







🌟🌟🌟博主主页:MuggleZero 🌟🌟🌟
《ARMv8架构初学者笔记》专栏地址:《ARMv8架构初学者笔记》
前文:
DMA(Direct Memory Access)直接内存访问,它在传输过程中是不需要CPU干预的,可以直接从内存中读写数据。CPU要搬移数据的话,假设是从内存A搬移到内存B,它首先要从内存A中把数据搬移到通用寄存器里,然后从通用寄存器里把数据搬移到内存B,此外,CPU搬移的过程中有可能被别的事情打断。而DMA就是专职搬移内存的,它可以操作总线,直接从内存A搬移数据到内存B,只要DMA开始干活了,就没有人来打扰它了,所以DMA效率上比CPU搬移要快。要使用DMA,在DMA开始干活之前,需要CPU配置DMA怎么搬移数据,从哪里搬到哪里。
但是有的时候我们会发现使用DMA获得的数据和cache中的数据不一致。出现这个问题的原因主要有两个:
-
DMA直接操作系统总线来读写内存地址,而CPU并不感知。
-
DMA修改的内存地址,在CPU的cache中有缓存,但是CPU并不知道内存数据被修改了,CPU依然去访问cache的旧数据,导致Cache一致性问题。
DMA和cache一致性的解决
-
第一种方案是使用硬件cache一致性的方案,需要SOC中CCI这种IP的支持。
-
第二种方案就是使用non-cacheable的内存来进行DMA传输,这种方案最简单但效率最低,严重降低性能,还增加功耗。
-
第三种使用软件主动干预的方法来帮助cache一致性。这个是比较常规的方法,特别是在类似CCI这种缓存一致性控制器没有出来之前,都用这种方式。
对于DMA的操作,我们需要考虑以下两种情况。
从内存到设备FIFO
传输路径:内存->设备FIFO (设备例如网卡,通过DMA读取内存数据到设备FIFO)
这种场景下,通常都是CPU的软件来产生了新的数据,然后通过DMA数据搬到设备的FIFO里。这里类似的网卡设备的发包过程。
