







一、前言
高阶特征和低阶特征的学习都非常的重要。 推荐模型很多,基本上是从最简单的线性模型(LR), 到考虑低阶特征交叉的FM, 到考虑高度交叉的神经网络,再到两者都考虑的W&D组合模型。 这样一串联就会发现前面这些模型存在的问题了:
1、简单的线性模型虽然简单,同样这样是它的不足,就是限制了模型的表达能力,随着数据的大且复杂,这种模型并不能充分挖掘数据中的隐含信息,且忽略了特征间的交互,如果想交互,需要复杂的特征工程。
2、FM模型考虑了特征的二阶交叉,但是这种交叉仅停留在了二阶层次,虽然说能够进行高阶,但是计算量和复杂性一下子随着阶数的增加一下子就上来了。所以二阶是最常见的情况,会忽略高阶特征交叉的信息
3、DNN,适合天然的高阶交叉信息的学习,但是低阶的交叉会忽略掉
那么如果把上面这几种结构组合一下子,是不是效果会强大一些呢? 所以W&D模型在这个思路上进行了一个伟大的尝试,把简单的LR模型和DNN模型进行了组合, 使得模型既能够学习高阶组合特征,又能够学习低阶的特征模式,但是W&D的wide部分是用了LR模型, 这一块依然是需要一些经验性的特征工程的,且Wide部分和Deep部分需要两种不同的输入模式, 这个在具体实际应用中需要很强的业务经验。
所以DeepFM看这个名字也能够看出来,就是Deep+FM的组合思路
二、DeepFM模型
DeepFM的模型吧, 长下面这个样子:

DeepFM的运算过程也比较简单, 左边的FM和右边的DNN共享相同的Embedding层的输入, 左侧的FM对不同特征域的Embedding进行了两两交叉(这里的Embedding向量当成了原FM的特征隐向量), 右边的DNN对特征Embedding进行了深度交叉, 最后将FM的输出与Deep部分的输出一起送入最后的输出层,参与最后的目标拟合
1、输入和Embedding部分
关于输入,包括离散的分类特征域(如性别、地区等)和连续的数值特征域(如年龄等)。分类特征域一般通过one-hot或者multi-hot(如用户的浏览历史)进行处理后作为输入特征;数值特征域可以直接作为输入特征,也可以进行离散化进行one-hot编码后作为输入特征。
对于每一个特征域,需要单独的进行Embedding操作,因为每个特征域几乎没有任何的关联,如性别和地区。而数值特征无需进行Embedding。
2、FM部分
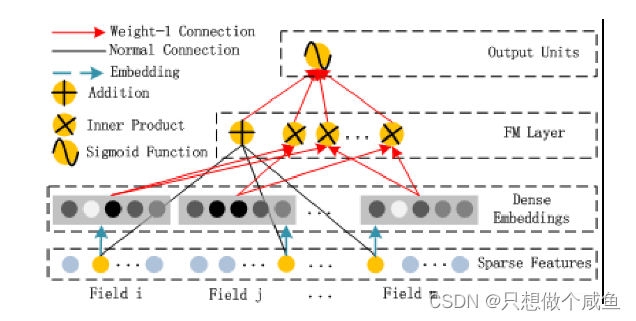
FM负责特征之间的低阶交互过程,FM的输出是Addition单元和Inner Product units的加和, Addition单元反映1阶特征各自的影响, 而Inner product代表2阶特征交互的影响。
3、Deep部分
依然是一个DNN,负责学习高阶特征之间的交互

原始的特征通过Embedding层之后,会从高维稀疏性转成低维稠密性的特征, 这时候concat,就可以直接作为DNN的输入
如果隐向量的维度是k kk维的话,这里会是一个n × m × k的三维矩阵,作为神经网络的输入。神经网络的前向传播公式:

这里的∣ H ∣表了神经网络的层数。
4、其他项
特征交叉或者交互信息,这个玩意到底是个啥呢?
在CTR预测中, 学习用户点击行为背后的特征隐式交互非常重要。
二阶特征交互原来是这个意思:
通过对主流应用市场的研究,我们发现人们经常在用餐时间下载送餐的应用程序,这就表明应用类别和时间戳之间的(阶数-2)交互作用是CTR预测的一个信号。
三阶或者高阶特征交互是这个意思:
我们还发现男性青少年喜欢射击游戏和RPG游戏,这意味着应用类别、用户性别和年龄的(阶数-3)交互是CTR的另一个信号。
根据谷歌的W&D模型的应用, 作者发现同时考虑低阶和高阶的交互特征,比单独考虑其中之一有更多的改进
三、torch代码实现
1、FM部分

 二阶代码中用最后的形式
二阶代码中用最后的形式
class FM(nn.Module):
"""FM part"""
def __init__(self, latent_dim, fea_num):
"""
latent_dim: 各个离散特征隐向量的维度 8
input_shape: 这个最后离散特征embedding之后的拼接和dense拼接的总特征个数 221
"""
super(FM, self).__init__()
self.latent_dim = latent_dim
# 定义三个矩阵, 一个是全局偏置,一个是一阶权重矩阵, 一个是二阶交叉矩阵,注意这里的参数由于是可学习参数,需要用nn.Parameter进行定义
self.w0 = nn.Parameter(torch.zeros([1, ])) #1,
self.w1 = nn.Parameter(torch.rand([fea_num, 1])) #221*1
self.w2 = nn.Parameter(torch.rand([fea_num, latent_dim])) #221*8
def forward(self, inputs): #32*221
# 一阶交叉
first_order = self.w0 + torch.mm(inputs, self.w1) # (samples_num, 1) w1=221*1 fin 32*1
# 二阶交叉 这个用FM的最终化简公式
second_order = 1 / 2 * torch.sum(
torch.pow(torch.mm(inputs, self.w2), 2) - torch.mm(torch.pow(inputs, 2), torch.pow(self.w2, 2)),
dim=1,
keepdim=True
) # (samples_num, 1) 32*8 行求和后 32*1
return first_order + second_order![]()
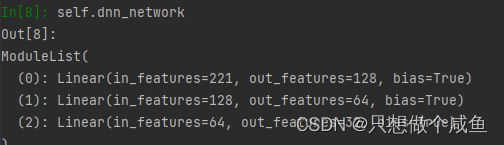
2、DNN部分
class Dnn(nn.Module):
"""Dnn part"""
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout = 0.
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList(
[nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x
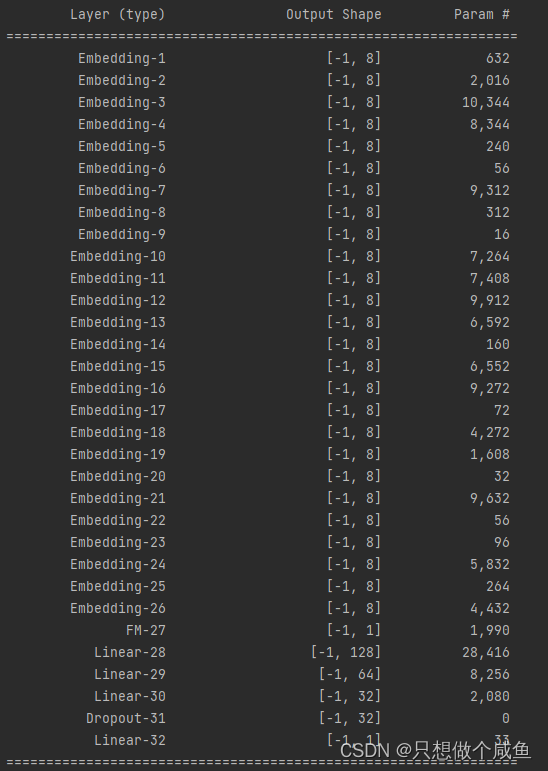
3、DeepFM
class DeepFM(nn.Module):
def __init__(self, feature_columns, hidden_units, dnn_dropout=0.):
"""
DeepFM:
:param feature_columns: 特征信息, 这个传入的是fea_cols
:param hidden_units: 隐藏单元个数, 一个列表的形式, 列表的长度代表层数, 每个元素代表每一层神经元个数
"""
super(DeepFM, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
