







一、实验目的
- 通过实验掌握Spark SQL的基本编程方法;
- 熟悉RDD到DataFrame的转化方法;
- 熟悉利用Spark SQL管理来自不同数据源的数据。
二、实验内容
1.Json文件读取及Spark SQL基本操作
以自己学号(your student number)为第一条数据,生成20条数据(后面数据your student number依次递增1,name和age随机),详细格式如下。保存并命名为自己姓名的json格式(例如wangkai.json)。
{ "id":your student number , "name":"wangkai" , "age":20 }
{ "id": your student number + 1 , "name":"random","age":29 }
{ "id": your student number + 2 , "name":" random ","age":29 }
{ "id": your student number + 3 , "name":" random ","age":28 }
……
{ "id": your student number + 17 , "name":" random ","age":28 }
{ "id": your student number + 18 , "name":" random " }
{ "id": your student number + 19 , "name":" random " }
创建DataFrame,并写出Python语句完成下列操作:
-
随机生成相关数据并保存到JSON文件;
import faker import random import json fake = faker.Faker() data = [] # 用来装我们的数据,最后一起写入文件 id = 202131116020016 # 学号 one_data = { "id": id, "name": "wangkai", "age": 20 } data.append(one_data) for i in range(19): # 随机生成的19条数据 id += 1 one_data = { "id": id, "name": fake.name(), "age": random.randint(10, 60) } data.append(one_data) # 将数据写入文件 with open("./wangkai.json", "w") as file: for item in data: json.dump(item, file) file.write("\n") -
从JSON中读取数据,并使用DataFrame存储
from pyspark import SparkConf from pyspark.sql import SparkSession from pyspark.sql import functions spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate() df = spark.read.format("json").load("file:///home/hadoop/mycode/ex3/wangkai.json") -
查询所有数据;
df.show()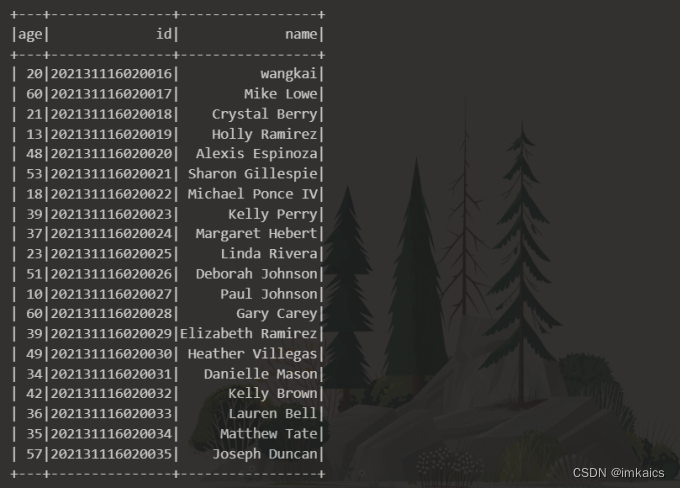
-
取出前3条数据;
df.limit(3).show()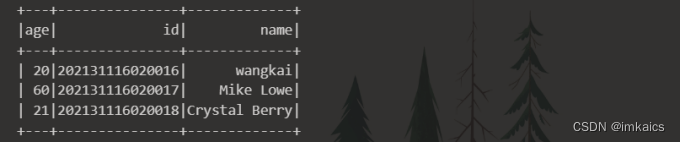
-
筛选出15<age<30的记录;
df.filter((df['age'] > 15) & (df['age'] < 30)).show()
-
将数据按age分组(自行设置age条件);
# 统计每个年龄的人数 df.groupBy('age').count().sort(df['age'].asc()).show()
-
将数据按name升序排列;
df.sort(df['name'].asc()).show()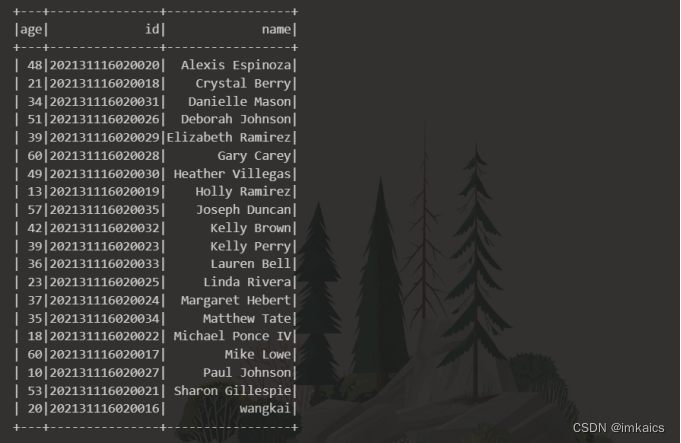
-
