







一、实验目的
- 熟练掌握pandas一维数组Series结构的使用
- 熟练掌握pandas时间序列对象的使用
- 熟练掌握pandas二维数组DataFrame结构的创建
二、实验内容
Part1. 基础Pandas练习
1. 基础Pandas使用练习
import pandas as pd
import matplotlib.pyplot as plt
# 设置输出结果列对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 自动创建从0开始的非负整数索引
s1 = pd.Series(range(1, 20, 5))
# 使用字典创建Series,使用键作为索引
s2 = pd.Series({'语文': 90, '数学': 92, 'Python': 98, '物理': 87, '化学': 92})
s1[3] = 17
s2['语文'] = 94
print("s1原始数据".ljust(20, '='))
print(s1)
print("对s1所有数据求绝对值".ljust(20, '='))
print(abs(s1))
print('s1所有的值加5'.ljust(20, '='))
print(s1 + 5)

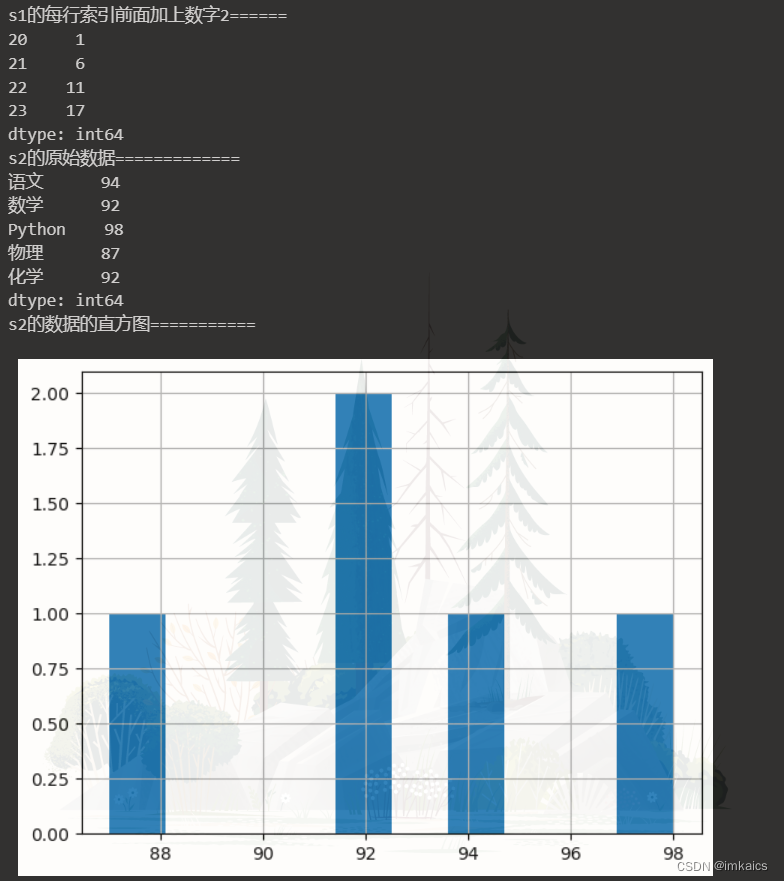
print('s1的每行索引前面加上数字2'.ljust(20, '='))
print(s1.add_prefix(2))
print("s2的原始数据".ljust(20, '='))
print(s2)
print("s2的数据的直方图".ljust(20, '='))
s2.hist()
plt.show()
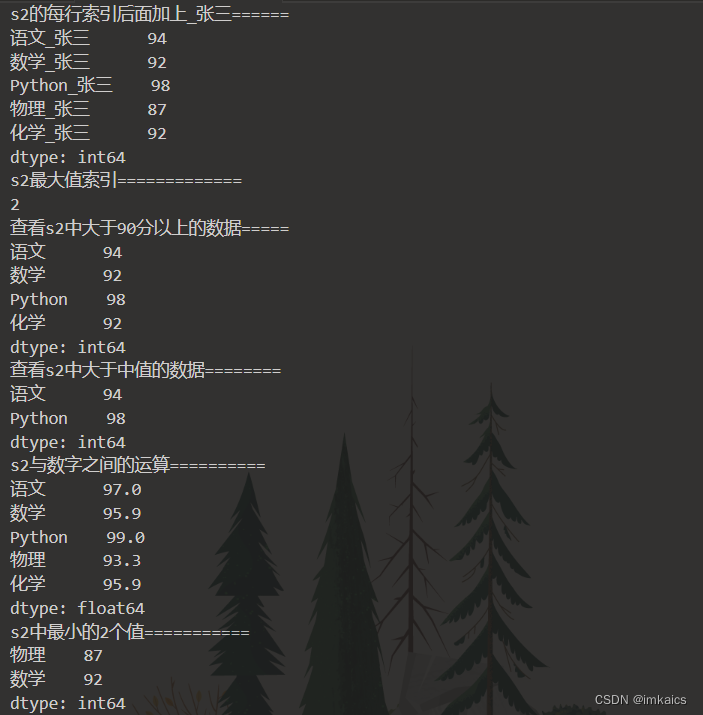
print("s2的每行索引后面加上_张三".ljust(20, '='))
print(s2.add_suffix('_张三'))
print("s2最大值索引".ljust(20, '='))
print(s2.argmax())
print("查看s2中大于90分以上的数据".ljust(20, '='))
print(s2[s2>90])
print("查看s2中大于中值的数据".ljust(20, '='))
