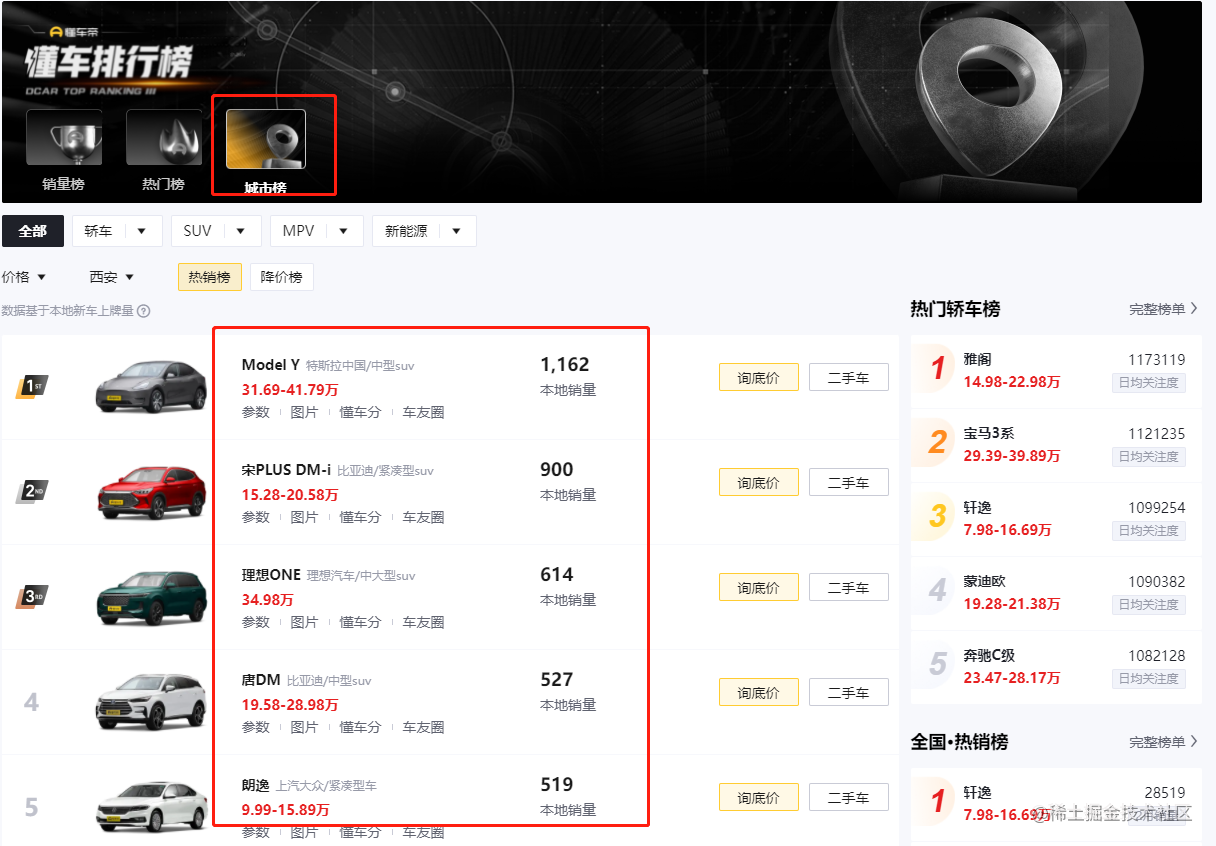
本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删! Python 懂车帝全车系销量排行榜 需求 车系ID 城市 时间段 车系名称 销量 4363 深圳 2022年2月 Model Y 1,224 分城市榜单,所有城市热销榜,拉到底部获取全部车系数据 操作环境 win10 Google nexus5x(root) Python3.9 Charles 需求分析








 超级会员免费看
超级会员免费看
 本文介绍了如何使用Python通过抓包分析获取懂车帝全国城市列表和指定城市的热销车系销量排行榜。首先,分析APP接口找到数据来源,然后利用Python请求接口并解析JSON数据,实现数据获取。最后展示了运行效果和资源下载链接。
本文介绍了如何使用Python通过抓包分析获取懂车帝全国城市列表和指定城市的热销车系销量排行榜。首先,分析APP接口找到数据来源,然后利用Python请求接口并解析JSON数据,实现数据获取。最后展示了运行效果和资源下载链接。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