查询所有记录的name列,并为其取别名为username;
df.select(df['name'].alias('username')).show()
-
查询年龄age的平均值;
# 也可以将所有age加起来除以总个数 df.select(functions.avg(df['age'])).show()
-
查询年龄age的最小值
# 也可以将数据按照age升序排列,然后只取一条数据即为最小age数据 df.select(functions.min('age')).show()
2.编程实现将RDD转换为DataFrame
-
将前面的数据保存为txt文件,修改为如下格式(id,name,age),保存并命名为自己姓名的txt格式(例如wangkai.txt):
your student number , wangkai , 20 your student number + 1 , random, 29 your student number + 2 , random , 29# 将每一行的元素拼接产生新的一列,将新的一列写入txt文件 df_temp = df.withColumn("concat", functions.concat_ws(",", "id", "name","age")) df_temp.select(df_temp['concat']) \ .write.format("text").save("file:///home/hadoop/mycode/ex3/wangkai.txt")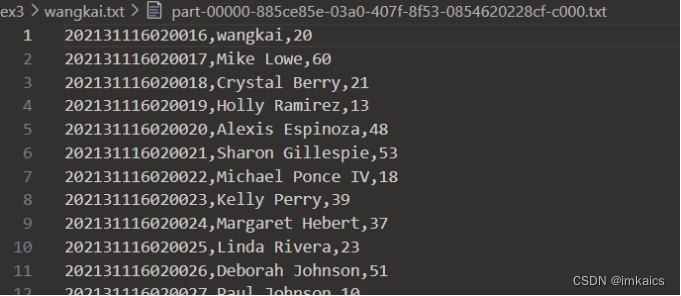
-
读取文件处理为RDD,接着转换为DataFrame,并按“id:1,name:Ella,age:36”的格式打印出DataFrame的所有数据。
from pyspark.sql import Row wk = spark.sparkContext.\ textFile("file:///home/hadoop/mycode/ex3/wangkai.txt/").\ map(lambda x: x.split(",")).\ map(lambda x:Row(id=x[0], name=x[1], age=x[2])) # 注册临时表 schemawk = spark.createDataFrame(wk) schemawk.createOrReplaceTempView("wk") df = spark.sql("select * from wk") # 按照指定格式输出 df.rdd.foreach(lambda x:print("id:", x[0]+", name:"+x[1]+", age:"+x[2]))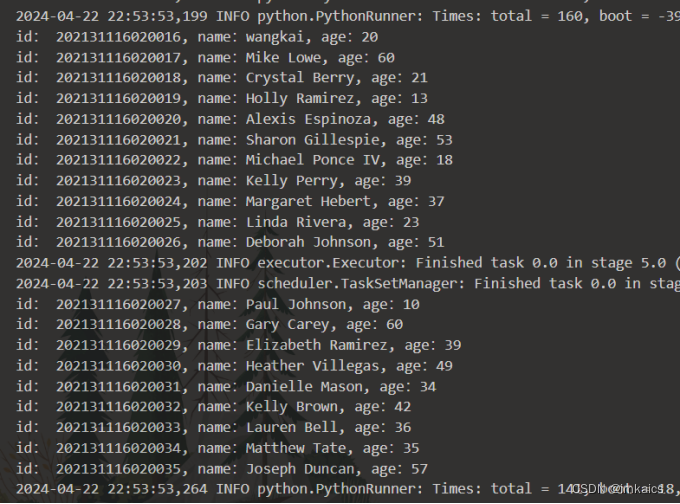
3.编程实现利用DataFrame读写MySQL的数据
(可使用其他数据库)
-
在MySQL数据库中新建数据库sparktest,再创建表student,将前面的数据传入数据库,如表5-1所示。
表原有数据:id name Age your student number random 22 your student number+1 random 25在这里我使用了Navicat来创建数据库和表,过程十分简单,这里不进行详细说明。
下面是将前面的20条数据写入MySQL的代码:from pyspark.sql import SparkSession # 配置SparkSession,包括MySQL JDBC驱动的路径 spark = SparkSession.builder \ .appName("PySpark MySQL") \ .config("spark.jars", "/usr/local/spark/jars/mysql-connector-java-5.1.10-bin.jar") \ .getOrCreate() # 数据库相关信息 prop = { "user": "root", "password": "root123", "driver": "com.mysql.jdbc.Driver" } # 读取并将前面20条数据插入数据库 df = spark.read.format("json").load("file:///home/hadoop/mycode/ex3/wangkai.json") df.write.jdbc('jdbc:mysql://192.168.127.186:3306/sparktest', 'student', 'append', prop)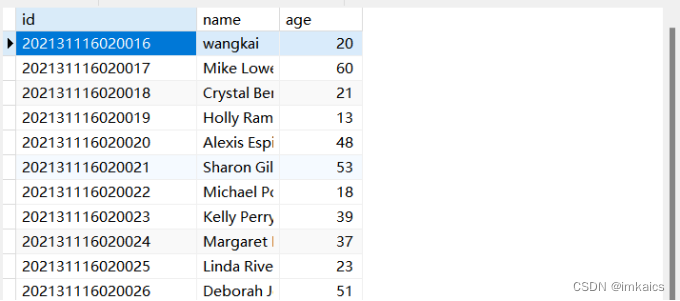
