







mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
mask
既可以做分类模型,也可以取其中的副产物embedding。
这里有一点需要特别注意,一般情况下,使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物。除非你决定使用预训练的embedding来训练fastText分类模型,这另当别论。
一、字符级别的n-gram

二、模型架构
fastText模型架构和word2vec的CBOW模型架构非常相似。下面是fastText模型架构图:
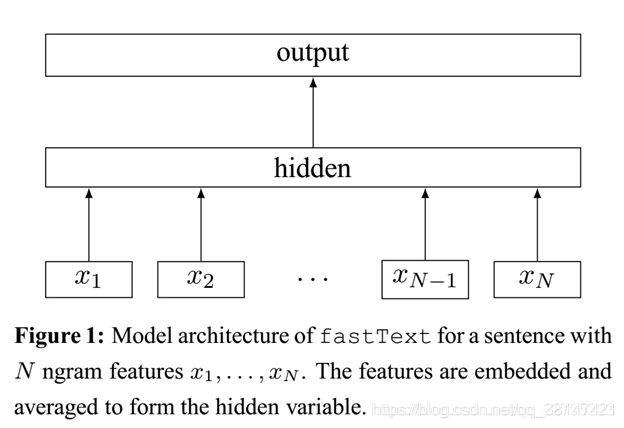
fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
不同的是,CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
值得注意的是,fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征;在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。
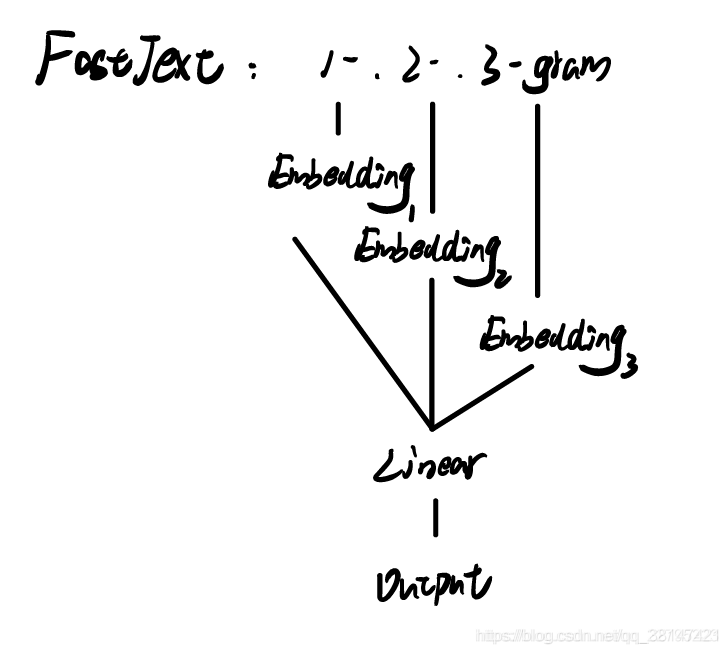
三、核心思想
四、关于分类效果
为何fastText的分类效果常常不输于 传统的非线性分类器?
使用词embedding而非词本身作为特征(tf-idf),这是fastText效果好的一个原因;
另一个原因就是字符级n-gram特征的引入对分类效果会有一些提升 。
五、总结
总结:
传统意义上的fasttext,可以认为是在做分类,然后模型的副产物即为词向量,那么模型的输入对于传统fasttext来说,是字符级别的n-gram(可以与Word2vec进行对比,上文中有对比的具体描述,这里不赘述)。fasttext最大的一个优势是速度快,并且效果和很多深度学习方法差不到哪去,这是最大的一个优势;并且与传统机器学习方法相比,其效果也远远好于机器学习方法。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