print(s2[s2>s2.median()])
print("s2与数字之间的运算".ljust(20, '='))
print(round((s2**0.5)*10, 1))
print("s2中最小的2个值".ljust(20, '='))
print(s2.nsmallest(2))
# 两个等长的Series对象之间可以进行四则运算和幂运算
# 只对两个Series对象中都有的索引对应的值进行计算
# 非共同索引对应的值为NaN
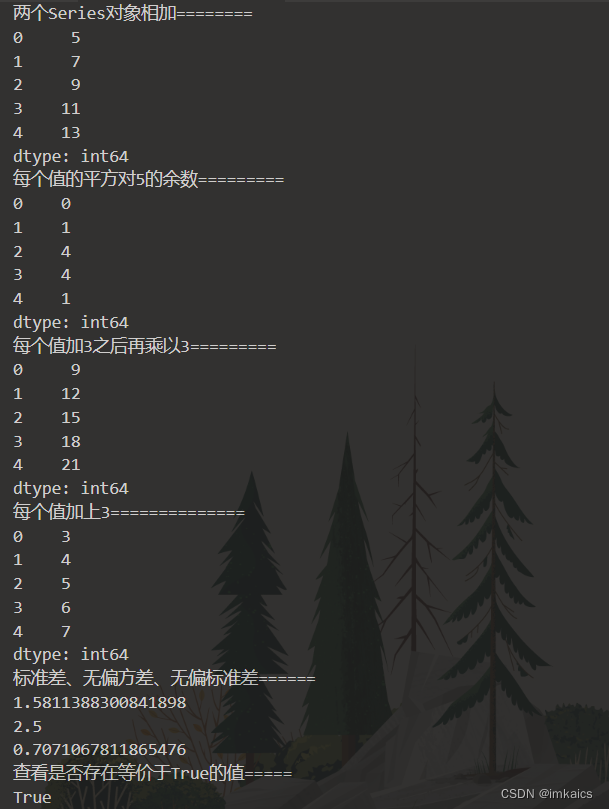
print("两个Series对象相加".ljust(20, '='))
print(pd.Series(range(5)) + pd.Series(range(5, 10)))
# pipe()方法可以实现函数链式调用的功能
print("每个值的平方对5的余数".ljust(20, '='))
print(pd.Series(range(5)).pipe(lambda x, y, z: (x**y)%z, 2, 5))
print("每个值加3之后再乘以3".ljust(20, '='))
print(pd.Series(range(5)).pipe(lambda x:x+3).pipe(lambda x:x*3))
# apply()方法用来对Series对象中的每个值进行函数的调用
print("每个值加上3".ljust(20, '='))
print(pd.Series(range(5)).apply(lambda x:x+3))
print("标准差、无偏方差、无偏标准差".ljust(20, '='))
print(pd.Series(range(5)).std())
print(pd.Series(range(5)).var())
print(pd.Series(range(5)).sem())
print("查看是否存在等价于True的值".ljust(20, '='))
print(any(pd.Series([3, 0, True])))
2. 总结并举例说明date_range()函数中时间间隔的表示方法
import pandas as pd
