







一、实验目的
- 熟悉Spark的RDD基本操作及键值对操作;
- 熟悉使用RDD编程解决实际具体问题的方法。
二、实验内容
1. 熟悉RDD编程
-
转换操作
filter(func)操作会筛选出满足函数func的元素,并返回一个新的数据集
>>> lines = sc.textFile(“file:///home/hadoop/mycode/rdd/word.txt”) >>> linesWithSpark = lines.filter(lambda line: “Spark” in line) >>> linesWithSpark.foreach(print)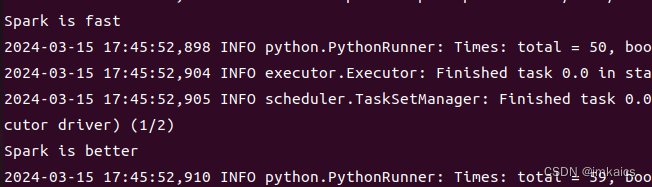
map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集。
>>> data = [1, 2, 3, 4, 5] >>> rdd1 = sc.parallelize(data) >>> rdd2 = rdd1.map(lambda x: x+10) >>> rdd2.foreach(print)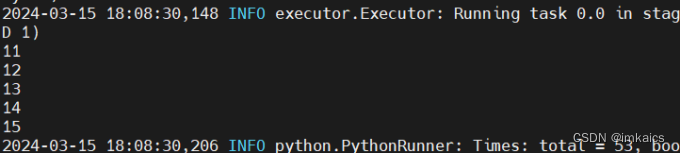
flatMap(func)与map类似
>>> lines = sc.textFile("file:///home/hadoop/mycode/rdd/word.txt") >>> words = lines.map(lambda line: line.split(" ")) >>> words.foreach(print)
groupByKey()用于(K, V)键值对数据时,返回一个(K, Iterable)的可迭代数据集
>>> lines = sc.textFile("file:///home/hadoop/mycode/rdd/word.txt") >>> words = lines.flatMap(lambda line: line.split(" ")) >>> words.foreach(print)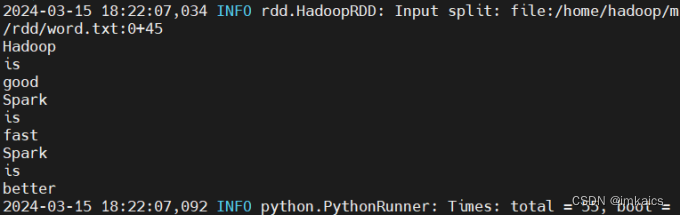
reduceByKey(func)将会对之前的每个key进行func聚合操作后,返回一个新的(K, V)形式的数据集
>>> words = sc.parallelize([("hadoop", 1), ("is", 1), ... ("good", 1), ("Spark", 1), \ ... ("is", 1), ("fast", 1), ("Spark", 1), ("is", 1), ("fast", 1)]) >>> words1 = words.groupByKey() >>> words1.foreach(print)
-
行动操作
- 使用
count()返回数据集中的元素个数
>>> rdd = sc.parallelize([1, 2, 3, 4, 5]) >>> rdd.count()
- 使用
collect()以数组形式返回数据集中的所有元素
>>> rdd.collect()
- 使用
first()返回数据集中的第一个元素
>>> rdd.first()
- 使用
take(n)以数组形式返回数据集的前n个元素
>>> rdd.take(3)
- 使用
reduce(func)通过函数func聚合数据集中的元素
>>> rdd.reduce(lambda a, b: a+b)
- 使用
foreach(funcc)将数据集中的每一个元素传递到func中运行
rdd.foreach(lambda elem: print(elem))
- 使用
2. pySpark交互式编程
已经预先将数据放在了/home/hadoop/mycode/ex2/实验2-数据.txt文件中,文件下载地址https://wwd.lanzouq.com/iouUW1w8ebyb
数据内容示例如下:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
- 该系总共有多少学生
>>> rdd1 = sc.textFile("file:///home/hadoop/mycode/ex2/实验2-数据.txt")
>>> rdd2 = rdd1.map(lambda line:line.split(","))
>>> rdd3 = rdd2.map(lambda line: (line[0], 1))
>>> rdd4 = rdd3.reduceByKey(lambda a,b: a+b)
>>> print("学生人数为:{}".format(rdd4.keys().count()))

- 该系共开设了多少门课程;
>>> rdd1 = sc.textFile("file:///home/hadoop/mycode/ex2/实验2-数据.txt")
>>> rdd2 = rdd1.map(lambda line:line.split(","))
>>> rdd3 = rdd2.map(lambda line: (line[1], 1))
>>> rdd4 = rdd3.reduceByKey(lambda a,b: a+b)
>>> print("所开课程门数::{}".format(rdd4.keys().count()))

- Tom同学的总成绩平均分是多少;
>>> rdd1 = sc.textFile("file:///home/hadoop/mycode/ex2/实验2-数据.txt")
>>> rdd2 = rdd1.map(lambda line:line.split(","))
>>> rdd3 = rdd2.filter(lambda line: line[0]=="Tom")
>>> rdd4 = rdd3.map(lambda line:int(line[2])).reduce(lambda a,b:a+b)
>>> print("Tom所选课程为{}门,总分{},平均分{}".format(rdd3.count(), rdd4, rdd4/rdd3.count()))

