






 CPM是北京智源人工智能研究院和清华大学发布的大型中文预训练模型,拥有26亿参数和100Gb训练数据,适用于多项中文NLP任务。模型基于GPT架构,使用新的子词词表和大批量训练策略,表现出在few-shot和zero-shot学习场景下的强大性能。
CPM是北京智源人工智能研究院和清华大学发布的大型中文预训练模型,拥有26亿参数和100Gb训练数据,适用于多项中文NLP任务。模型基于GPT架构,使用新的子词词表和大批量训练策略,表现出在few-shot和zero-shot学习场景下的强大性能。
论文介绍

[2012.00413] CPM:一种大规模的生成中文预训练语言模型 (arxiv.org)
前言
预训练语言模型(PLMs)已被证明对各种下游NLP任务是有益的。最近,拥有1750亿个参数和570Gb训练数据的GPT-3因其few-shot(甚至zero-shot)学习能力而备受关注。然而,由于GPT-3的训练语料库主要为英语,且参数尚未公开,因此应用GPT-3解决中文NLP任务仍然具有挑战性。北京智源人工智能研究院和清华大学发布了基于大规模中文训练数据的生成式预训练的中文预训练语言模型(CPM,Chinese Pre-trained Language Model )。CPM拥有26亿个参数和100Gb中文训练数据,是最大的中文预训练语言模型,可以促进对话、论文生成、完形填空和语言理解等多个下游中文NLP任务。大量的实验表明,CPM在few-shot(甚至是zero-shot)学习的设置下,在许多NLP任务上取得了强大的性能。代码和参数可在https://github.com/TsinghuaAI/CPM上获得。
模型细节
模型主体
CPM的模型架构与GPT的架构类似(从左到右的Transformer encoder),下图是三个不同规模的预训练模型:
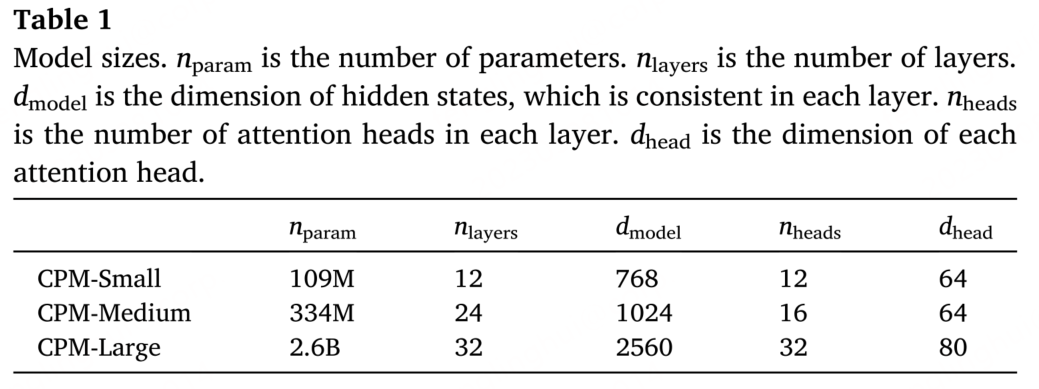
为了使CPM适应中文语料库,建立了新的sub-word词表,并调整了训练batch的大小。
词表构建
以前关于中文预训练模型的工作通常采用BERT-Chinese的子词词表(Devlin et al, 2019),它将输入文本分割为字符级序列。然而,汉语单词通常包含多个字符,单词的一些重要语义会在字符级序列中丢失。为了解决这一问题,我们构建了一个新的子词词表,它包含词和字。例如,一些常用词将被添加到词汇表中。(具体实现见代码部署-Tokenization部分)
训练策略
由于汉语单词分布的稀疏性比英语单词分布的稀疏性更严重,为了使模型训练更稳定,CPM采用了大批量的训练方法。与GPT-3 2.7B中使用的batch size (100万个令牌)相比(Brown等人,2020年),CPM的batch size (300万个令牌)大了两倍。对于训练过程中无法存储在单个GPU中的最大模型,CPM将模型沿the width dimension跨GPU进行划分,以使大规模训练可用,并减少节点之间的数据传输。
数据处理
使用unigram语言模型(Kudo et al, 2018)在词分段语料库的基础上构建了新的子词词表。同时,考虑到分词过程中引入了额外的splitters,设置了一个特殊的标记作为splitters,使子词过程具有可逆性。否则,splitters将在编码和解码中丢失。相比之下,BERT-Chinese的tokenizer是不可逆的,因为它会在汉字之间插入额外的空格,并将额外的空格视为文本中的原始空格。
在CPM的预训练中,收集了不同种类的文本,包括百科全书、新闻、小说和问答。训练数据细节如表2所示。由于输入序列长度通常大于单个文档的长度,通过在每个文档后添加“end of document” 标记来将不同的文档连接在一起,以充分利用输入长度。

