区间估计是从点估计值和抽样标准误差出发,按给定的概率值建立包含待估参数的区间,这个给定的概率值称为置信度或置信水平,这个建立起来的包含待估计参数的区间称为置信区间。 置信区间是根据样本信息推导出来的可能包含总体参数的数值区间,置信水平表示置信区间的可信度;例如某学校学生的平均身高的区间估计:有95%的置信水平可以认为该校学生的平均身高为1.4米到1.5米之间,(1.4,1.5)为置信区间,95%是置信水平,即有95%的信心认为这个区间包含该校学生的平均身高。
3)Hypothesis test 最后假设检验
- 区间估计就是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减估计误差得到。 另外一种说法,区间估计是从点估计值和抽样标准误差出发,按给定的概率值建立包含待估参数的区间,这个给定的概率值称为置信度或置信水平,这个建立起来的包含待估计参数的区间称为置信区间。 置信区间是根据样本信息推导出来的可能包含总体参数的数值区间,置信水平表示置信区间的可信度;例如某学校学生的平均身高的区间估计:有95%的置信水平可以认为该校学生的平均身高为1.4米到1.5米之间,(1.4,1.5)为置信区间,95%是置信水平,即有95%的信心认为这个区间包含该校学生的平均身高。

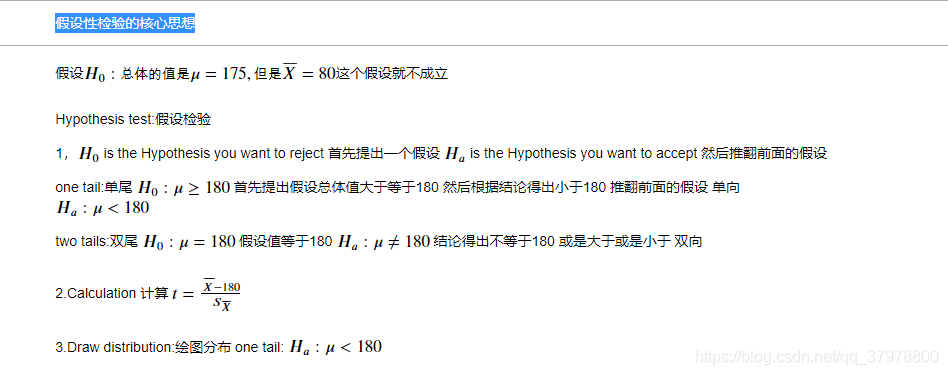
假设性检验的核心思想
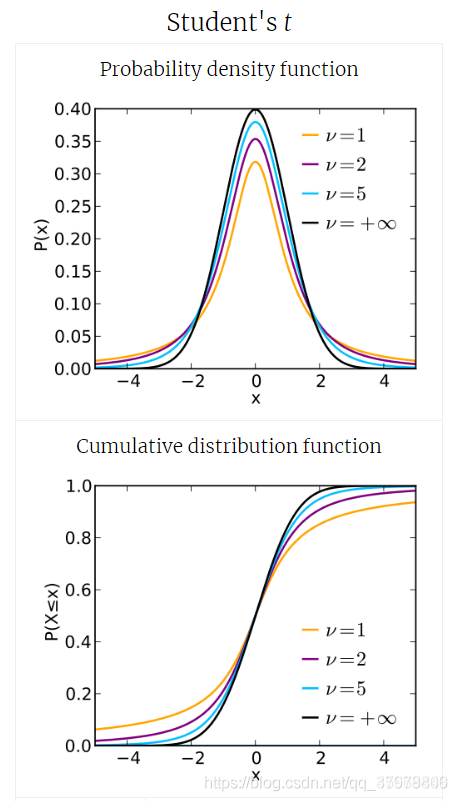
有偏与无偏估计
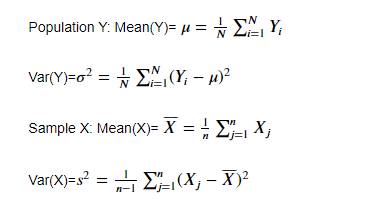
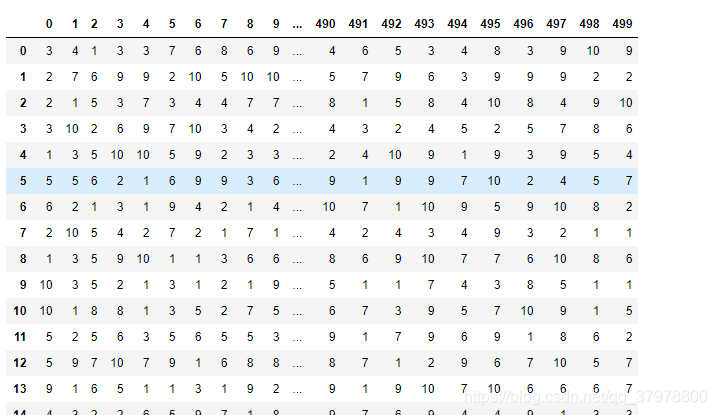
## 随机生成1-10的数字生成10万个
%matplotlib inline
import matplotlib.pyplot as plt
from IPython.core.pylabtools import figsize
figsize(15,5)
import pandas as pd
import numpy as np
np.random.seed(42)
# The population N's size is 100000
N=100000
population = pd.Series(np.random.randint(1,11,N)) # 随机生成1-10的数字生成N个
print(population)