# start指定起始日期,end指定结束日期,periods指定产生的数据数量
# freq指定间隔,D表示天, W表示周, H表示小时
# M表示月末最后一天,MS表示月初第一天
# T 表示分钟,Y表示年末最后一天,YS表示年初第一天
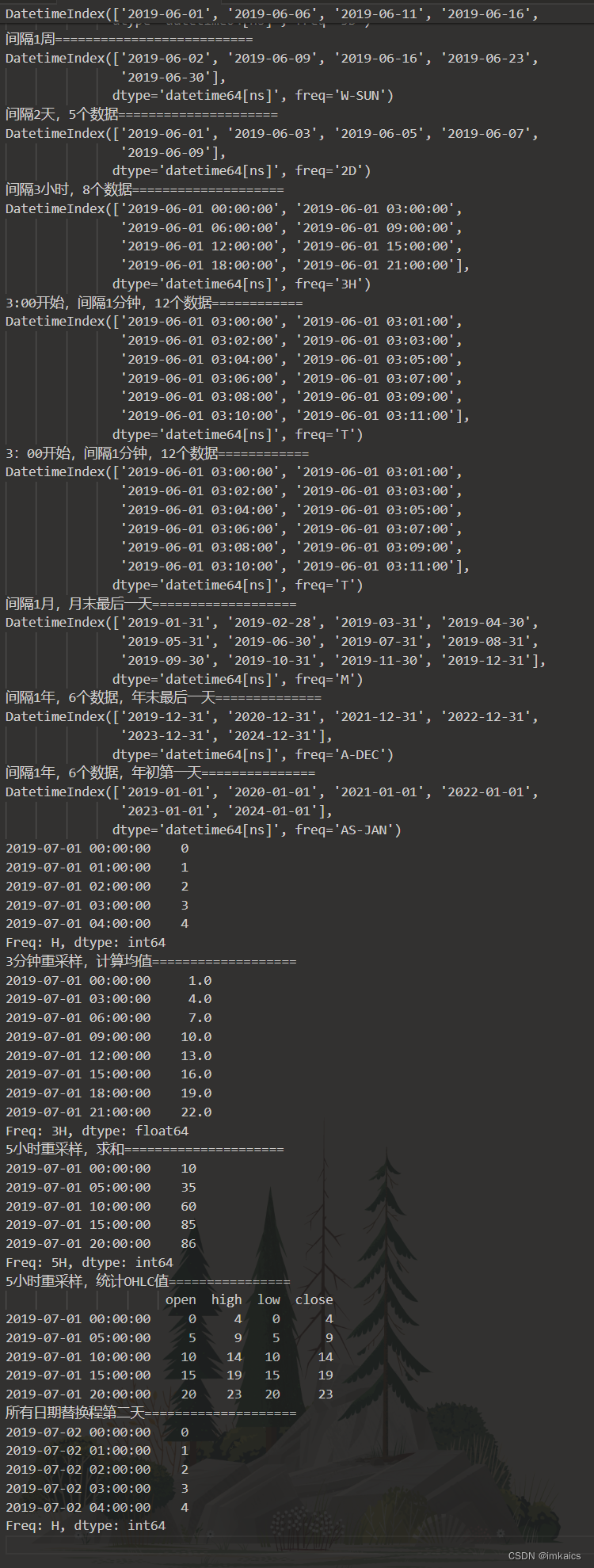
print("间隔5天".ljust(30, '='))
print(pd.date_range(start="20190601", end="20190630", freq="5D"))
print("间隔1周".ljust(30, '='))
print(pd.date_range(start="20190601", end="20190630", freq="W"))
print("间隔2天,5个数据".ljust(30, '='))
print(pd.date_range(start="20190601", freq="2D", periods=5))
print("间隔3小时,8个数据".ljust(30, '='))
print(pd.date_range(start="20190601", freq="3H", periods=8))
print("3:00开始,间隔1分钟,12个数据".ljust(30, '='))
print(pd.date_range(start="201906010300", freq="T", periods=12))
print("3:00开始,间隔1分钟,12个数据".ljust(30, '='))
print(pd.date_range(start="201906010300", freq='T', periods=12))
print("间隔1月,月末最后一天".ljust(30, '='))
print(pd.date_range(start="20190101", end="20191231", freq='M'))
print("间隔1年,6个数据,年末最后一天".ljust(30, '='))
print(pd.date_range(start="20190101", freq='A', periods=6))
print("间隔1年,6个数据,年初第一天".ljust(30, '='))
print(pd.date_range(start="20190101", freq='AS', periods=6))
