







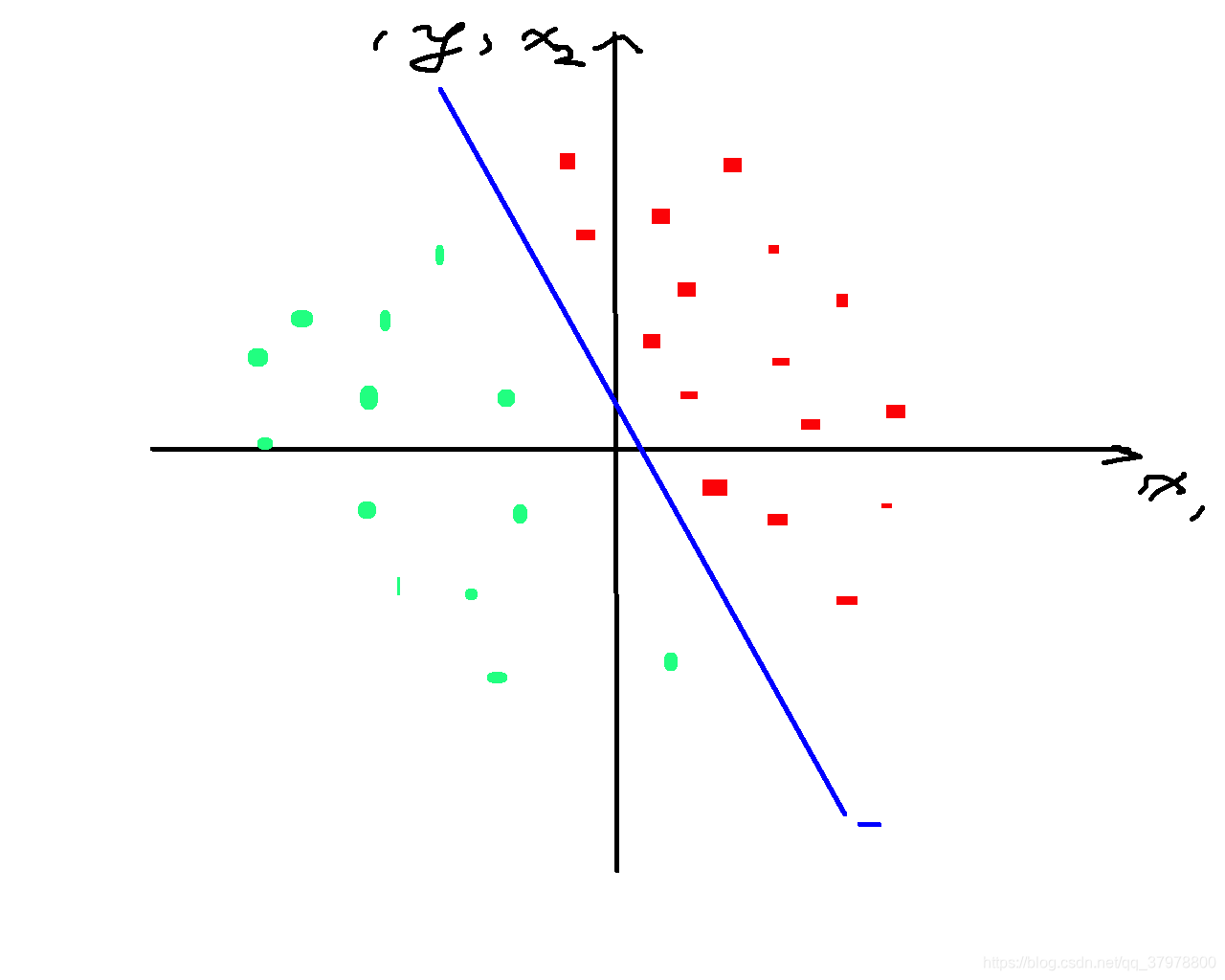
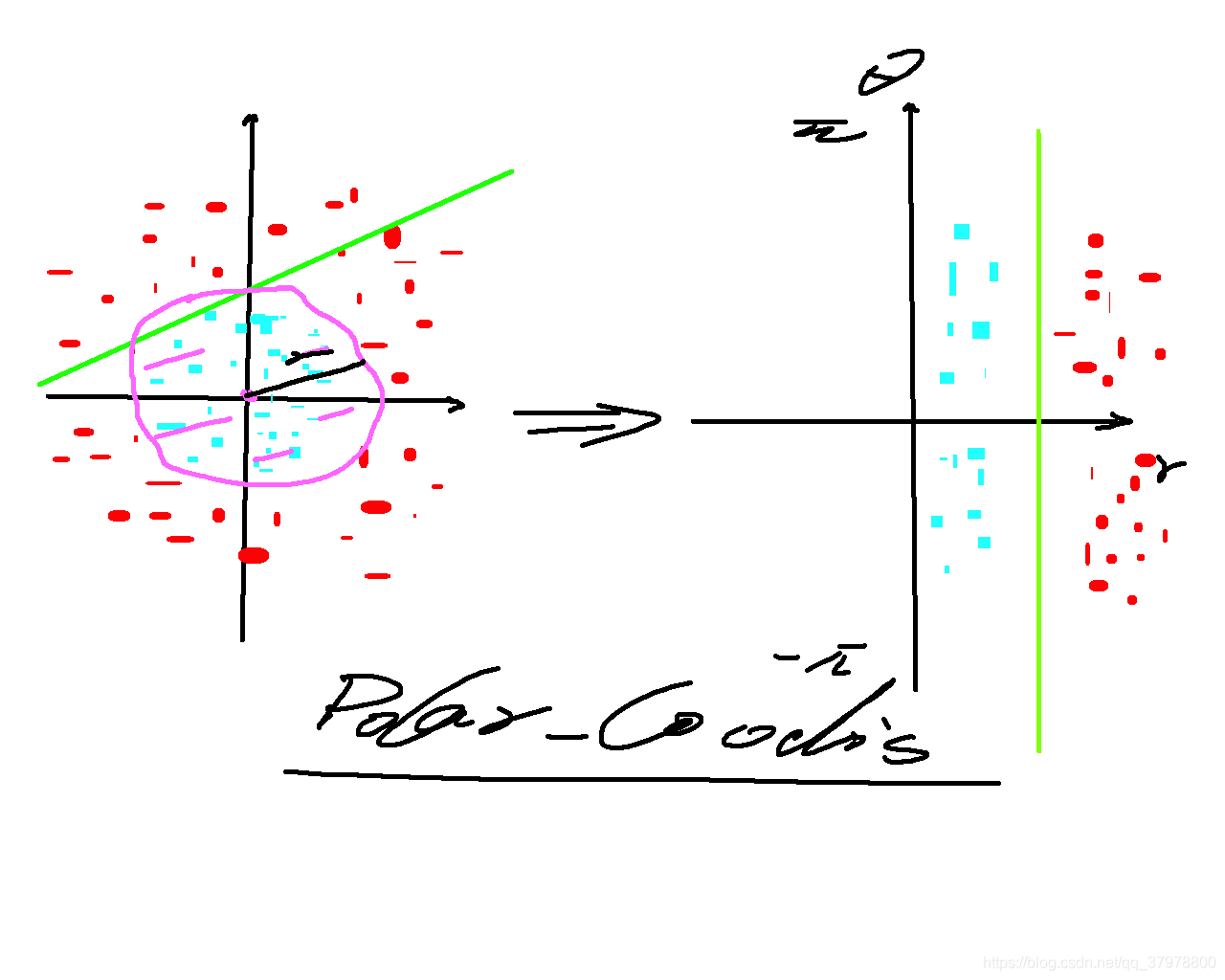
如下图给定的一组数据可以通过一条线分割成两个不同的类别称之为Linearly_Separable
如下图有明显特征但是不能通过线性进行切分称为线性不可分
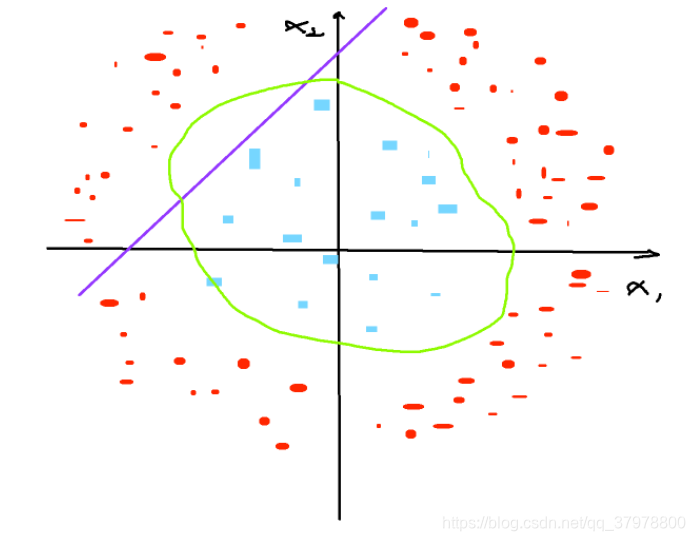
我们可以在拿到数据后进行基本的判断,然后确定是否使用感知器方法解决(必须是可以Linearly_Separable)
建模思想就是IO与Para优化(调参)

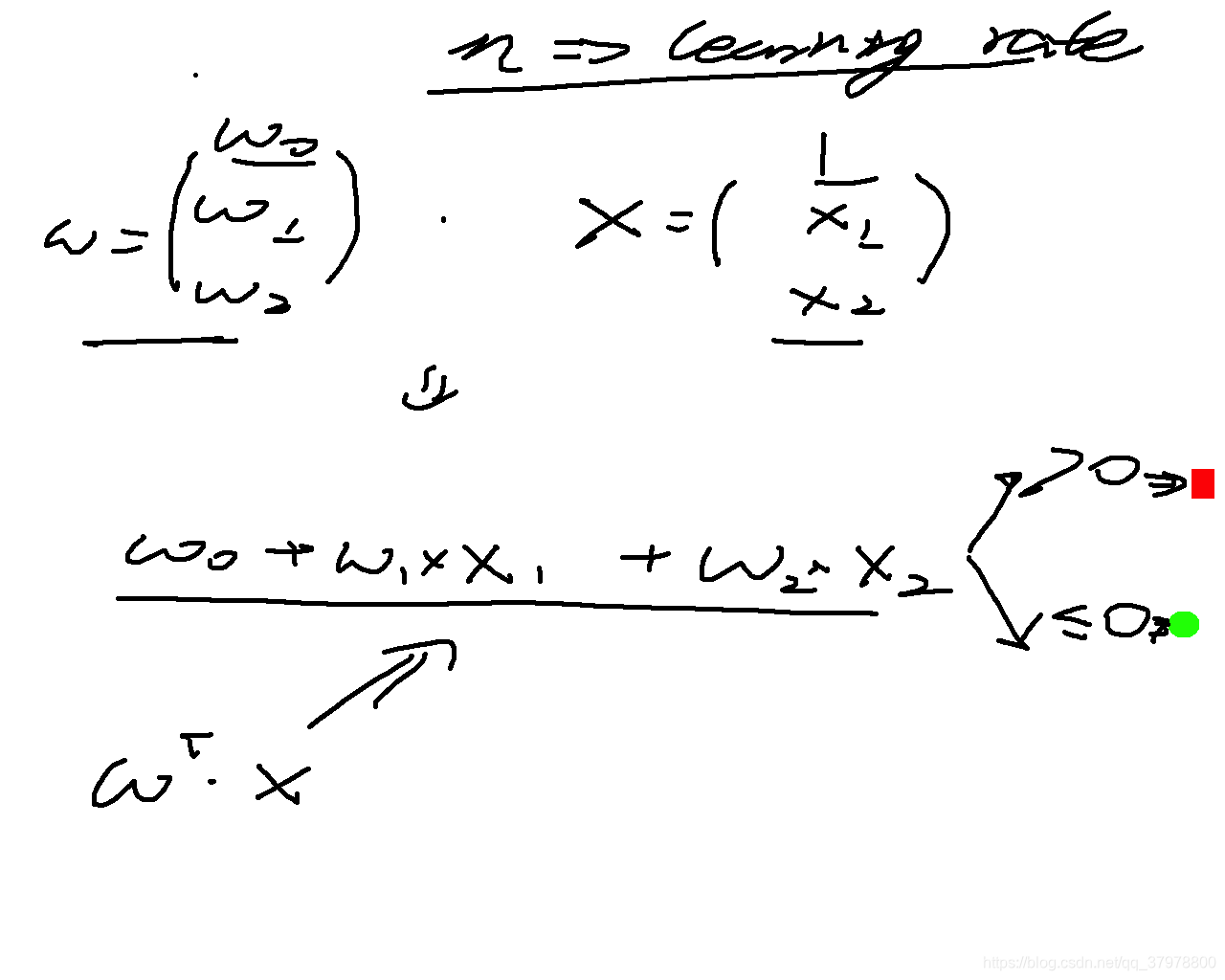