# 模拟数据抽样
samples={}
# The size of each sample 每个样本的大小
n=30
# We are going to draw 500 times of samples and each time ,we are going to take 30 of samples.我们将抽取500次样品,每次抽取30个样品。
num_of_samples= 500
for i in range(num_of_samples):
samples[i]= population.sample(n).reset_index(drop=True)
samples=pd.DataFrame(samples) # 放入datafram中
samples
# (Delta degree of freedom) ddof=0 diveded by n ddof=1 divided by n-1
biased_samples=samples.var(ddof=0).to_frame() # ddof=0
biased_samples

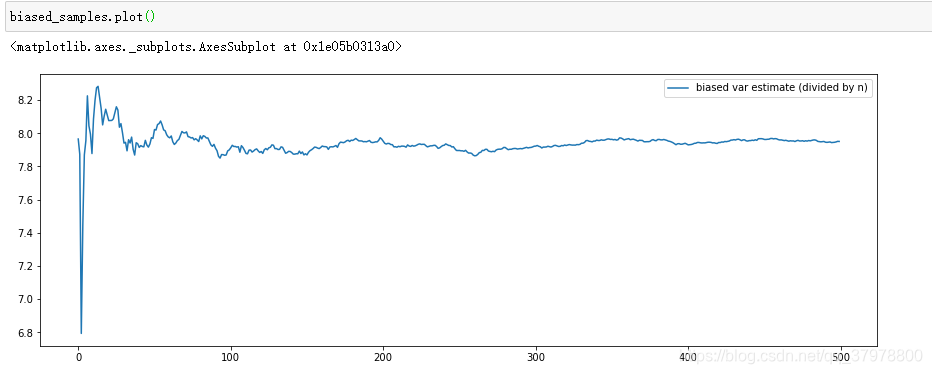
biased_samples=biased_samples.expanding().mean() # 有偏
biased_samples
biased_samples.columns=["biased var estimate (divided by n)"]
biased_samples
unbiased_sample=samples.var(ddof=1).to_frame()#无偏
unbiased_sample
unbiased_sample=unbiased_sample.expanding().mean()
unbiased_sample
unbiased_sample.columns=["unbiased var estimate(divided by n-1)"]
unbiased_sample
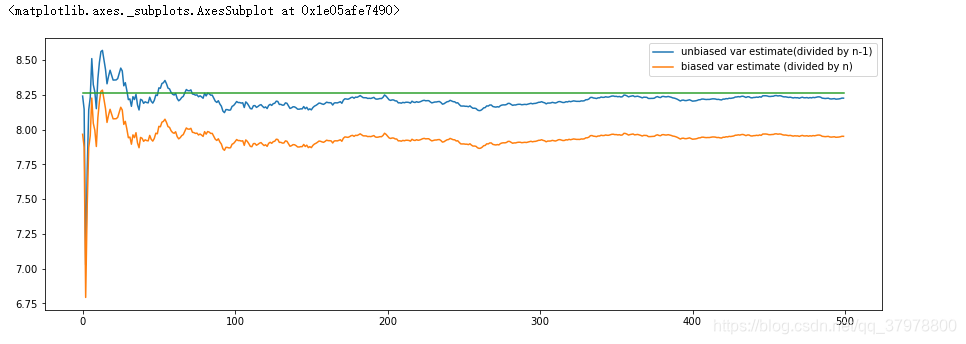
ax=unbiased_sample.plot()
biased_samples.plot(ax=ax)
real_population_variance=pd.Series(population.var(ddof=0),index=samples.columns)
real_population_variance.plot()