# 使用日期时间做索引,创建Series对象
data = pd.Series(index=pd.date_range(start="20190701", freq='H', periods=24),
data = range(24))
print(data[:5])
print("3分钟重采样,计算均值".ljust(30, '='))
print(data.resample('3H').mean())
print("5小时重采样,求和".ljust(30, '='))
print(data.resample('5H').sum())
# OHLC分别表示OPEN、HIGH、LOW、CLOSE
print("5小时重采样,统计OHLC值".ljust(30, '='))
print(data.resample('5H').ohlc())
print("所有日期替换程第二天".ljust(30, '='))
data.index = data.index + pd.Timedelta(1, 'D')
print(data[:5])
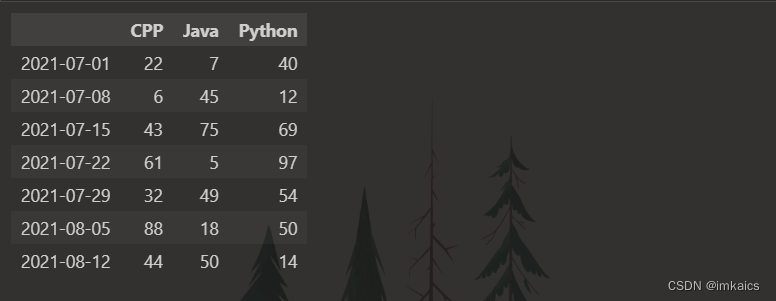
3. 以时间序列做索引,用DataFrame数组模拟一组模拟考试成绩,时间及时间间隔、科目自拟,成绩随机生成。
import pandas as pd
import random
data_index = pd.date_range(start='202107010000', freq='7D', periods=7) # 间隔7天,7条数据
data_columns = ['CPP', 'Java', 'Python'] # 3个科目
scores = {one_index:{} for one_index in data_index}
for one_index in data_index:
for col in data_columns:
scores[one_index][col] = random.randint(0, 100)
pd.DataFrame(scores).T
Part2 使用Pandas对Excel进行相关操作
下面所用的xlsx文件下载地址:https://wwd.lanzouq.com/ijOX81w8a64h