在DMA传输之前,CPU的cache可能缓存了内存数据,需要调用cache clean/flush操作,把cache内容写入到内存中。因为CPU cache里可能缓存了最新的数据,然后再启动DMA传输数据,把DMA buffer的数据传输到设备的FIFO。
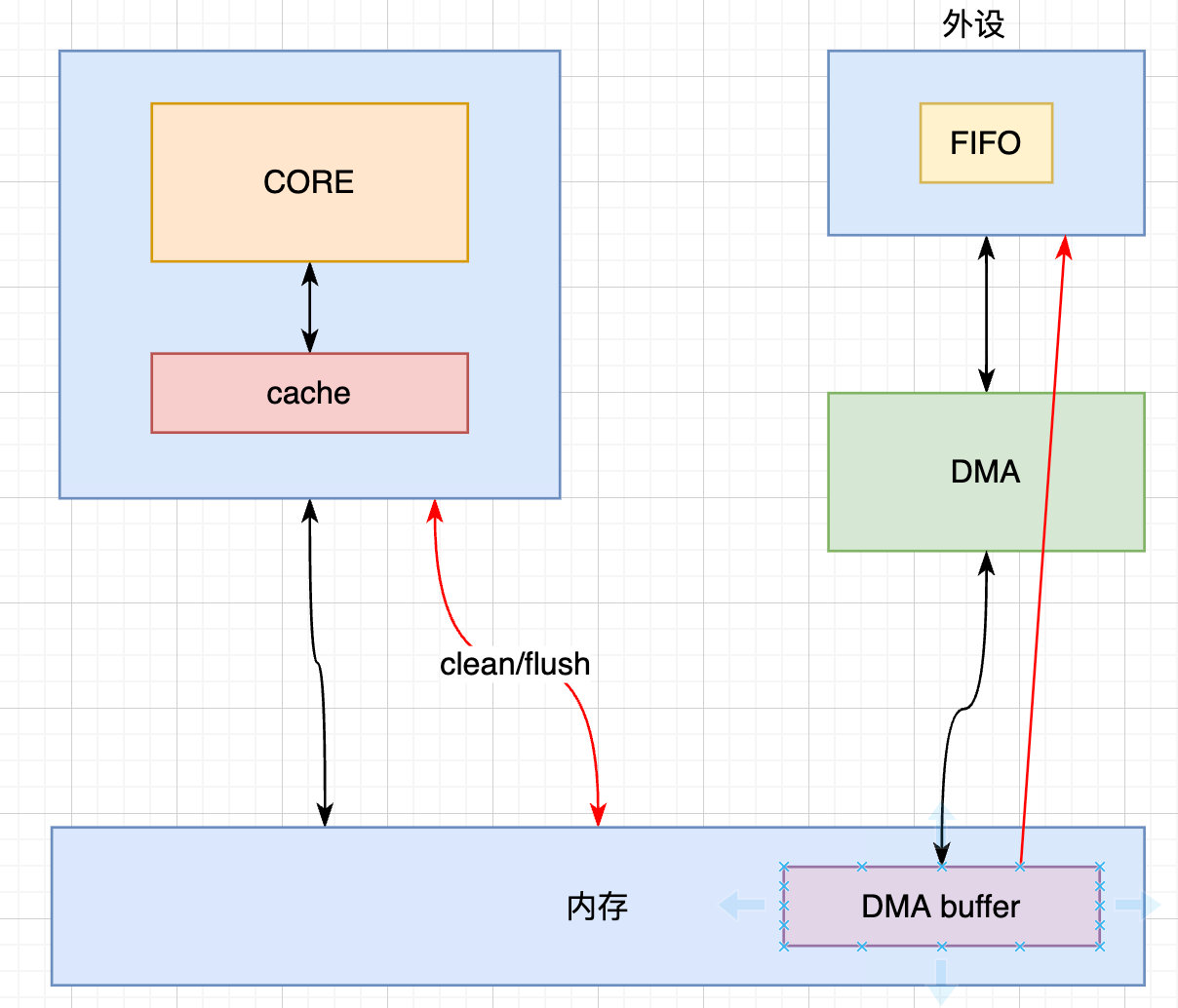
在DMA传数据之前,先做cache的clean或者flush操作是一个非常关键的点。
例如上面的图中,最新的数据其实是在cache里。因为CPU创建一个新的数据后必定是先到cache,然后再传递给DMA buffer。因此在启动DMA传输之前,必须要先clean/flush cache,把cache的数据回写到DMA buffer里。
从设备FIFO到内存
传输路径:设备FIFO -> 内存 (设备把数据写入到内存中)
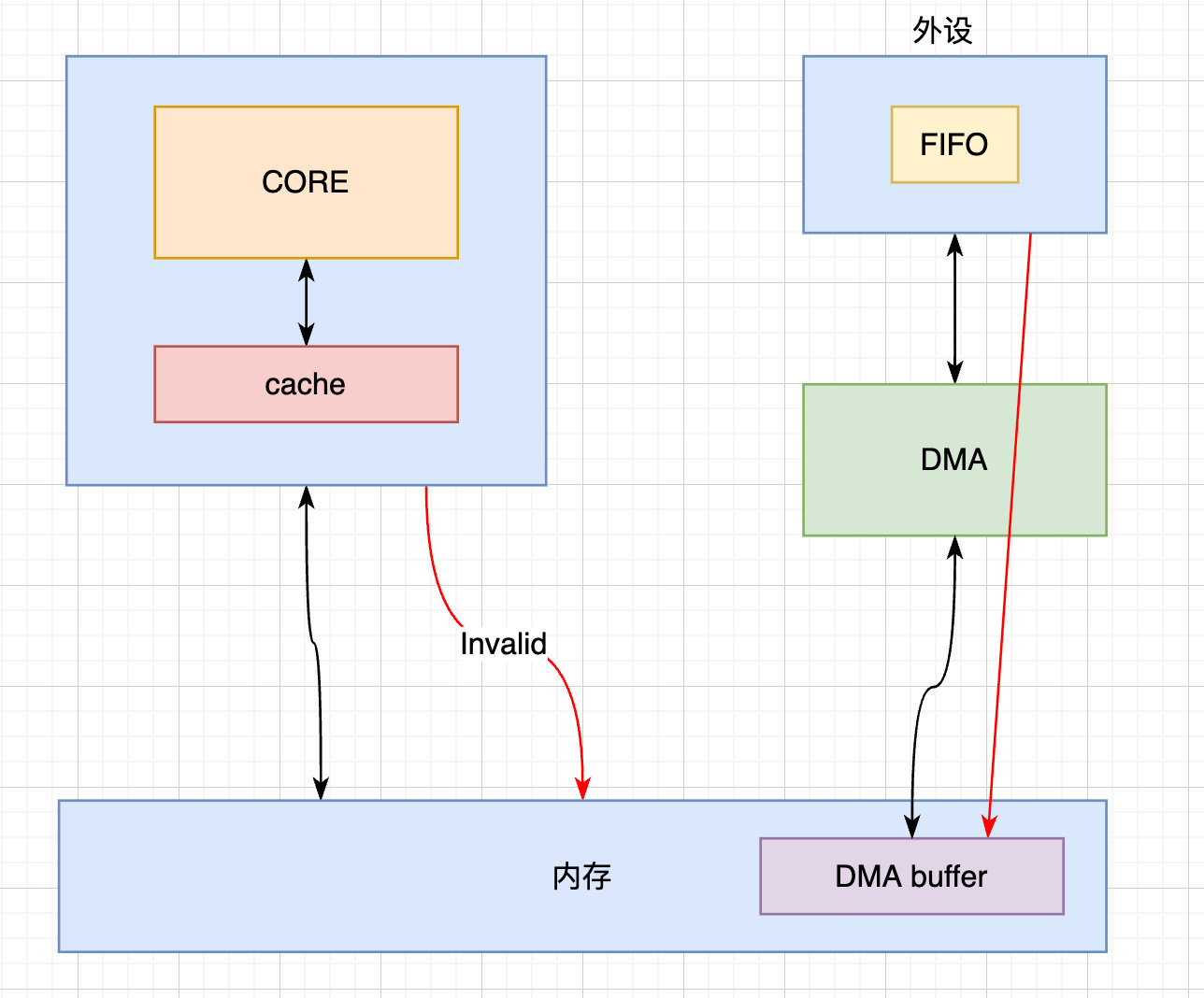
设备的FIFO产生了新数据,需要把数据写入到DMA buffer里,然后CPU就可以读到设备的数据,类似网卡的收包的过程。
在DMA传输之前,最新的数据是在设备的FIFO里,此时cache里的数据就是旧的无效数据,我们要先将其invalid,然后再启动DMA传输。
-
在启动DMA之前,最新的数据源在哪里?是在CPU那侧还是设备那侧?
-
在启动DMA之前,cache保存的数据 是最新的还是 过时的?
显然,CPU侧产生新数据时需要Flush cache,CPU侧获取新数据时需要Invalid cache。
欢迎关注我的个人微信公众号,一起交流学习嵌入式开发知识!
关注「求密勒实验室」


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











