







文章目录
总述
factorization machines 提出了将特征进行交叉,以达到从特征中学习到更多有价值的信息。它的思想是为每个特征学习一个隐向量,具体请移步因子分解机。本文主要记录使用 MovieLens 数据集复现 FM 的过程。
数据预处理
为了更好地观察到数据处理后的状态,我们使用 jupter notebook 处理数据。
首先引入需要的包:
import numpy as np
import pandas as pd
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
处理 users 数据
- 将用户数据读入
users = pd.read_table('../../dataset/ml-1m/users.dat', sep='::', header=None, engine='python', encoding='utf-8').to_numpy()
- 邮编取前 3 位
for user in users:
user[4] = int(user[4][0:3]) # 取邮编的前3位
- 将用户的 userId, gender, age, occupation, zipCode Label Encoding 编码
le = LabelEncoder()
for i in range(users.shape[1]):
users[:, i] = le.fit_transform(users[:, i])
处理结果:

处理用户评分数据
- 读入用户评分数据
ratings = pd.read_table('../../dataset/ml-1m/ratings.dat', sep='::', header=None, engine='python', encoding='utf-8').to_numpy()[:, :3]
- 划分正负样本
for i in range(len(ratings)):
ratings[i][2] = 1 if ratings[i][2] > 2 else 0
- 将数据 label encoding 编码
le = LabelEncoder()
for i in range(ratings.shape[1]):
ratings[:, i] = le.fit_transform(ratings[:, i])
处理结果:
将用户数据和评分数据合并
- 合并用户数据和评分数据
unames = ['userId', 'gender', 'age', 'occupation', 'zipCode']
rnames = ['userId', 'movieId', 'rating']
users = pd.DataFrame(users, columns=unames)
ratings = pd.DataFrame(ratings, columns=rnames)
data = pd.merge(users, ratings, on=['userId'])
处理结果:
- 写入文件
data.reset_index(drop=True, inplace=True)
data.to_csv('../data/processed.csv', index=0)
写入文件后的结果:
数据处理(dataset)
import numpy as np
import pandas as pd
from torch.utils.data import Dataset
from sklearn.preprocessing import OneHotEncoder
class Dataset(Dataset):
def __init__(self):
data = pd.read_csv("/workspace/myFM/data/processed.csv", sep=',',engine='python').to_numpy()
self.x, self.y = self._process_data(data)
def __len__(self):
return len(self.y)
def __getitem__(self, index):
return (self.x[index], self.y[index])
def _process_data(self, data):
y = data[:, 6]
x = np.delete(data, -1, axis=1) # 将评分列删除
return x, y
def get_shape(self):
return self.x.shape
def get_vocabs_size(self): # 获得每个特征的类别数
return np.max(self.x, axis=0) + 1
模型
import torch
import numpy as np
class FM(torch.nn.Module):
'''
@param n: the number of features
@param k: the dim of latent vector
@param vocabs_size: the size of every vocabulary
'''
def __init__(self, n, k, vocabs_size):
super(FM, self).__init__()
self.n = n
self.linearEmbedList = torch.nn.ModuleList([torch.nn.Embedding(vocab_size, 1)
for vocab_size in vocabs_size])
self.interEmbedList = torch.nn.ModuleList()
for i in range(n):
self.interEmbedList.append(torch.nn.Embedding(vocabs_size[i], k))
self.sigmoid = torch.nn.Sigmoid()
'''
@param x: (batch_size * n)
'''
def forward(self, x):
linear_list = []
inter_list = []
for i in range(self.n):
linear_list.append(self.linearEmbedList[i](x[:, i])) # look up
inter_list.append(self.interEmbedList[i](x[:, i]))
linear = np.sum(linear_list, axis=0) # (bs * 1)
sum_square = torch.square(np.sum(inter_list, axis=0)) # (bs * k)
square_sum = np.sum([torch.square(item) for item in inter_list], axis=0) # (bs * k)