-
配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入如表5-2所示的10行数据到MySQL中(学号递增,其他字段随机),最后打印出age的平均值。
表新增数据:id name age your student number+20 random 26 your student number+21 random 23import faker import random from pyspark.sql.types import * from pyspark.sql import SparkSession # 配置SparkSession,包括MySQL JDBC驱动的路径 spark = SparkSession.builder \ .appName("PySpark MySQL") \ .config("spark.jars", "/usr/local/spark/jars/mysql-connector-java-5.1.10-bin.jar") \ .getOrCreate() fake = faker.Faker() data = [] # 用来装我们的数据,最后一起转成DataFrame for i in range(20, 30): # 随机生成的10条数据 one_data = { "id": str(202131116020016 + i), "name": fake.name(), "age": random.randint(10, 60) } data.append(one_data) # 设置模式信息 schema = StructType([ StructField("id", StringType(), True), StructField("name", StringType(), True), StructField("age", IntegerType(), True) ]) df = spark.createDataFrame(data, schema=schema) df.show() # 数据库配置 prop = { "user": "root", "password": "root123", "driver": "com.mysql.jdbc.Driver" } # 将这10条数据插入数据库 df.write.jdbc('jdbc:mysql://192.168.127.186:3306/sparktest', 'student', 'append', prop) # 从数据库中读取所有数据 jdbcDF = spark.read \ .format("jdbc") \ .option("driver", "com.mysql.jdbc.Driver") \ .option("url", "jdbc:mysql://192.168.127.186:3306/sparktest") \ .option("dbtable", "student") \ .option("user", "root") \ .option("password", "root123") \ .load() jdbcDF.show() rdd_age = jdbcDF.rdd.map(lambda stu: stu.age) num = rdd_age.count() # 人数 sum_age = rdd_age.reduce(lambda age1, age2: age1+age2) # 年龄总和 print("age的平均值为:", sum_age / num)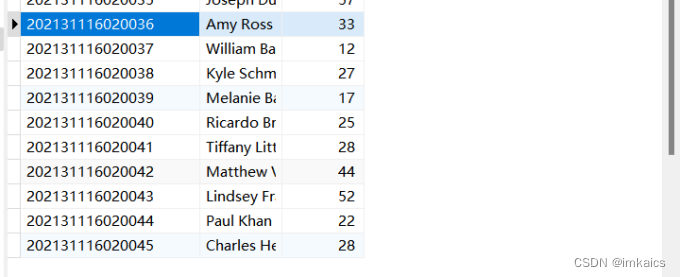















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