预训练
基于学习率和batch size的超参数搜索,将学习率设置为1.5 × 10−4,batch size设置为3072,使得模型训练更加稳定。在第一个版本中,仍然采用the dense attention,最大序列长度为1024。论文中提到将在未来实施 sparse attention 。预先训练模型2万步,前5000步热身。优化器是Adam (Kingma et al, 2015)。使用64 块NVIDIA V100训练最大的模型需要两周时间。CPM 模型预训练过程分布在多块 GPU 上,采用层内并行的方法进行训练,并基于当前已有的成熟技术,提高通讯速率。
当前主流的并行策略主要分为数据并行、模型并行和流水并行,具体来说:
● 数据并行是将每一批次的数据切分成几部分,分别发送到模型的多个镜像中进行训练。这些模型的参数保持一致,且在计算梯度时进行同步,保证梯度更新之后参数的一致性。数据并行主要解决了训练数据过大,单个设备无法存放的问题。
● 模型并行主要是为解决模型参数规模过大无法被单卡存放的问题。模型并行会将模型中的参数矩阵切分成几块,分别存放在不同的设备上,同时将训练中的超大规模矩阵计算分布到多块卡上。通过对模型中矩阵操作的分块,一方面可以降低单个设备上的模型存储负担;另一方面,并行执行也能极大优化计算时间,减少每张卡的计算量。
● 流水并行则是针对训练批次进行优化,将训练数据在不同层间的计算流水化,以提高计算集群的利用效率。
在实际的训练中,以上三种并行模型常常会一起使用。与模型并行相比,流水并行能够降低并行执行过程中产生的设备之间的通信量,降低通信时间。在利用上述三种成熟优化的基础上,CPM计划对模型并行中的通信进行进一步优化,削减通信时间,提升运行效率。这部分优化将在下一阶段工作中体现。
代码部署
CPM-1-Pretrain代码:TsinghuaAI/CPM-1-Pretrain: Pretrain CPM-1 (github.com)
CPM-1-Finetune代码:TsinghuaAI/CPM-1-Finetune: Finetune CPM-1 (github.com)
CPM-1-Generate代码:TsinghuaAI/CPM-1-Generate: Chinese Pre-Trained Language Models (CPM-LM) Version-I (github.com)
环境安装
首先安装pytorch等基础依赖
pip install -r requirements.txt再安装APEX以支持fp16。
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./PS:如果遇到报错,检查torch和cuda版本,检查设置cuda的默认路径,安装nvcc
考虑apex的安装容易发生问题,官方也构建了对应的Docker容器,可以进行快速环境搭建。安装方式如下:
docker pull dmye/cpm:v0
sudo docker run --gpus '"device=0,1"' -it -v <path>:/CPM --name=cpm cpm:v0其中<path>为代码所在目录,-v进行文件目录挂载
安装DeepSpeed,这部分更多细节请参照DeepSpeed项目安装说明。
pip install deepspeed原始模型下载,模型下载后文件夹的目录结构需设置如下:
wget https://baai.org/l/QLtmx
mv QLtmx model-v1.tar.gz
tar -zxvf model-v1.tar.gz.