inter = 0.5 * torch.sum(sum_square - square_sum, dim=1, keepdim=True) # (bs * 1)
logit = self.sigmoid(linear.reshape((-1, 1)) + inter) # (bs * 1)
return logit
训练 & 测试
import torch
import numpy as np
from torch.utils.data import DataLoader
from sklearn import metrics
class Train(object):
def __init__(self, model):
self.batch_size = 512
self.epochs = 20
self._model = model
self._optimizer = torch.optim.Adam(self._model.parameters(), lr=0.0005, weight_decay=1e-3)
self._loss_func = torch.nn.BCELoss()
def train(self, train_dataset, test_dataset):
train_data_loader = DataLoader(dataset=train_dataset, batch_size=self.batch_size, shuffle=True, num_workers=2, drop_last=True)
test_data_loader = DataLoader(dataset=test_dataset, batch_size=self.batch_size, shuffle=True, num_workers=2, drop_last=True)
self._model.train()
if self._use_cuda():
self._model.cuda()
for epoch in range(self.epochs):
train_loss = self._train_an_epoch(train_data_loader, epoch)
test_loss, auc = self._test_an_epoch(test_data_loader)
print('epoch:%2d/%d train_loss:%f test_loss:%f auc:%.3f'% (epoch + 1, self.epochs, train_loss, test_loss, auc))
# 训练一个 epoch
def _train_an_epoch(self, data_loader, epoch):
running_loss = 0.0
for batch, (x, y) in enumerate(data_loader):
if self._use_cuda():
x, y = x.cuda(), y.cuda()
loss = self._train_sigle_batch(x, y)
running_loss += loss
# if batch % 1000 == 999:
# print('epoch:%2d/%d batch:%d loss: %.3f' % (epoch + 1, self.epochs, batch / 1000 + 1, running_loss / 1000))
# running_loss = 0.0
return running_loss / (batch + 1)
# 训练一个 batch
def _train_sigle_batch(self, x, y):
self._optimizer.zero_grad()
y_predict = self._model(x)
loss = self._loss_func(y_predict.squeeze(1), y.float())
loss.backward()
self._optimizer.step()
return loss.item()
# 测试
def _test_an_epoch(self, test_data_loader):
self._model.eval()
running_loss = 0.0
ys = []
y_predicts = []
for batch, (x, y) in enumerate(test_data_loader):
if self._use_cuda():
x, y = x.cuda(), y.cuda()
y_predict = self._model(x)
loss = self._loss_func(y_predict.float(), y.unsqueeze(1).float())
running_loss += loss.item()
ys = np.append(ys, y.cpu().detach().numpy(), axis=0)
y_predicts = np.append(y_predicts, y_predict.squeeze(1).cpu().detach().numpy(), axis=0)
epoch_mean_loss = running_loss / (batch + 1)
auc = metrics.roc_auc_score(ys, y_predicts)
return epoch_mean_loss, auc
def _use_cuda(self):
return torch.cuda.is_available()
main 文件
from dataset.dataset import Dataset
from torch.utils.data import random_split
from model.fm import FM
from train.fm_train import Train
import os
if __name__ == "__main__":
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
print('data loading...')
dataset = Dataset()
print('data loading finished')
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
print('training...')
_, n = dataset.get_shape()
vocabs_size = dataset.get_vocabs_size()
fm = FM(n, 16, vocabs_size)
trainer = Train(model=fm)
trainer.train(train_dataset, test_dataset)
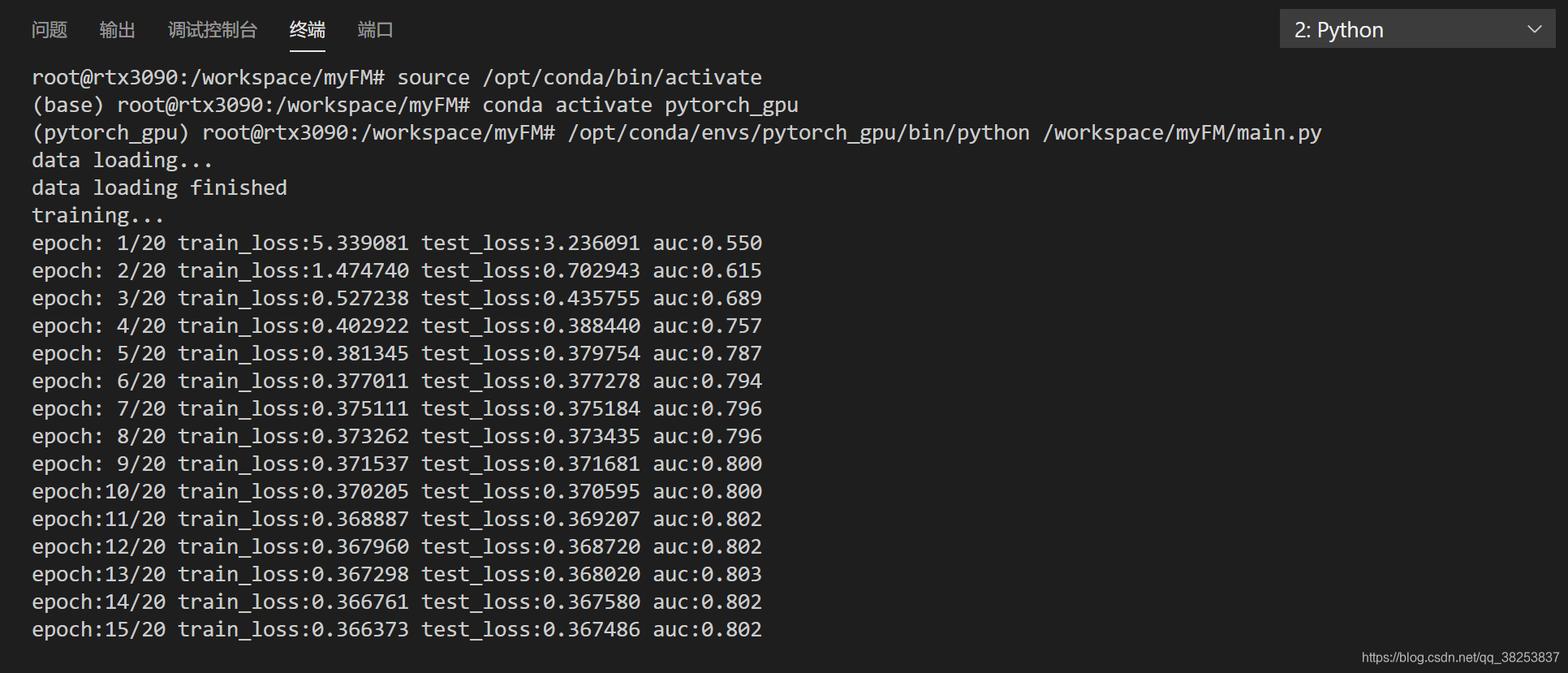
代码运行结果

















 59
59

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