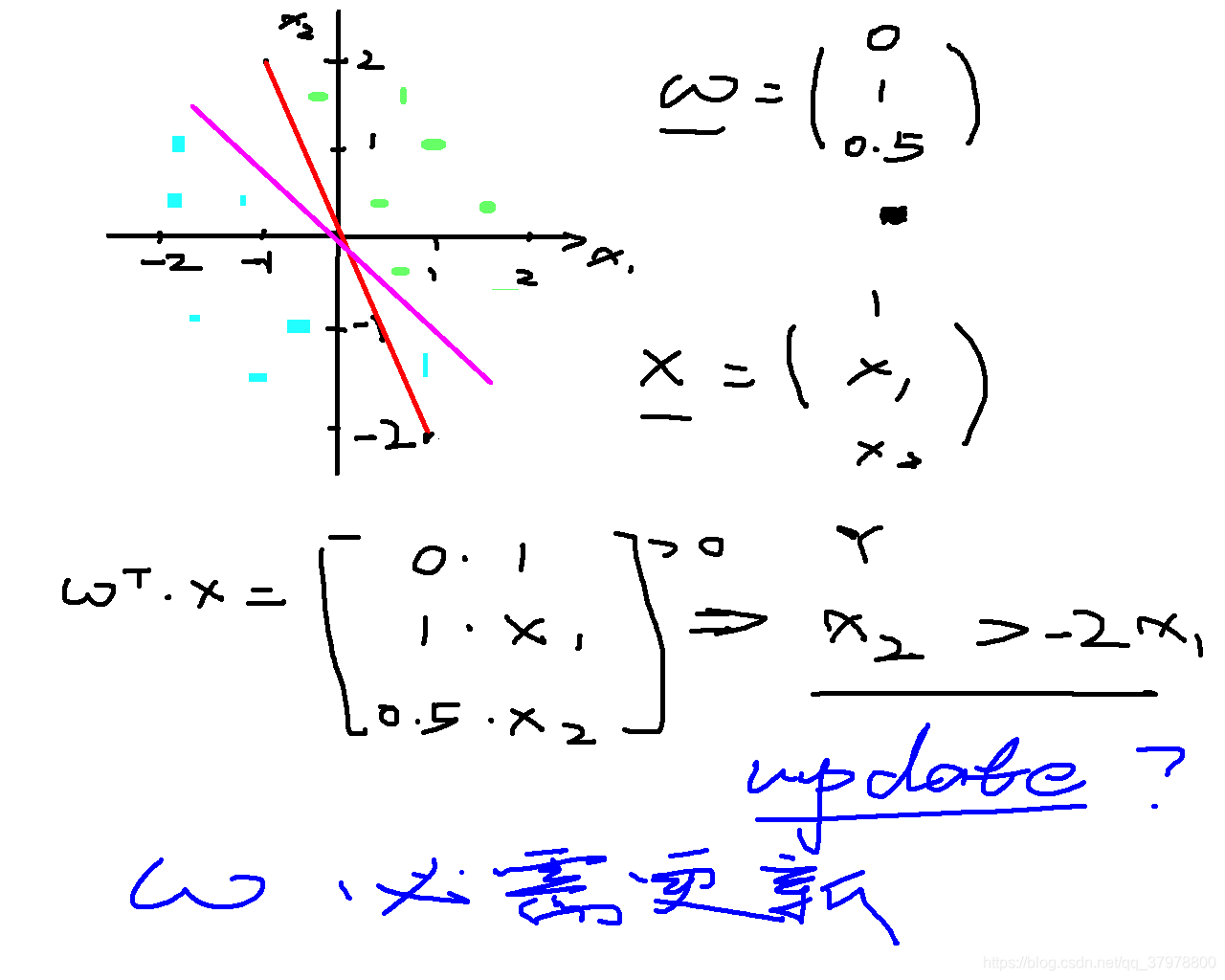

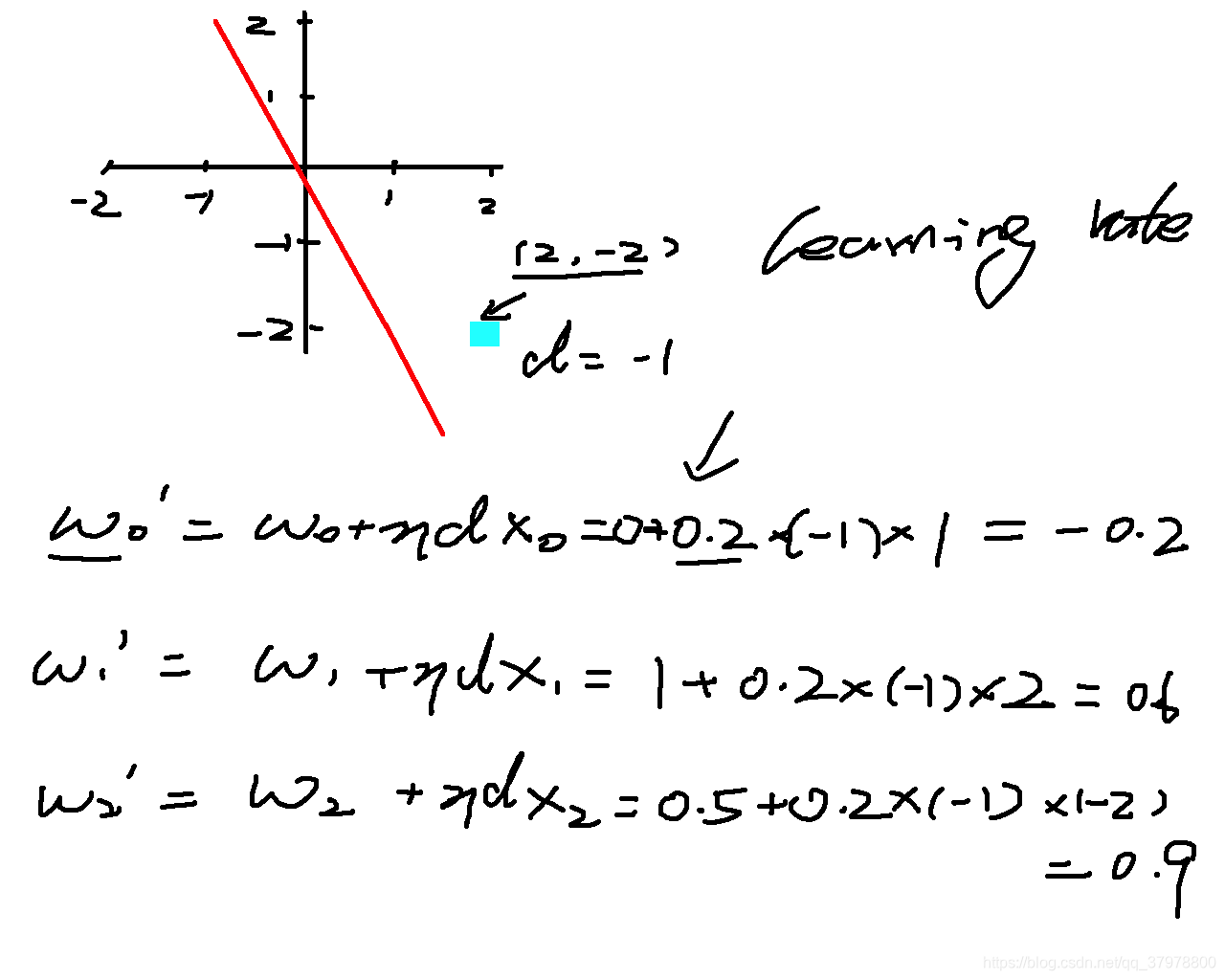
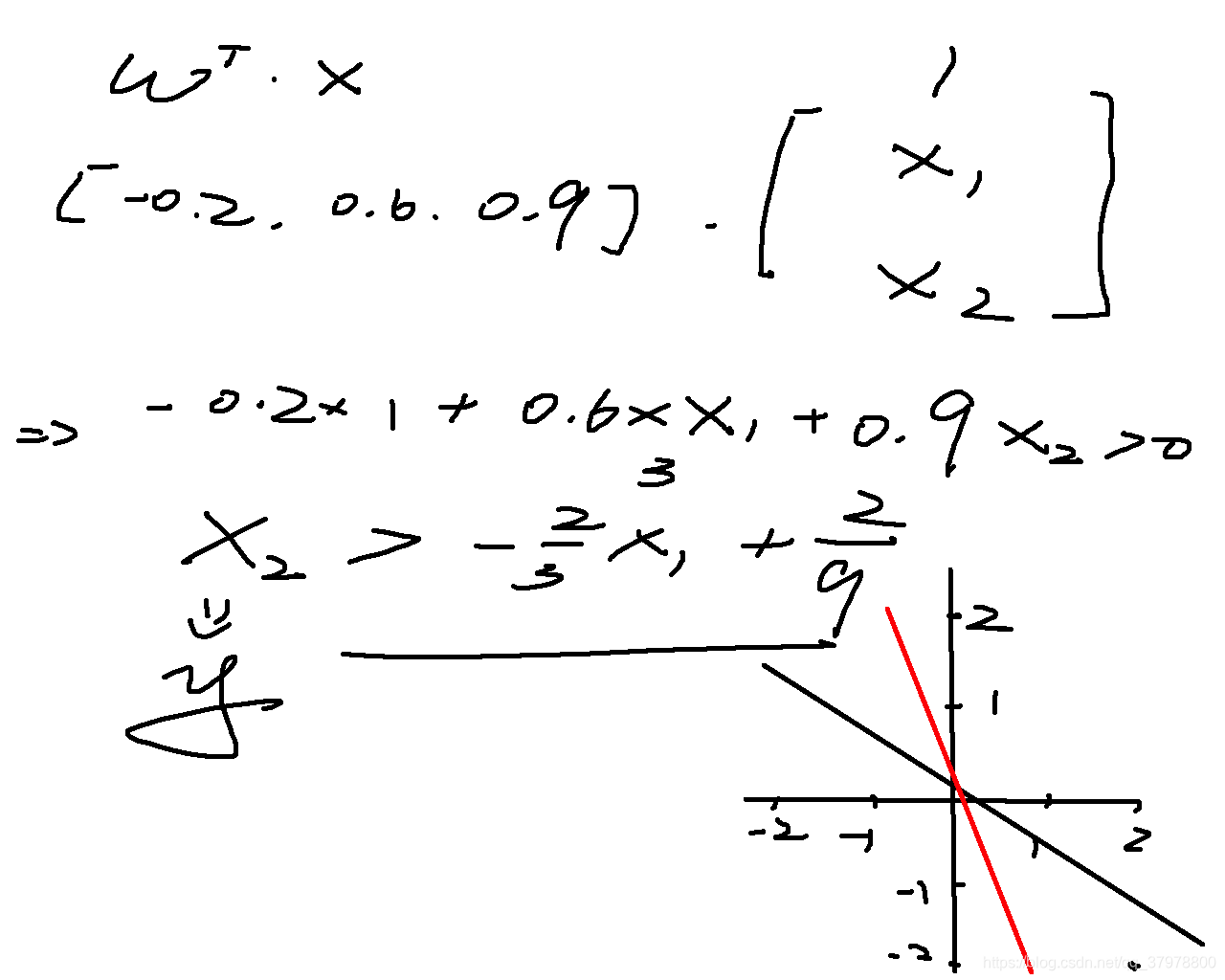

代码一
def predict(row, weights): # 传入想要的数据和权重
activation = weights[0]
for i in range(len(row)-1):
activation += weights[i + 1] * row[i]
return 1.0 if activation >= 0.0 else 0.0
# 瞎写的一种二分数据
dataset = [[2.78,2.55,0],
[1.47,2.36,0],