├── 80000
│ ├── mp_rank_00_model_states.pt
│ └── mp_rank_01_model_states.pt
└── latest_checkpointed_iteration.txt预训练与设置脚本
多机多卡设置
#每台机器的显卡数量
GPUS_PER_NODE=4
#支持机器之间通信的IP地址
MASTER_ADDR=localhost
#支持机器之间通信的端口
MASTER_PORT=8888
#本次训练一共涉及几台机器
NNODES=1
#当前机器的序号,编号从0开始
NODE_RANK=0数据并行,模型并行,流水并行设置
# 整体模型划分为几层,进行流水并行
pp_size=2
# 每层模型划分为几块,进行模型并行
mp_size=2设置模型尺寸
#层数
NLAYERS=2
#输入层大小
NHIDDEN=128
#单张卡每次接触到的batch大小
BATCHSIZE=4
#梯度累积步数
GAS=16DeepSpeed脚本设置,为DeepSpeed设置训练的流水并行、混合精度等细节,只有在流水并行被启用时,此脚本方被使用。如果pp_size=0或pp_size=1,意味着流水并行不被激活,此时无论脚本里的设置为何,均不会发生作用,代码只会使用Megatron-LM进行模型并行。
config_json="ds_config_t5.json"
脚本形式:
{
"train_batch_size": 128,
"train_micro_batch_size_per_gpu": 4,
"steps_per_print": 10,
"gradient_clipping": 1.0,
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"initial_scale_power": 16
},
"zero_allow_untested_optimizer": true,
"wall_clock_breakdown": true
}注意:脚本里的 train_batch_size = BATCHSIZE * GAS * GPUS_PER_NODE * NNODES / pp_size / mp_size
也可以自己自由设置训练参数,以run_t5.sh为例
--model-parallel-size 2 \
--pipe-parallel-size 2 \
--num-layers 12\
--hidden-size 128 \
--kv-hidden-size 16 \
--ff-hidden-size 256 \
--num-attention-heads 8 \
--enc-seq-length 1024\
--dec-seq-length 384\
--max-position-embeddings 1024 \
--batch-size 4\
--gas 16 \
--lr 1.5e-4 \
--lr-decay-style cosine \
--min-lr 1.0e-5 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--warmup 0.01 \运行脚本
bash run_t5.sh 或 bash run_gpt2.sh运行脚本之前,需要先将脚本中以下变量更改为实际的路径:
DATA_DIR # 预处理后数据的目录
CHECKPOINT_PATH # 预训练结束后模型的路径
RESULTS_DIR # 训练结果的存放处
MODEL_NAME # 给模型起的名字
TOKENIZER_PATH # tokenizer 的路径如果要进行多机训练,可能还需要修改
NUM_WORKERS # 节点数量
NUM_GPUS_PER_WORKER # 每个节点的卡数以及 scripts/host_files/hostfile 文件。具体格式可以参考 deepspeed 的官方文档
进行测试之前,需要去掉脚本中 --do_train 选项,然后可以使用 --eval_ckpt_path 选项来指定需要测试的模型。
Tokenization
Tokenization实现主要在data_util/tokenization_gpt2.py,先对于文本进行分词,再使用 SentencePiece 得到 BPE 的结果。由于 SentencePiece 不能有效编码空格和换行符,在 BPE 之前,我们将文本中的空格和换行符替换为\u2582和\u2583。生成文本的时候也会对应的把生成的\u2582和\u2583替换回空格和换行符。
实现自己的模型
我们以pretrain_gpt2.py为例子,介绍下如何实现自己的模型
使用Megatron-LM实现模型并行
Megatron-LM的较为核心的代码是 megatron/mpu/layers.py,这里面定义了