4. 练习并写出代码的运行结果
import pandas as pd
# 设置列对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 读取全部数据,使用默认索引
df = pd.read_excel('./超市营业额2.xlsx')
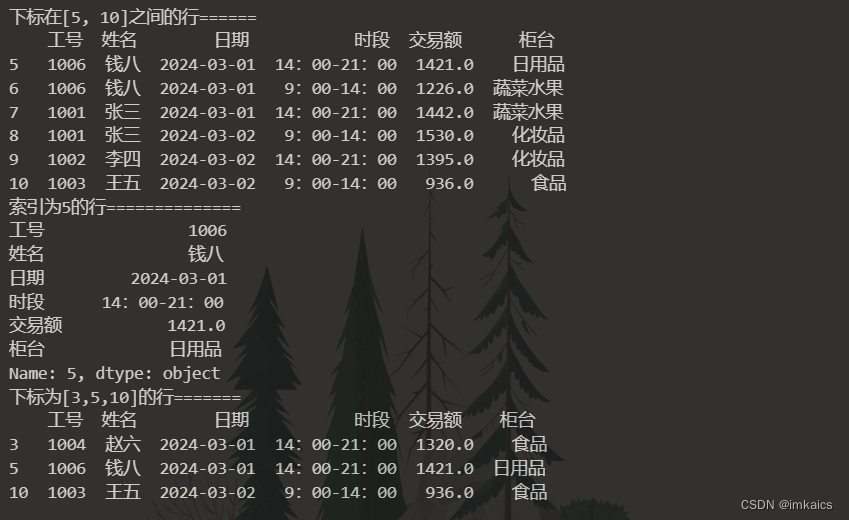
print("下标在[5, 10]之间的行".ljust(20, '='))
# 对行进行切片,左闭右开
print(df[5:11])
# iloc使用数字作索引
print("索引为5的行".ljust(20, '='))
print(df.iloc[5])
print("下标为[3,5,10]的行".ljust(20, '='))
print(df.iloc[[3, 5, 10], :])
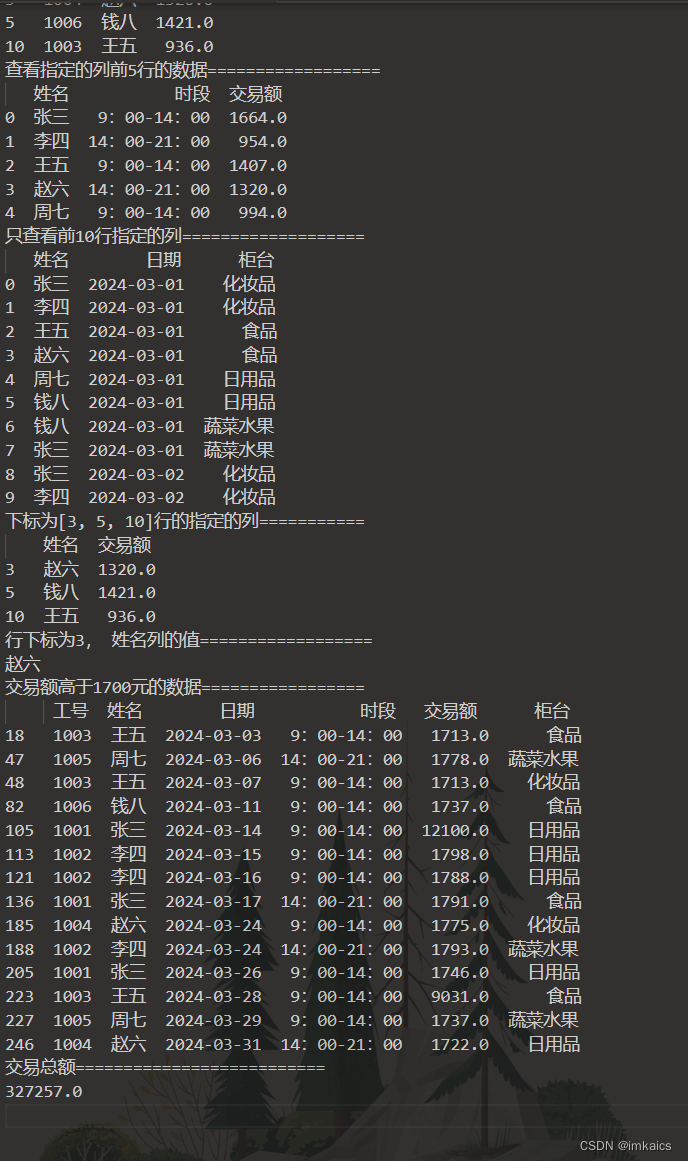
print("行下标为[3, 5, 10],列下标为[0, 1, 4]".ljust(30, '='))
print(df.iloc[[3, 5, 10], [0, 1, 4]])
print("查看指定的列前5行的数据".ljust(30, '='))
print(df[["姓名", "时段", "交易额"]][:5])
print("只查看前10行指定的列".ljust(30, '='))
print(df[:10][["姓名", "日期", "柜台"]])
print("下标为[3, 5, 10]行的指定的列".ljust(30, '='))
print(df.loc[[3, 5, 10], ["姓名", "交易额"]])
print("行下标为3, 姓名列的值".ljust(30, '='))
print(df.at[3, "姓名"])
print("交易额高于1700元的数据".ljust(30, '='))
print(df[df["交易额"] > 1700])
print("交易总额".ljust(30, '='))
print(df["交易额"].sum())
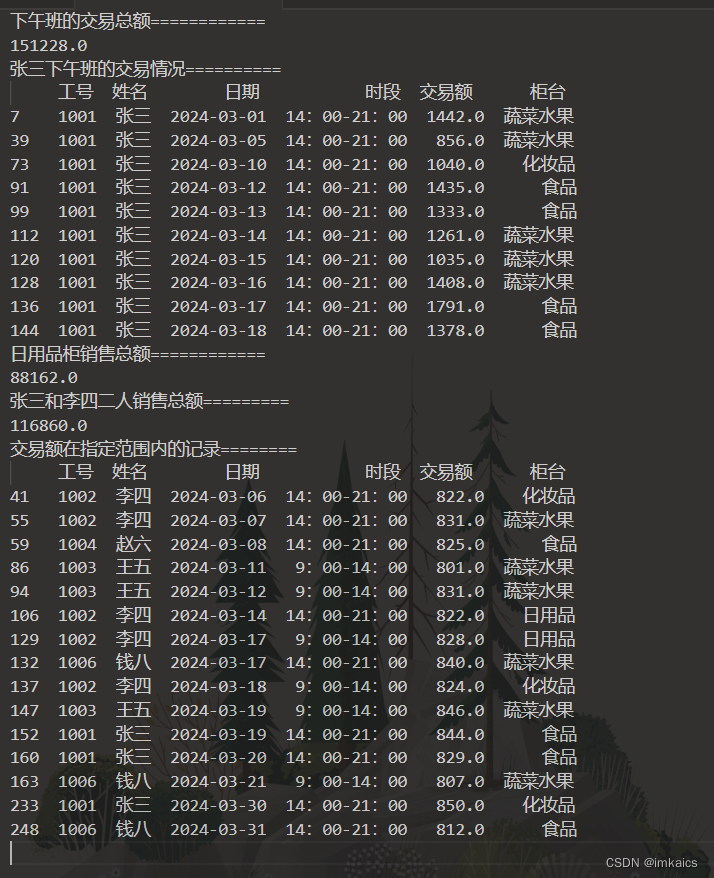
print("下午班的交易总额".ljust(20, '='))