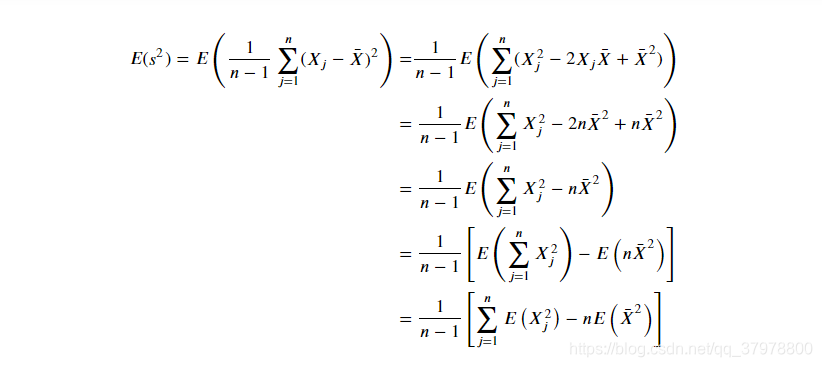
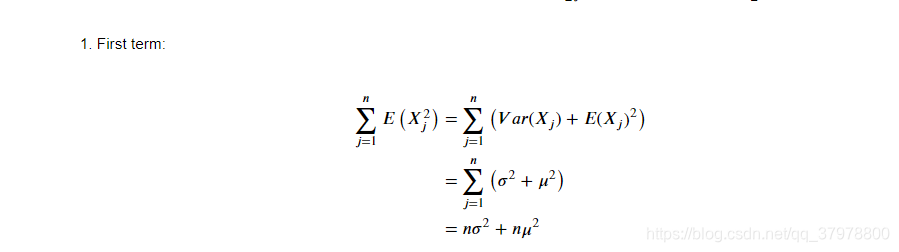

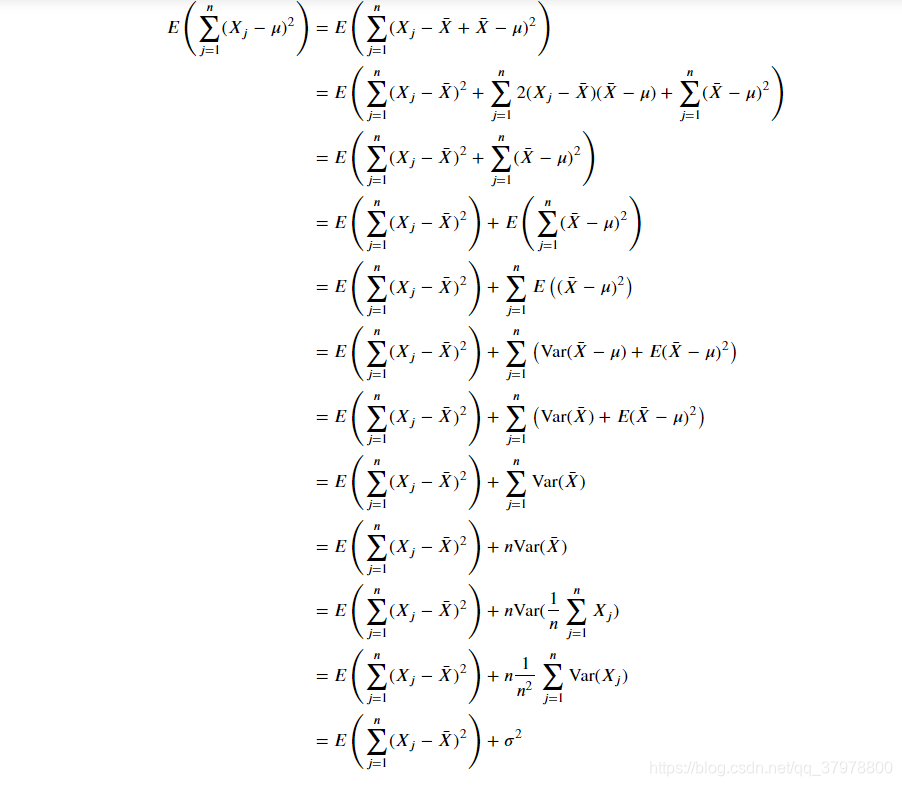
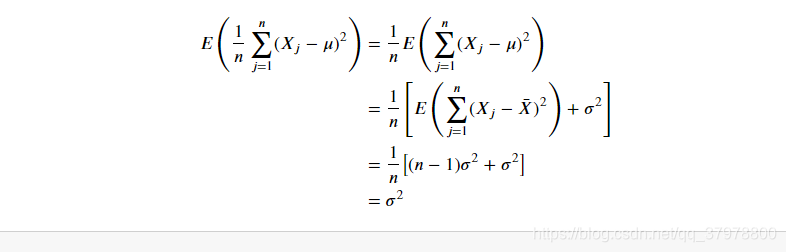















 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









