







目录
🍟 简介
YOLOv5训练时,模型初始化报错RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.
🍗报错内容
Traceback (most recent call last):
File "train.py", line 449, in <module>
train(hyp, opt, device, tb_writer)
File "train.py", line 68, in train
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc).to(device) # create
File "/data/yolov5/models/yolo.py", line 85, in __init__
self._initialize_biases() # only run once
File "/data/yolov5/models/yolo.py", line 143, in _initialize_biases
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.详细报错内容如下:
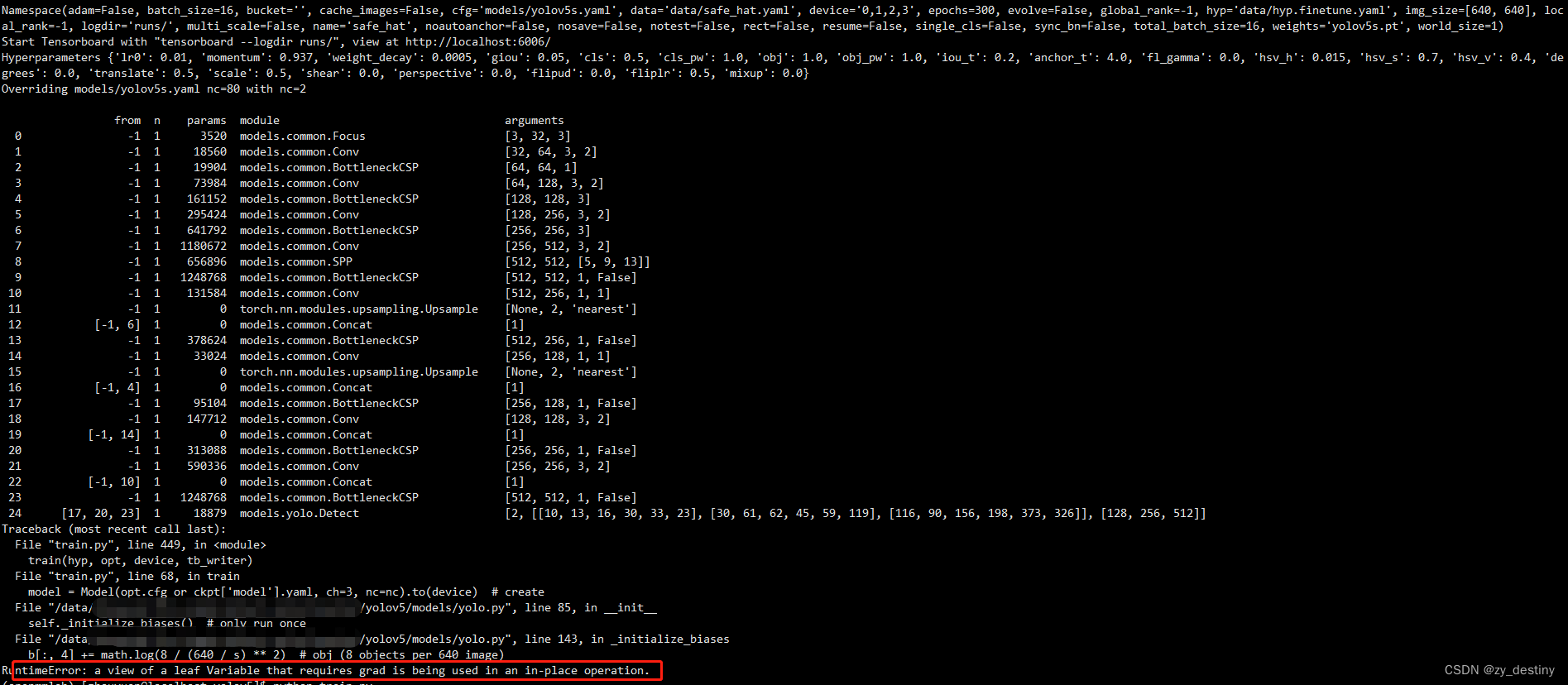
🍖原因分析
这个错误提示表示,一个需要梯度的变量的视图正在使用原地操作。这意味着您正在尝试在一个变量上进行某些操作,而这个变量是不能更改的。在这种情况下,您应该将变量复制到新的变量上,然后对新变量进行操作。
这个错误通常出现在使用PyTorch进行反向传播计算时。它意味着在计算梯度时,某个变量已经被就地(inplace)操作修改了,导致梯度计算出错。
解决这个问题的方法是避免使用就地操作。
- 具体而言,如果要对一个变量进行操作,请使用它的副本进行操作,并将结果赋值给原始变量。
- 另外,也可以使用torch.no_grad()来避免计算梯度。
这是关于PyTorch反向传播计算中的一个常见错误。在PyTorch中,很多操作都支持就地操作inplace) ,比如tensor.add(1)会将tensor的值加1并直接修改tensor的值,然而,这种就地操作会破坏计算图(computational graph) 的连续性,从而导致梯度计算出现问题。
🍝 解决方案
知道的报错的原因,就好解决了,去掉梯度计算就可以了,在报错的位置,增加前提条件,具体代码如下:
🍛 源代码
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)🍤修改后代码
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
with torch.no_grad():
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)在报错位置增加with torch.no_grad():即可,避免梯度计算。
至此,问题解决✅!
