









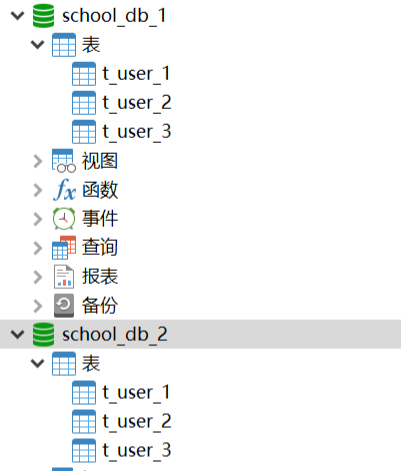
1、数据库创建分表分库
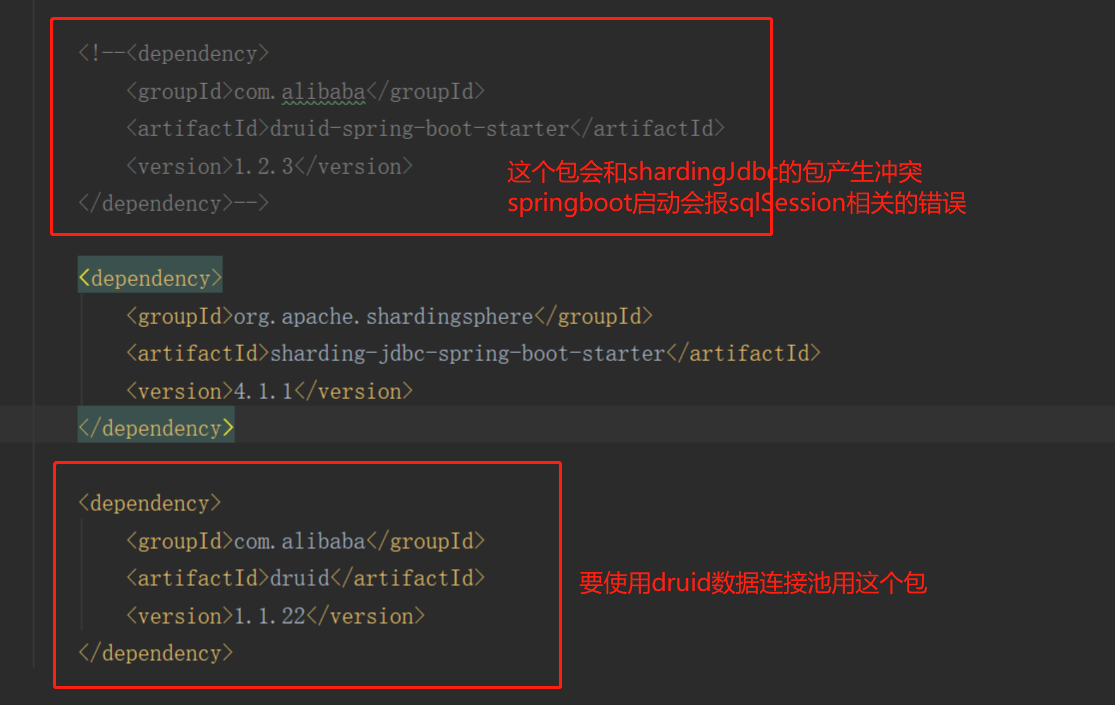
2、项目pom中引入Sharding-JDBC需要用到的相关依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>这里相关依赖包的引入有个坑需要注意下:
3、配置文件application.yml加上sharding-jdbc相关的参数配置
(1)水平分表配置
server:
port: 8066
spring:
application:
name: sharding-jdbc-service
shardingsphere:
props: #开启shardingsphere执行sql的日志打印
sql:
show: true
datasource:
names: m1 #自定义数据源名称
m1:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.200.100:3306/school_db_1?useSSL=false&useUnicode=true&characterEncoding=utf-8&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai
username: chenty
password: fedcty126
sharding:
tables:
t_user: #指定t_user表分布的情况,配置分库,对应上面配置的数据源m1,m2,配置分表 m1.t_user_1,m1.t_user_2,m1.t_user_3
actual-data-nodes: m1.t_user_$->{1..3}
key-generator: #指定主键生成策略,使用雪花算法进行生成,如果使用雪花算法主键则需要使用bigInt类型,实体类主键需要使用long类型
column: id
type: SNOWFLAKE #
table-strategy: #指定分表策略和分表算法,根据id%分表总数来进行分表
inline:
sharding-column: id
algorithm-expression: t_user_$->{id % 3}
mybatis:
mapper-locations: classpath*:mapper/*.xml
configuration:
map-underscore-to-camel-case: true(2)水平分库分表配置
server:
port: 8066
spring:
application:
name: sharding-jdbc-service
shardingsphere:
props: #开启shardingsphere执行sql的日志打印
sql:
show: true
datasource:
names: m1,m2 #自定义数据源名称,可定义多个数据源
m1:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.200.100:3306/school_db_1?useSSL=false&useUnicode=true&characterEncoding=utf-8&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai
username: chenty
password: fedcty126
m2:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.200.100:3306/school_db_2?useSSL=false&useUnicode=true&characterEncoding=utf-8&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai
username: chenty
password: fedcty126
sharding:
tables:
t_user: #指定t_user表分布的情况,配置分库,对应上面配置的数据源m1,m2,配置分表 m1.t_user_1,m1.t_user_2,m1.t_user_3
actual-data-nodes: m$->{1..2}.t_user_$->{1..3}
key-generator: #指定主键生成策略,使用雪花算法进行生成,如果使用雪花算法主键则需要使用bigInt类型
column: id
type: SNOWFLAKE
table-strategy: #指定分表策略和分表算法,根据id%分表总数来进行分表
inline:
sharding-column: id
algorithm-expression: t_user_$->{id % 3 + 1}
database-strategy: #指定分库策略和分库算法,根据id%分库总数来进行分库
inline:
sharding-column: id
algorithm-expression: m$->{id % 2 + 1}
mybatis:
mapper-locations: classpath*:mapper/*.xml
configuration:
map-underscore-to-camel-case: true4、创建好数据库操作的相关业务类进行测试,我这里就简单进行下测试
(1)插入数据
sharding-jdbc会根据配置文件中的分库分表策略插入数据

(2)查询数据
sharding-jdbc会根据配置文件中的分库分表策略查询数据


有问题和建议欢迎大家留言评论,谢谢~















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