print(df[df["时段"]=="14:00-21:00"]["交易额"].sum())
print("张三下午班的交易情况".ljust(20, '='))
print(df[(df.姓名=="张三")& (df.时段=="14:00-21:00")][:10])
print("日用品柜销售总额".ljust(20, '='))
print(df[df['柜台']=="日用品"]["交易额"].sum())
print("张三和李四二人销售总额".ljust(20, '='))
print(df[df["姓名"].isin(["张三", "李四"])]['交易额'].sum())
print("交易额在指定范围内的记录".ljust(20, '='))
print(df[df["交易额"].between(800, 850)])
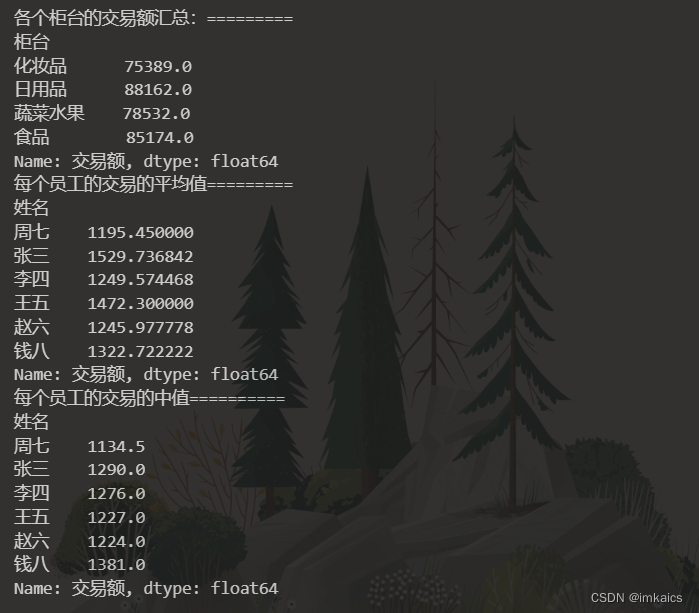
5. 汇总各柜台的销售总额;统计每个员工交易额平均值;计算每个员工交易额的中值
import pandas as pd
# 设置列对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 读取全部数据,使用默认索引
df = pd.read_excel('./超市营业额2.xlsx')
print("各个柜台的交易额汇总:".ljust(20, "="))
print(df["交易额"].groupby(df["柜台"]).sum())
print("每个员工的交易的平均值".ljust(20, "="))
print(df["交易额"].groupby(df["姓名"]).mean())
print("每个员工的交易的中值".ljust(20, "="))
print(df["交易额"].groupby(df["姓名"]).median())
6. 将“超市营业额2.xlsx”中上浮30%后,仍小于500,大于3000的数值,替换为交易额的均值。
import pandas as pd
# 设置列对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 读取全部数据,使用默认索引
df = pd.read_excel('./超市营业额2.xlsx')