VocabParallelEmbedding旨在将embedding层切割到不同的GPU上,
ColumnParallelLinear、RowParallelLinear则是将矩阵按照行列切割到不同的GPU上,完整的输出结果需要通过一次all-reduce来从各个GPU上汇总。
这里我们以GPT-2中的Transformer的线性层来举例。Transformer的线性层分为两部分:
第一部分是将hidden_size维的向量映射为4 * hidden_size维的向量,并且通过GeLU激活;
第二部分是将激活后的4 * hidden_size 维的向量映射回hidden_size维,并且施加Dropout。
这里,我们对第一部分的线性层矩阵按列切分,第二部分按行切分。
对于第一部分$\mathbf{Y}=\text{GeLU}(\mathbf{X}\mathbf{A})$,我们将矩阵$\mathbf{A}$切分为$\mathbf{A}_1,\mathbf{A}_2$两个部分,那么整体的计算也被相应分为两部分$\mathbf{Y}_1=\text{GeLU}(\mathbf{X}\mathbf{A}_1)$和$\mathbf{Y}_2=\text{GeLU}(\mathbf{X}\mathbf{A}_2)$。此时$\mathbf{Y}_1$和$\mathbf{Y}_2$分别为$\mathbf{Y}$的前$2 \times \text{hidden_size}$结果和后$2 \times \text{hidden_size}$结果。
对于$\mathbf{Z}=\mathbf{Y}\mathbf{B}$,我们将矩阵$\mathbf{B}$按行切分为$\mathbf{B}_1, \mathbf{B}_2$。将第一部分的结果$\mathbf{Y}_1$和$\mathbf{Y}_2$传入后,可计算$\mathbf{Z}_1=\mathbf{Y}_1\mathbf{B}_1$与$\mathbf{Z}_1=\mathbf{Y}_2\mathbf{B}_2$,此时有$\mathbf{Z}=\mathbf{Z}_1+\mathbf{Z}_1$。在Dropout之前,我们需要对$\mathbf{Z}_1$与$\mathbf{Z}_2$进行一次同步,加和后的结果再过Dropout。
总的来看,整个线性层计算过程中,每张显卡都只负责了一半的计算量,整体结果需要一次额外的all_reduce来对输出结果进行汇总。这里也给出具体的代码实现,与上述的过程是一致的。此部分代码可见 megatron/model/transformer.py
class ParallelMLP(MegatronModule):
def __init__(self, ...):
super(ParallelMLP, self).__init__()
args = get_args()
# Project to 4h.
self.dense_h_to_4h = mpu.ColumnParallelLinear(
args.hidden_size,
args.hidden_size * 4,...)
...
# Project back to h.
self.dense_4h_to_h = mpu.RowParallelLinear(
args.args.hidden_size * 4,
args.hidden_size,...)
def forward(self, hidden_states):
# [s, b, 4hp]
intermediate_parallel, bias_parallel = self.dense_h_to_4h(hidden_states)
...
# [s, b, h]
output, output_bias = self.dense_4h_to_h(intermediate_parallel)
return output, output_bias
同样的方法我们也可以实现Attention层、Embedding层的模型并行。
使用DeepSpeed实现流水并行
使用DeepSpeed进行流水并行也并不复杂,只需要将模型的各个层加入队列中,并用队列实例化DeepSpeed的PipelineModule类即可。
但是受限于DeepSpeed框架本身的设计,队列中的各个层输入的tensor数量和输出的tensor数量必须保持一致,以确保各层之间可以无缝衔接。
例如实现一个流水的Transformer版本,模型的每一层都需要输出hidden_states和mask,与下一层的输入相衔接。
from deepspeed.pipe import PipelineModule, LayerSpec
...
class TransformerBlockPipe(TransformerBlock)
def forward(self, ...):
hidden, mask = ...
