







神经网络训练技巧1
一、优化失败的原因
我们为什么会遇到 training loss 为0的情况?
- 遇到了鞍点,梯度为0,却不是局部极小点
- 解决方案:知道loss function的形状, 可以利用某些已知参数,根据泰勒公式知道某点附近部分loss function的形状,
- L ( θ ) ≈ L ( θ ′ ) + 1 2 ( θ − θ ′ ) T H ( θ − θ ′ ) L(\theta) \approx L(\theta')+\dfrac{1}{2}(\theta-\theta')^TH(\theta-\theta') L(θ)≈L(θ′)+21(θ−θ′)TH(θ−θ′)
- 通过第三项的H矩阵判断是否是鞍点(看特征值即可),如果是鞍点,找到负的特征值对应的某个特征向量,即为参数更新的方向
Saddle point 和 Local Minima哪个更常见?
- 思想引入:低维空间中的 Local Minima 可能是高维空间中的Saddle point
- 大部分H的特征值为全正的情况很少,故也许前者更多
二、批次与动量
1.批处理数据更新参数
- 不太平稳
- “蓄力”时间更短(不考虑GPU)
- small batch size的结果有时候可能更好(每个batch数目少),一个可能的解释是这样更有几率使得模型loss训练到极小点,且更有可能走到盆地(因为每次 update 的方向不太一样)
2.带动量的更新参数
- 新的方向是上一步更新方向以及梯度下降方向的折中。
- 另一种解读方式:当前的gradient考虑的不仅是上一步的gradient,更是之前所有gradient的累计。这个思想与LSTM、时间序列分析等思想很类似。
三、自动调整学习率
问题:震荡出现时,loss不再下降也有可能出现。训练卡在“山谷某边沿之间”。
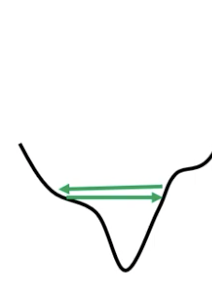
事实上,即使是convex的error surface,训练也可能很困难。
- learning rate 不合适导致,故客制化的learning rate 更被需要
- Root Mean Square
- η → η σ i t \eta \rightarrow \dfrac{\eta}{\sigma_i^t} η→σitη
- σ i t = 1 t + 1 ∑ i = 0 t ( g i t ) 2 \sigma _i^t = \sqrt{\dfrac{1}{t+1} \sum_{i=0}^t(\textbf{g}_i^t)^2} σit=t+11∑i=0t(git)2
- 梯度小的参数update量较大,反之较小
- 同一个参数的值大小差不多(*),根据前一时刻的自我调整速度较慢
- RMSProp2
- 可以调整当前参数的重要性
- η → η σ i t \eta \rightarrow \dfrac{\eta}{\sigma_i^t} η→σitη
- σ i t = α ( σ i t − 1 ) 2 + ( 1 − α ) ( g i t ) 2 \sigma _i^t = \sqrt{\alpha(\sigma_i^{t-1})^2+(1-\alpha) (\textbf{g}_i^t)^2} σit=α(σit−1)2+(1−α)(git)2
- Adam:RMSProp+动量(Torch有)
- 学习率调度
- Learning Rate Decay:减少由于后期的loss过小导致的震荡
- Warm up3:先增加,后减少。BERT训练可用
四、损失函数的影响
结论:交叉熵比MSE方法更有利于优化【李老师的例子:神罗天征】
五、批次标准化
training:
- 目标:不同的input 有相同的输入范围
- 对一个batch的输入和部分参数标准化: x ~ i r ← x i r − m i σ i \widetilde{x}_i^r \leftarrow \dfrac{x_i^r-m_i}{\sigma_i} x ir←σixir−mi
testing:
- 没有batch,用训练的时候得到的 μ ‾ \overline\mu μ标准化














 2793
2793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









