







N-grams模型
自然语言处理过程中,一个值得我们主义的是,如果我们仅仅是将文本字符串分割成单独的文本,此时我们只是简单的去分析文本中每个字符所代表的潜在意义与我们需要分析的结果的关系性,然而我们忽略一个非常重要的信息,文本的顺序是含有非常重要的信息的。
举一个简单的例子,“钓鱼”两个词,如果我们单独去分析这两个词,而不是看作一个整体的话,那么我们得到的语意意思就是“钓”是一个动作词,“鱼”是一个名词,而当两个字放在一起的时候,我们知道其实我们想表述的“钓鱼”是我们要做的一个活动(event)。
又比如英文“hot dog”,我们都知道这个词组想表达的是我们吃的食物“热狗香肠包”,所以我们不希望单独去看hot和dog两个意思,如果是这样子我们可以看出意思相差非常的远,由此我们可以看出文本顺序的重要性。
而实际操作中,我们将这种把文本顺序保留下来的行为称为建立N-grams模型,也就是我们将一个字符串分割成含有多个词的标识符(tokens)。他们都属于文本字符串Tokenization的一个过程。
import re
from nltk.util import ngrams
sentence = "I love deep learning as it can help me resolve some complicated problems in 2018."
# tokenize the sentence into tokens
pattern = re.compile(r"([-\s.,;!?])+")
tokens = pattern.split(sentence)
tokens = [x for x in tokens if x and x not in '- \t\n.,;!?']
bigrams = list(ngrams(tokens, 2))
print([" ".join(x) for x in bigrams])输出结果为:
['I love', 'love deep', 'deep learning', 'learning as', 'as it', 'it can', 'can help', 'help me', 'me resolve', 'resolve some', 'some complicated', 'complicated problems', 'problems in', 'in 2018']
上述代码的执行是首先将文本字符串分割成单独(unique)标识符,并且引入了正则表达式来更精准的分割字符串。除此之外,我们运用了NLTK的库来分割出一个含有两个词(Bi-Gram)的标识符。所以从上面我们可以看出,如“deep learning"和”complicated problems“这样子的组合更切合我们想要表达的意思,但是独个字符看的话我们就未必看得出了。
虽然N-grams模型可以让我们更好的去分割出具有更好语义的标识符,进而让我们做进一步文本分析,但是缺点也是同样明显,那就是运用N-grams模型可能让我们的词汇量成指数级的增长,并且并不是所有的Bigram都含有有用信息,而这个情况在甚至乎在Trigram或者Quad gram等含有更多单独字符在内的N-grams模型会更严重。这样子做产生的问题就是我们最终拿到的特征向量(the dimension of the feature)的维度将会超过我们本身的文件样本数(length of the documents),而最终当我们将这些提取出来的特征放入到机器学习算法的话,就会导致过拟合(over fitting)的情况。如此训练出来的模型将没有什么太好的performance和预测能力。
fastText中的N-gram特征
fastText有个比较突出的问题——就是丢失了词顺序的信息,因为隐层是通过简单的求和取平均得到的。为了弥补这个不足,fastText增加了N-gram的特征。
为了处理词顺序丢失的问题,fastText增加了N-gram的特征。具体做法是把N-gram当成一个词,也用embeddding向量来表示,在计算隐层时,把N-gram的embedding向量也加进去求和取平均。举个例子来说,假设某篇文章只有3个词,W1,W2和W3,N-gram的N取2,w1、w2、w3以及w12、w23分别表示词W1、W2、W3和bigram W1-W2,W2-W3的embedding向量,那么文章的隐层可表示为:
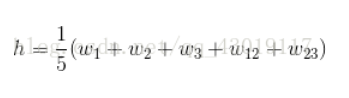
通过back-propagation算法,就可以同时学到词的Embeding和n-gram的Embedding了。具体实现上,由于n-gram的量远比word大的多,完全存下所有的n-gram也不现实。FastText采用了Hash桶的方式,把所有的n-gram都哈希到buckets个桶中,哈希到同一个桶的所有n-gram共享一个embedding vector。如下图所示:

图中Win是Embedding矩阵,每行代表一个word或N-gram的embeddings向量,其中前V行是word embeddings,后Buckets行是n-grams embeddings。每个n-gram经哈希函数哈希到0-bucket-1的位置,得到对应的embedding向量。用哈希的方式既能保证查找时O(1)的效率,又可能把内存消耗控制在O(buckets * dim)范围内。不过这种方法潜在的问题是存在哈希冲突,不同的n-gram可能会共享同一个embedding。如果桶大小取的足够大,这种影响会很小。
Reference
https://www.cnblogs.com/jielongAI/p/10189907.html
https://blog.csdn.net/qq_43019117/article/details/82770124















 3266
3266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









