






什么事神经网络
神经网络是什么呢?让我们通过一个简单的例子来认识神经网络。
想象你想预测一个房子的价格。你手头有六个房子的数据:每个房子的面积和对应的价格。你想要找一个函数:y=f(x),其中x是房子的面积,y是价格。如果你把这六个房子的价格和面积画在二维图上,你会看到六个点。如下图所示。
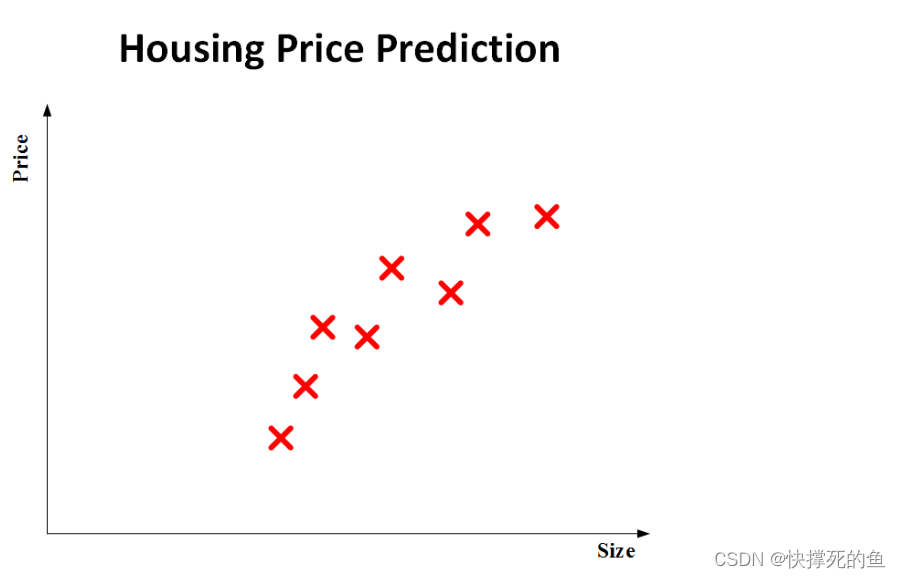
通常,我们会用一条直线来描述这些点,从而得到房价与面积之间的关系。但问题是,实际生活中,房价不会为负。所以,我们稍微修改这条线,让它在面积小于某个值时房价为零。结果就是一条类似折线的图形。如下图的蓝色折线所示。
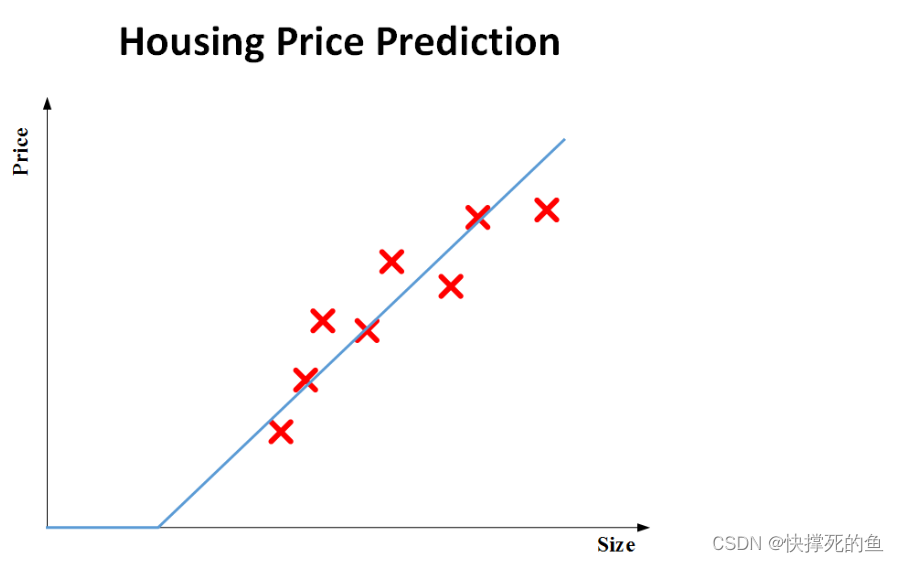
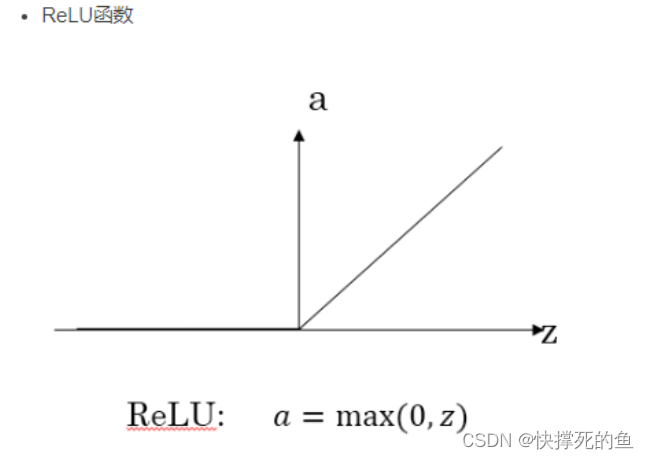
这个简单的模型实际上就是神经网络的雏形,或者说是最基本的神经网络。这个网络就是通过房屋面积来预测价格的功能。而这条蓝色折线的形状,我们称之为ReLU函数,是神经网络中经常用到的一个函数。如下图所示。
但实际上,我们在估计房价时会考虑更多的因素,不只是房屋面积。例如,我们还可能考虑房子有多少个卧室,它的邮编是什么,甚至当地的平均财富水平。这些因素会通过不同的神经元进行处理,形成一个更复杂的神经网络结构。
比如,房屋的面积和卧室数量可能和家庭大小有关。邮编可能和是否适合步行有关。邮编和财富水平可能共同决定了学校的质量。如下图所示,我们可以看到一个包含三个神经元的神经网络,它们分别代表家庭大小、可步行性和学校质量。每个神经元内部都运用了ReLU函数或其它非线性函数。