[1.39,1.85,0],
[3.06,3.01,0],
[7.63,2.76,0],
[5.33,2.09,1],
[6.93,1.76,1],
[8.76,-0.77,1],
[7.66,2.46,1]]
# 瞎写的权重
weights = [-1.23,0.30,-0.35]
# 预测
for row in dataset:
prediction = predict(row,weights)
print("真实值 : %d ,预测值 %d:" %(row[-1],prediction))

代码二

def predict(row, weights):
activation = weights[0]
for i in range(len(row) - 1):
activation += weights[i + 1] * row[i]
return 1.0 if activation >= 0.0 else 0.0
def opt_weights(train, learning_rate, how_many_epoch):
weights = [0.0 for i in range(len(train[0]))]
for epoch in range(how_many_epoch):
sum_error = 0.0
for row in train:
prediction = predict(row, weights)
error = row[-1] - prediction
sum_error += error ** 2
weights[0] = weights[0] + learning_rate * error
for i in range(len(row) - 1):
weights[i + 1] = weights[i + 1] + learning_rate * error * row[i]
print('This is epoch: %d, our learning_rate is : %.4f, the error is : %.4f' % (epoch, learning_rate, sum_error))
return weights
dataset = [[2.78, 2.55, 0],
[1.47, 2.36, 0],
[1.39, 1.85, 0],
[3.06, 3.01, 0],
