







使用 Python 爬取并打印双色球近期 5 场开奖数据
首先看下运行的效果图:
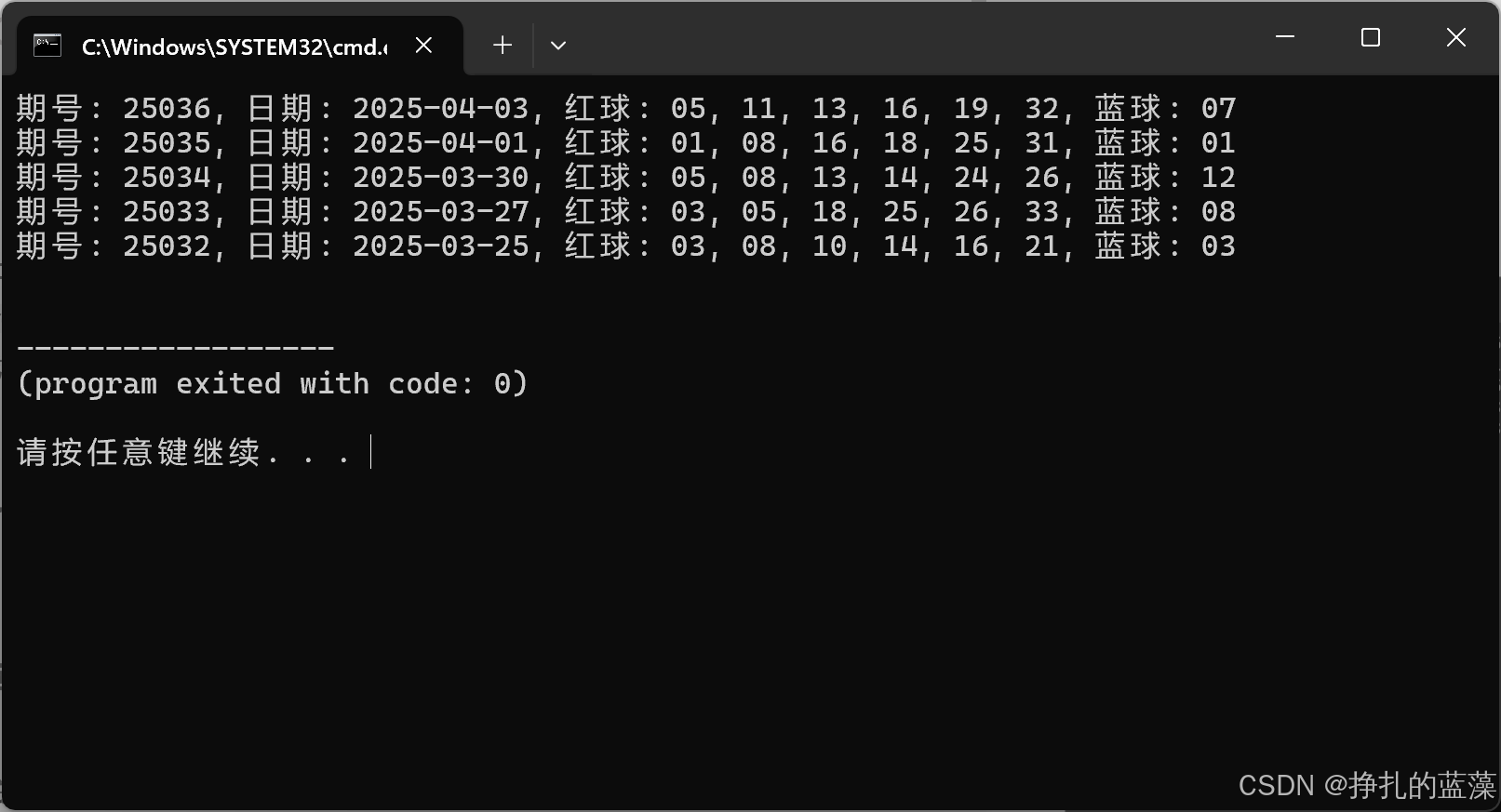
我访问官网对比近5期的结果是没有问题的:

我们将使用 Python 爬取并打印双色球近期 5 场的开奖数据。这个过程涉及到网页抓取和数据解析,利用 requests 库来发送 HTTP 请求以获取数据,以及 BeautifulSoup 库来解析 HTML 内容。最终,打印出期号、日期、红球和蓝球的信息。
前期准备
安装所需库
首先,确保你已经安装了 requests 和 BeautifulSoup 库。你可以使用以下命令进行安装:
pip install requests beautifulsoup4
完整代码
下面是整个的完整代码:
import requests
from bs4 import BeautifulSoup
def get_recent_five_ssq():
# 目标URL,用于获取最新的开奖信息
url = "https://datachart.500.com/ssq/history/newinc/history.php?start=00001&end=99999"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
try:
# 发送请求获取网页内容
response = requests.get(url, headers=headers)
response.encoding = 'gbk' # 设置正确的编码方式
response.raise_for_status()
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('tbody', {'id': 'tdata'})
if not table:
print("无法找到开奖数据表格,可能是网页结构发生变化。")
return
# 提取最新的5场开奖数据
recent_five = table.find_all('tr')[:5] # 取前5行数据
# 打印开奖结果
for row in recent_five:
cols = row.find_all('td')
issue = cols[0].text.strip()
date = cols[15].text.strip()
red_balls = [cols[i].text.strip() for i in range(1, 7)]
blue_ball = cols[7].text.strip()
print(f"期号: {issue}, 日期: {date}, 红球: {', '.join(red_balls)}, 蓝球: {blue_ball}")
except requests.RequestException as e:
print(f"请求错误: {e}")
# 执行函数
get_recent_five_ssq()
代码解析
1. 导入必要的库
import requests
from bs4 import BeautifulSoup
这两行代码导入我们将要使用的库。 requests 用于发送 HTTP 请求,而 BeautifulSoup 用于解析 HTML 内容。
2. 定义函数 get_recent_five_ssq
def get_recent_five_ssq():
我们定义了一个函数 get_recent_five_ssq 来封装获取并打印双色球开奖数据的操作。
3. 设置请求的 URL 和 Headers
url = "https://datachart.500.com/ssq/history/newinc/history.php?start=00001&end=99999"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
- URL : 指向 500 彩票的双色球历史开奖信息页面。
- Headers : 设置请求的 User-Agent ,模拟浏览器请求以避免被服务器拒绝。
4. 发送请求并处理响应
response = requests.get(url, headers=headers)
response.encoding = 'gbk' # 设置正确的编码方式
response.raise_for_status()
- 使用
requests.get发送 GET 请求。 - 设置
response.encoding为gbk,以确保能正确处理网页的编码格式。
5. 解析 HTML 内容
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('tbody', {'id': 'tdata'})
- 通过
BeautifulSoup解析 HTML 内容。 - 使用
soup.find找到包含开奖数据的表格。
6. 提取并打印数据
recent_five = table.find_all('tr')[:5] # 取前5行数据
for row in recent_five:
cols = row.find_all('td')
issue = cols[0].text.strip()
date = cols[15].text.strip()
red_balls = [cols[i].text.strip() for i in range(1, 7)]
blue_ball = cols[7].text.strip()
print(f"期号: {issue}, 日期: {date}, 红球: {', '.join(red_balls)}, 蓝球: {blue_ball}")
- 提取最新的 5 场开奖数据。
- 遍历每行数据,并提取期号、日期、红球和蓝球的信息。
- 使用
print函数打印每场开奖的结果。
7. 错误处理
except requests.RequestException as e:
print(f"请求错误: {e}")
- 使用
try/except捕获并处理请求过程中可能出现的异常。


















 1257
1257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