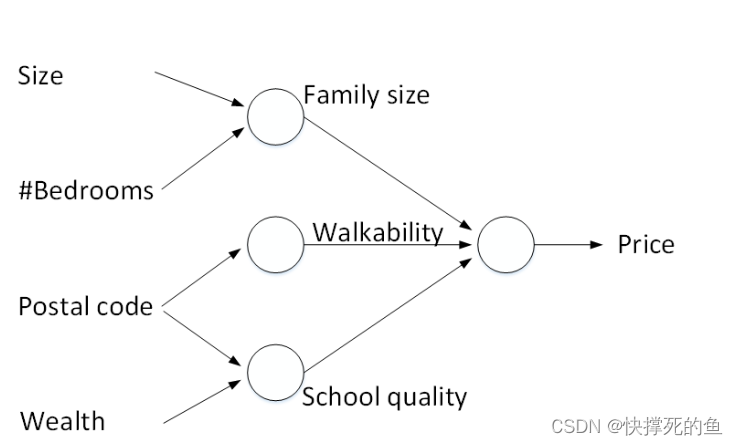
这样,我们就有了一个稍微复杂一些的神经网络模型,它接收四个输入:面积、卧室数量、邮编和财富水平,然后输出预测的房价。具体的结构如下图所示:这个神经网络有四个输入层,三个中间层(也叫隐藏层)的神经元,和一个输出层。隐藏层的每个神经元都与所有的输入有联系。
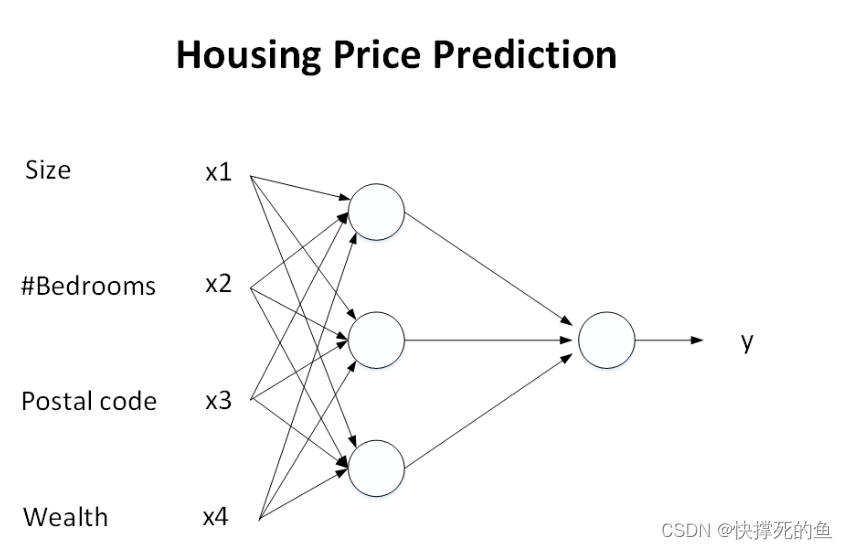
简而言之,这就是神经网络的基本构造。只要我们有足够的数据,就可以训练这个网络,让它为我们做出准确的房价预测。
神经网络的监督学习
神经网络模型已经在众多应用领域产生了巨大的价值,其中大多数基于监督学习。简而言之,监督学习是在我们已知输入数据的预期输出时进行的学习。例如,我们知道某个房子的面积和价格时,就可以训练模型来预测其他房屋的价格。
让我们考虑几个典型应用:
-
房屋价格预测:
- Zillow:这是一个美国的在线房地产数据库公司,其独特的“Zestimate”功能会预估任何房屋的市场价值。
- 链家:中国的一个大型在线房地产经纪公司,它使用大数据和机器学习来预测房价。
-
在线广告:
- Google AdSense:根据用户的浏览记录、搜索历史和其他信息为他们提供定制的广告。
- 腾讯广告:基于用户在其各种平台上(如QQ、微信、腾讯新闻等)的行为为用户推送广告。
-
计算机视觉:
- Google Photos:这是一个在线照片分享和存储服务,它可以识别照片中的物体、地点和人脸。
- 百度图像识别:它是百度AI开放平台的一部分,可以识别图像中的多种物体和场景。