[7.63, 2.76, 0],
[5.33, 2.09, 1],
[6.93, 1.76, 1],
[8.76, -0.77, 1],
[7.66, 2.46, 1]]
learning_rate = 0.1
how_many_epoch = 200
weights = opt_weights(dataset, learning_rate, how_many_epoch)
print(weights)
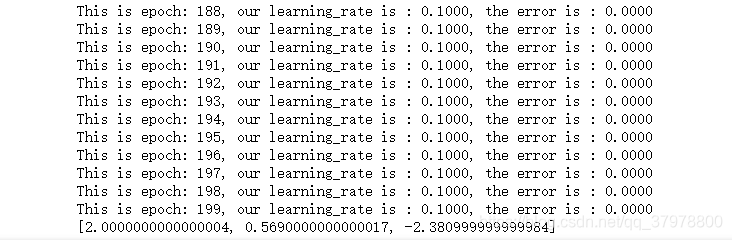
dataset = [[2.78,2.55,0],
[1.47,2.36,0],
[1.39,1.85,0],
[3.06,3.01,0],
[7.63,2.76,0],
[5.33,2.09,1],
[6.93,1.76,1],
[8.76,-0.77,1],
[7.66,2.46,1]]
# 使用梯度下降获得的权重
weights = [2.0000000000000004, 0.5690000000000017, -2.380999999999984]
# 预测
for row in dataset:
prediction = predict(row,weights)
print("真实值 : %d ,预测值 %d:" %(row[-1],prediction))















 1641
1641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