# 这里要注意Pytorch的linear和tf的dense的不同之处, 前者的linear需要输入特征和输出特征维度, 而传入的hidden_units的第一个是第一层隐藏的神经单元个数,这里需要加个输入维度
self.fea_num = len(self.dense_feature_cols) + len(self.sparse_feature_cols) * self.sparse_feature_cols[0][
'embed_dim'] #13+26*8 221
hidden_units.insert(0, self.fea_num) #[221, 128, 64, 32]
self.fm = FM(self.sparse_feature_cols[0]['embed_dim'], self.fea_num)
self.dnn_network = Dnn(hidden_units, dnn_dropout)
self.nn_final_linear = nn.Linear(hidden_units[-1], 1) #32*1
def forward(self, x):
dense_inputs, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long() # 转成long类型才能作为nn.embedding的输入
sparse_embeds = [self.embed_layers['embed_' + str(i)](sparse_inputs[:, i]) for i in
range(sparse_inputs.shape[1])]
sparse_embeds = torch.cat(sparse_embeds, dim=-1) #32*208
# 把离散特征和连续特征进行拼接作为FM和DNN的输入
x = torch.cat([sparse_embeds, dense_inputs], dim=-1)#32*211
# Wide
wide_outputs = self.fm(x) #32*1
# deep
deep_outputs = self.nn_final_linear(self.dnn_network(x)) #32*1
# 模型的最后输出
outputs = F.sigmoid(torch.add(wide_outputs, deep_outputs)) #32*1
return outputs完整的架构图
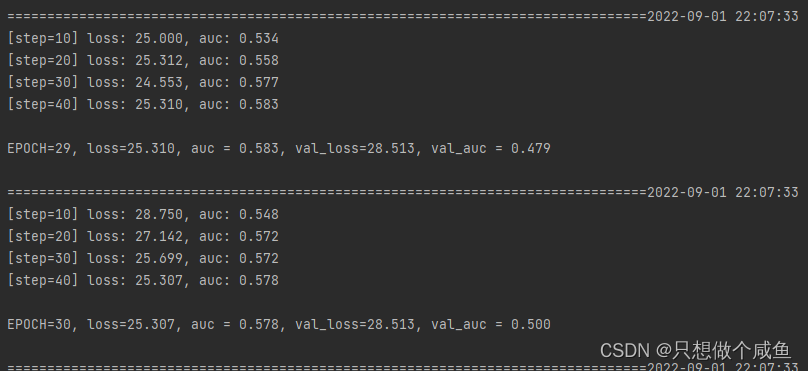
4、模型训练
5、 模型的保存和使用
我们训练好了模型,
怎么存?
存后又怎么用呢?
下面简单的整理下,这里以训练完的DeepFM模型为例
(1)模型的保存
torch.save(model, '../model/DeepFM.pkl')可以看到保存的模型在我们创建的文件里

(2)模型的使用
net_clone = torch.load('../model/DeepFM.pkl')是的没错,又是一行,下面时把提取出来的
y_pred_probs = model(torch.tensor(test_x).float())
y_pred = torch.where(y_pred_probs>0.5, torch.ones_like(y_pred_probs), torch.zeros_like(y_pred_probs))
print(y_pred)
总结
根据上面的分析,可以发现DeepFM还是一个非常重要的模型的,既不需要预训练,又同时考虑了高阶交叉和低阶交互, 且省去了复杂的特征工程实现了一个end-to-end的效果。
那么它真的就完美了吗?
肯定不是呀,要不然就不会再有后面的一些改进了,DeepFM也只是给出了提升FM模型的一种思路而已, 其实模型对于高阶特征和高阶特征的交互学习探索, 还有很多的思路, 下面的NFM就提供了另外的一种组合思路。 它重点是考虑了FM本身的一种限制,然后对这种限制进行了突破, 通过加入特征池化层, 把FM融入到了神经网络当中使其成为了一个整体结构, 使得FM与DNN进行了一种无缝的衔接, 又进行了串联起来。














 1967
1967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