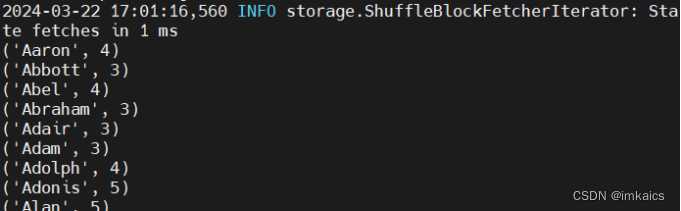
- 求每名同学的选修的课程门数;
>>> rdd1 = sc.textFile("file:///home/hadoop/mycode/ex2/实验2-数据.txt")
>>> rdd2 = rdd1.map(lambda line:line.split(","))
>>> rdd3 = rdd2.map(lambda line: (line[0], 1))
>>> rdd4 = rdd3.reduceByKey(lambda a, b: a+b)
>>> rdd4.foreach(print)
- 该系DataBase课程共有多少人选修;
>>> rdd1 = sc.textFile("file:///home/hadoop/mycode/ex2/实验2-数据.txt")
>>> rdd2 = rdd1.map(lambda line:line.split(","))
>>> rdd3 = rdd2.filter(lambda line: line[1]=="DataBase")
>>> print("选择DataBase课程人数:",rdd3.count())

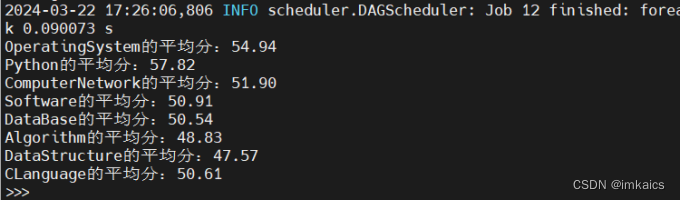
- 各门课程的平均分是多少;
>>> rdd1 = sc.textFile("file:///home/hadoop/mycode/ex2/实验2-数据.txt")
>>> rdd2 = rdd1.map(lambda line:line.split(","))
>>> rdd3 = rdd2.map(lambda line: (line[1], (int(line[2]), 1)))
>>> rdd4 = rdd3.reduceByKey(lambda a, b: (a[0]+b[0], a[1]+b[1]))
>>> rdd4.foreach(lambda a:print("{}的平均分:{:.2f}".format(a[0], a[1][0]*1.0/a[1][1])))
- 使用累加器计算共有多少人选了DataBase这门课。
>>> rdd1 = sc.textFile("file:///home/hadoop/mycode/ex2/实验2-数据.txt")
>>> rdd2 = rdd1.map(lambda line:line.split(","))
>>> rdd3 = rdd2.filter(lambda line:line[1]=="DataBase").map(lambda line: (line[1], 1))
>>> rdd4 = rdd3.reduceByKey(lambda a, b: a+b)
>>> rdd4.foreach(lambda a: print("选择{}课程的人数:{}".format(a[0],a[1])))

3. 编写独立应用程序
- 实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。
文件A.txt内容:
202131116020016 x
202131116020017 y
202131116020018 x
202131116020019 y
202131116020020 z
202131116020021 z
文件B.txt内容:
202131116020016 y
202131116020017 y
202131116020018 x
202131116020019 z
202131116020020 y
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[1]").setAppName("filter")
sc = SparkContext(conf = conf)
file_A = "file:///home/hadoop/mycode/ex2/A.txt"
file_B = "file:///home/hadoop/mycode/ex2/B.txt"
C = "file:///home/hadoop/mycode/ex2/C"
# 读取两个文件
rdd_A = sc.textFile(file_A)
rdd_B = sc.textFile(file_B)
# 将两个文件数据合并
rdd_union = rdd_A.union(rdd_B)
# 使用map来将数据转为键值对,实际上我们只需要key
rdd_C = rdd_union.map(lambda a:(a, 1))
# 按照key分组并排序
rdd_C = rdd_C.groupByKey()
rdd_C = rdd_C.sortByKey()
# 提取keys
rdd_C = rdd_C.keys()
# 保存到结果文件
rdd_C.coalesce(1).saveAsTextFile(C)
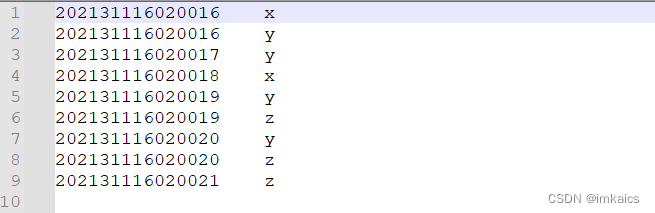
- 实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("avg")
sc = SparkContext(conf = conf)
# 基本路径
base_path = "file:///home/hadoop/mycode/ex2/"
# 读取成绩文件
rdd_algorithm = sc.textFile(base_path + "Algorithm成绩.txt")
rdd_database = sc.textFile(base_path + "Database成绩.txt")
rdd_python = sc.textFile(base_path + "Python成绩.txt")
# 将所有成绩做union
rdd_all_score = rdd_algorithm.union(rdd_database).union(rdd_python)
# 通过map对数据进行转换
rdd_all = rdd_all_score.map(lambda line:(line.split(" ")[0], (float(line.split(" ")[1]), 1)))
# 统计每个人的总分和数目
rdd_all_reduce = rdd_all.reduceByKey(lambda a, b:(a[0]+b[0], a[1]+b[1]))
# 计算每个人平均分
rdd_avg_score = rdd_all_reduce.mapValues(lambda a:round(a[0]/a[1],2))
rdd_avg_score.coalesce(1).saveAsTextFile(base_path+"avgScore")
















 1293
1293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









