







创建k-近邻算法分类器
def classify0(inX,dataSet,labels,k):
## inX:用于分类的输入向量
## dataSet:输入的训练样本集
## labels:训练样本标签
## k:选择的近邻数目
dataSetSize=dataSet.shape[0] ##样本集的数目
diffMat=tile(inX,(dataSetSize,1))-dataSet ##输入向量与训练样本相减
sqDiffMat=diffMat**2 ##两个样本点之间的距离的平方
sqDistance=sqDiffMat.sum(axis=1) ##所有样本点之间距离的平方相加
distance=sqDistance**0.5 ##所有样本点之间距离的平方和开根号
sorted_d=distance.argsort() ##对其进行排序
classCount={
}
for i in range(k):
votel=labels[sorted_d[i]] ##距离从小到大的样本点对应类别
classCount[votel]=classCount.get(votel,0)+1 ##该类别的数目加1
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) ##排序
return sortedClassCount[0][0] ##选取第一个即为分类结果
读取约会数据
数据存放在一个名为datingTestSet2.txt的文件中,每个样本数据占据一行,共1000行,每行包含三个特征。
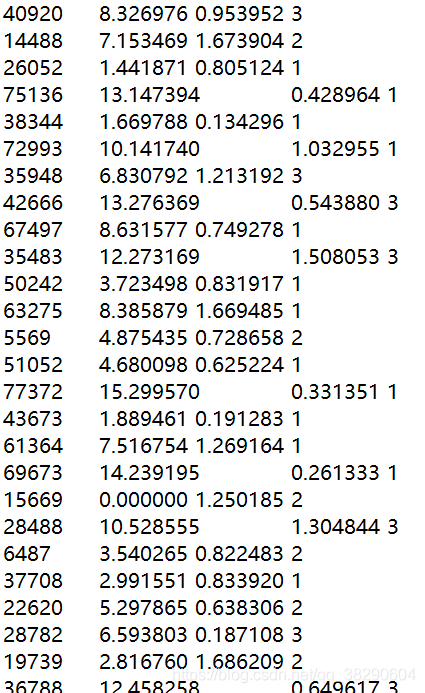
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
numberarray 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