-
语音识别:
- Apple Siri:苹果公司的虚拟助手可以听懂你说的话并作出响应。
- 科大讯飞:这是中国的一家公司,专门从事语音技术研发,其语音识别技术在中国得到了广泛的应用。
-
智能翻译:
- Google Translate:一个广泛使用的在线翻译工具,支持多种语言之间的翻译。
- 搜狗翻译:一个受欢迎的中文在线翻译工具,它采用深度学习技术来改善翻译质量。
-
自动驾驶:
- Tesla:其自动驾驶功能“Autopilot”已经在部分地区获得了使用许可。
- 百度Apollo:百度推出的开放自动驾驶平台,与各种车辆制造商和供应商合作,旨在推动自动驾驶技术的发展。
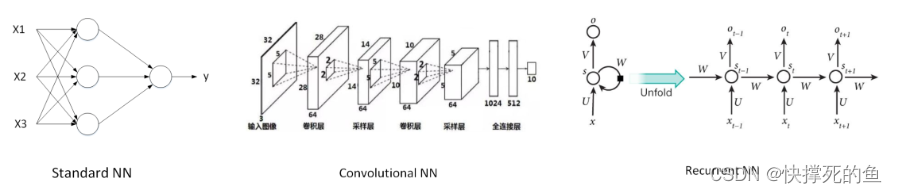
如下图所示,我们可以看到各种不同的神经网络结构。根据上面的应用,我们会选择不同的神经网络模型。常规的神经网络模型很适合于房价预测和在线广告。对于图像处理,我们会选择卷积神经网络(CNN)。而对于连续信号,如语音,我们会选择循环神经网络(RNN)。
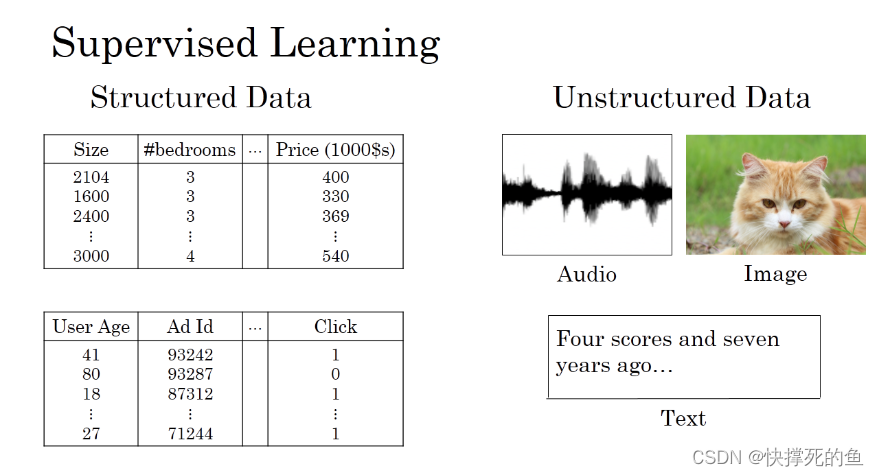
数据通常分为两种:结构化数据和非结构化数据。结构化数据就像我们的身份证信息,每一项都有明确的意义。而非结构化数据,如图片、音频或文字,对我们来说很直观,但对于计算机来说却是个挑战。幸运的是,深度学习使得计算机在处理这些数据方面表现得越来越好。
总之,无论是结构化还是非结构化数据,现代神经网络都能够很好地处理,并为我们创造了巨大的价值。在未来,我们将更深入地探索和应用这些技术。
为什么深度学习如此受到关注?
