








AlexNet


-
首次引入了ReLU, Dropout和Local Response Normalization (LRN)等技巧。
-
双CPU并行计算,在第三个卷积层Conv3和全连接层做信息交互

*算力:所需要的浮点数乘加的次数


-
使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,解决了Sigmoid在网络较深时的梯度弥散问题,提高了网络的训练速率。
-
为避免过拟合,训练时使用Dropout随机忽略部分神经元。
-
利用数据增强减低过拟合。利用随机裁剪和翻转镜像操作增加训练数据量。
-
使用重叠最大池化(Overlapping max pooling),最大池化可以避免平均池化的模糊化效果,而采用重叠技巧可提升特征的丰富性。
-
提出了局部响应归一化(LRN)层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
-
利用GPU的并行计算能力加速网络训练过程,并采用GPU分块训练的方式解决显存对网络规模的限制
数据增强:

图像的层次:
- 测试时,网络剪裁5个224x224图块(4个角图块和1个中心图块)以及它们的水平反射(总共10个)进行预测,并对网络的softmax层的预测求10个图块平均值。
By image translation (图像平移) : (256-224)2= 32 = 1024
By horizontal reflection (水平反射) : 1024 x 2= 2048 - 如果没有该方案, AlexNet网络会遭受严重的过拟合,这将迫使使用更小的网络。
像素的层次:
改变训练集RGB通道的图像像素强度(intensity):

该方法即增加了目标对光照强度和颜色变化的鲁棒性,把top-1错误率减少了1%.
重叠最大池化
使用重叠最大池化(Overlapping max pooling),最大池化可以避免平均池化的模糊化效果,而采用重叠技巧可提升特征的丰富性

- 一般用于池化的小块是不重叠的。
- 而AlexNet所使用的池化是可重叠的,即在池化的时候,每次移动的步幅小于池化的边长。
- AlexNet的池化的大小为3x3,每次池化移动步幅为2。这样就会出现重叠
- 相比s=2,2= 2的非重叠池化方法,该方法使top-1和top-5的错误率分别降低了0.4%和0.3%
局部响应归一化 Local Response Normalization (LRN)
- 局部归一化的动机:在神经生物学中有一个概念叫做“侧抑制(Lateral inhibition)"。其含义是被激活的神经元会对相邻的神经元产生抑制作用。
- 局部响应归一化就是借鉴"侧抑制”的思想是实现局部抑制。对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 当使用ReLU时,这种侧抑制能够帮助提升识别精度。
方法:
LRN对相同空间位置上相邻深度的卷积结果使用距离相关的加权平均函数做归一化。

归一化之后,越大的值得到的结果也越大,实现了距离相关的加权平均函数。

改变超参数可以实现其它归一化操作,如当k-0, n-N, a-1,B-0.5便是经典的 l2 归一化。
- LRN把top-1和top-5的错误率分别降低了1.4%和1.2%
- 2015年VGGNet论文Very Deep Convolutional Networks for Large-Scale ImageRecognition提到LRN对VGGNet作用不大
AlexNet损失函数(Loss Function)
- Softmax回归(或多类别逻辑回归, Softmax regression, multinomial logistic regression )是逻辑回归对处理多个类别的情况的推广。
- 多类别逻辑回归的优化目标,相当于在预测分布下最大化训练样本中正确标签的对数概率的平均值。
- 采用独热One-hot标签编码时,目标误差函数等同于交叉熵损失
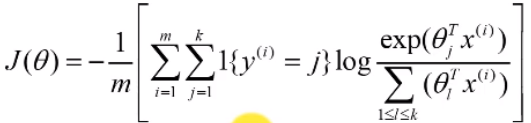
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