# df["上浮30%"] = df["交易额"] * 1.3
df["交易额"] = df["交易额"].apply(lambda x: x if (x >= 500 and x <= 3000) else df["交易额"].mean())
df.to_excel("./超市营业额2均值替代异常值.xlsx", index=False)
7. 找到“超市营业额2.xlsx”中的缺失值,用:(1)缺失值所在的用户的交易额均值替换缺失值;(2)使用整体均值的80%填充缺失值
import pandas as pd
# 设置列对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 读取全部数据,使用默认索引
df = pd.read_excel('./超市营业额2.xlsx')
# (1)缺失值所在的用户的交易额均值替换缺失值
df_user_mean = df.groupby('工号')['交易额'].transform('mean') # 计算每个用户的交易额均值
df_new1 = df.fillna(value=df_user_mean, inplace=False) # 使用用户交易额均值替换缺失值
# (2)使用整体均值的80%填充缺失值
overall_mean = df['交易额'].mean() # 计算整体交易额均值
fill_value = overall_mean * 0.8 # 计算整体均值的80%
df_new2 = df.fillna(value=fill_value, inplace=False) # 使用整体均值的80%替换缺失值
print("使用用户交易额均值替换后的数据:")
print(df_new1)
df_new1.to_excel("./超市营业额2所在用户的均值替换缺失值.xlsx", index=False)
print("\n使用整体均值的80%替换后的数据:")
print(df_new2)
df_new2.to_excel("./超市营业额2整体均值80%替换缺失值.xlsx", index=False)















 1489
1489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