...
output = super().forward(hidden, mask)
return (output, mask)
...
class GPT2(PipelineModule):
def __init__(self, num_layers, ...):
...
specs = [TransformerBlockPipe() for _ in range(num_layers) ]
...
super().__init__(layers=specs, ...)上述代码有一个LayerSpec的实现。LayerSpec有点类似一层懒惰标记的封装。
具体而言,LayerSpec的参数分别为神经网络层的class以及class的初始化参数。LayerSpec将class和初始化参数记忆下来,但不会立刻实例化,而是在流水线构建过程中再将class和初始化参数结合起来进行实例化。
使用DeepSpeed进行混合加速也十分方便,只需要让加入流水队列里的模型实现是基于模型并行的即可,如使用Megatron-LM来实现上述代码的TransformerBlockPipe和TransformerBlock。
使用TDS实现训练流程
TDS重新实现了Deepspeed的流水线,通过适配器模式把DeepSpeed的其他功能封装进来,所以用起来也非常简单。在安装完DeepSpeed之后,只需要将TDS的代码拷贝到工程中,然后用以下的方式加载库即可。
import tds as deepspeed使用TDS的训练流程代码与之前的DeepSpeed和Megatron中的范例代码是一致的,首先需要一个获取数据iterator的模块。
def train_valid_test_datasets_provider(...):
...
train_ds, valid_ds, test_ds = build_train_valid_test_datasets(...)
...
return train_ds, valid_ds, test_ds然后,需要一个从data_iterator中获取数据,并且分发到各个GPU上的模块。
def get_batch(data_iterator):
...
# 定义传输的数据类型
keys = ['text']
datatype = torch.int64
# 将数据压缩之后广播到同一个数据并行group中的每个GPU上
if data_iterator is not None:
data = next(data_iterator)
else:
data = None
data_b = mpu.broadcast_data(keys, data, datatype)
# 将数据解压
tokens_ = data_b['text'].long()
# 从数据中提取token, label, mask信息
tokens, labels, loss_mask, attention_mask, position_ids = (...)
...
return tokens, labels, loss_mask, attention_mask, position_ids流水并行需要一个单独的数据获取分发模块,整体结构与get_batch是类似的,但有两个细微差别。一个是DeepSpeed中将流水并行的data_iterator交给了后台管理,所以get_batch_pipe只需要负责分发数据即可。第二个是DeepSpeed对给流水线使用的data_iterator是有格式限制的,必须是返回两个tuple,前一个是用来进行forward的输入,后一个是用来进行loss的计算的输入。
def get_batch_pipe(data):
...
# 定义传输的数据类型
keys = ['text']
datatype = torch.int64
# 将数据压缩之后广播到同一个数据并行group中的每个GPU上
data_b = mpu.broadcast_data(keys, data, datatype)
# 将数据解压
tokens_ = data_b['text'].long()
# 从数据中提取token, label, mask信息
tokens, labels, loss_mask, attention_mask, position_ids = (...)
...
return (tokens, position_ids, attention_mask), (labels, loss_mask)在实现了数据获取的各项模块后,模型获取模块就十分简单,根据是否使用流水并行返回不同模型。与DeepSpeed相比,TDS中需要制定流水线中间的输入输出类型,是否需要保存梯度,以及是否需要将中间结果切割到多个GPU来减少显存使用。
def model_provider():
"""Build the model."""
args = get_args()
if args.pipe_parallel_size == 0 :
model = GPT2Model(...)
else:
model = GPT2ModelPipe(...)
model._megatron_batch_fn = get_batch_pipe
# TDS中需要制定流水线中间的输入输出类型,是否需要保存梯度,以及是否需要将中间结果切割到多个GPU来减少显存使用
model._input_grad = [True, False]
model._input_type = ['float', 'bool']
model._input_pipe_partitioned = [True, False]
return model最后只要基于上述模块,启动pretrain就能开始计算。
from megatron.training import pretrain
if __name__ == "__main__":
pretrain(train_valid_test_datasets_provider, model_provider, ...)
















 3075
3075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