尽管深度学习和神经网络的核心思想已经存在了几十年,但直到最近,它才真正开始展露头角。为什么呢?现在,我们来探讨推动深度学习快速发展的主要因素,以便我们更清楚地理解其强大之处,并如何充分利用它。
我们可以通过一个图形来说明深度学习的强大。如下图所示,横轴表示数据量,而纵轴表示机器学习模型的表现或性能。
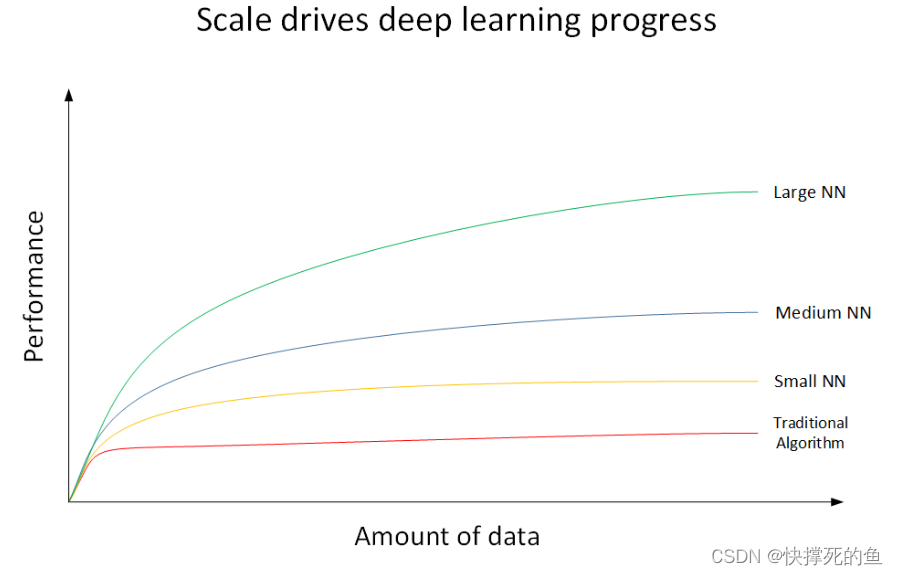
在这幅图上,你会看到四条不同的线。最低的红线代表传统的机器学习算法,比如支持向量机、逻辑回归或决策树。当数据量较少时,这些模型的表现尚可,但随着数据量的增加,性能趋于平稳,无法进一步提高。位于红线之上的黄线代表小型神经网络,随着数据的增加,它的表现超过了传统算法。而位于黄线之上的蓝线表示中型神经网络,其性能在大数据场景下进一步提高。最上面的绿线代表大型神经网络或深度学习模型,可以看到,它在大数据环境下的性能是最好的,并且呈上升趋势。
随着互联网和数字技术的快速发展,我们已经进入了大数据时代。在这个时代,每时每刻都有大量数据产生。如何从这些数据中提取有价值的信息和知识,成为了当务之急。而传统的机器学习算法往往在处理大数据时显得力不从心。与此相反,由于深度学习模型结构复杂,它们更能适应和处理大量的数据,从而在大数据环境下展现出色的性能。
深度学习之所以能够崭露头角,可以归结为以下三个关键因素:
- 数据(Data):如今,我们有比以往任何时候都多的数据可供使用和学习。
- 计算(Computation):随着GPU等高性能计算技术的发展,计算能力大幅度提高,使得深度学习变得更加可行。
- 算法(Algorithms):过去的算法常受到一些问题的困扰,但新的改进和创新使得深度学习更为高效和稳定。
以激活函数为例,早期的神经网络中常用Sigmoid激活函数,但Sigmoid函数在值较大或较小时,其梯度会趋于0,导致学习过程变慢。现在,ReLU激活函数的应用解决了这一问题,使神经网络的学习速度得到了显著的提升。
建立深度学习模型的过程很像一个反复的循环:首先根据想法编写代码,然后进行实验,根据实验结果再次修改想法,这一过程不断重复,直至得到满意的模型。因此,计算的速度越快,这一循环的效率也就越高。
这门课程的内容丰富,包括神经网络与深度学习、如何优化深度神经网络、如何结构化你的机器学习项目、卷积神经网络和自然语言处理等等。我们现在学习的是第一部分——神经网络与深度学习。
总结: 今天,我们对深度学习进行了一个简短的概述,从单神经元模型的基础概念到为何深度学习在当前这个时代变得如此重要。我们讨论了不同类型的数据,各种神经网络模型,以及推动深度学习发展的关键因素。
















 4950
4950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