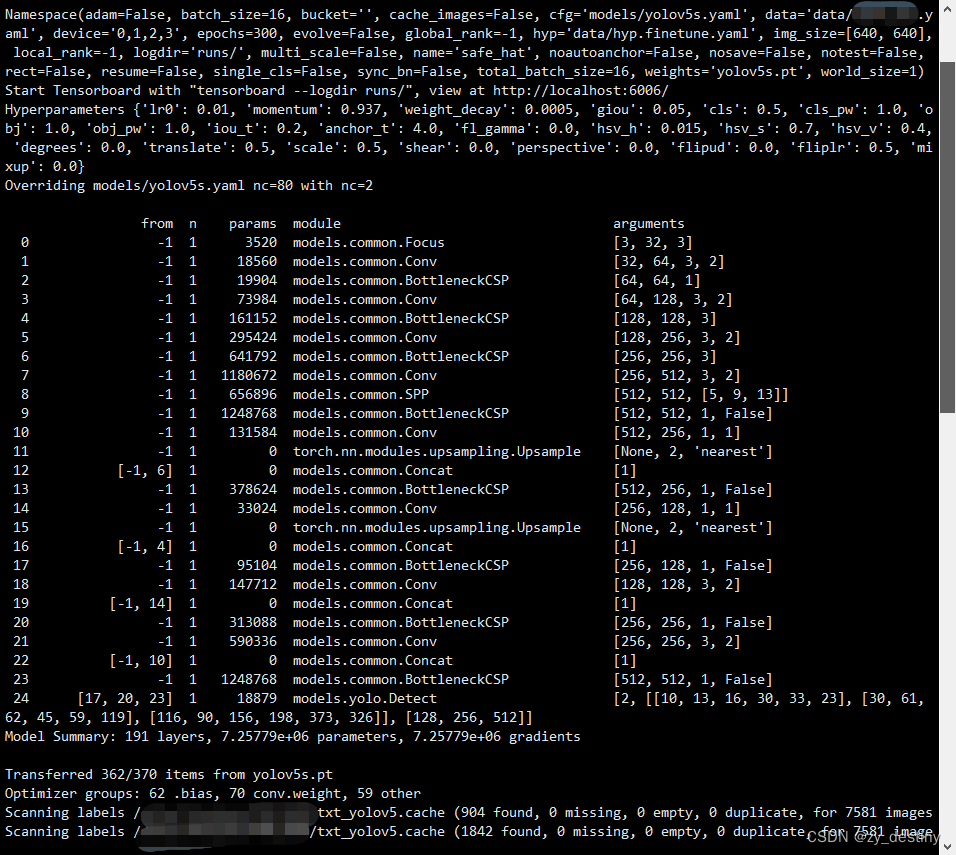
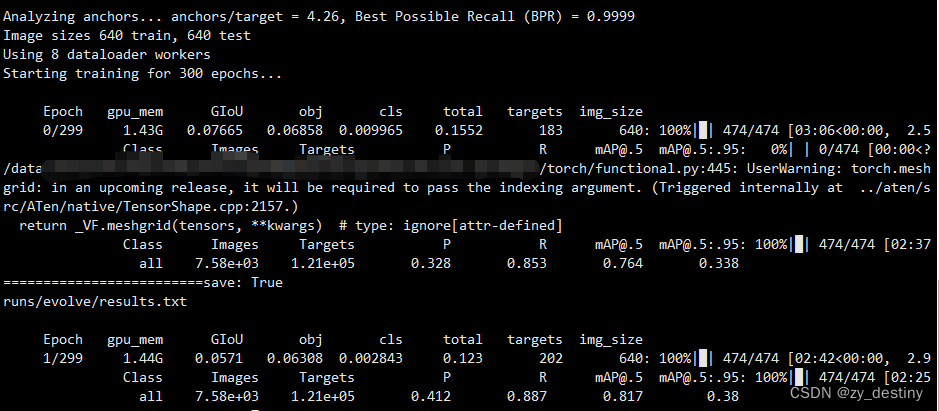
训练过程如下:
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷

















 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











