










一种(理论有损)提升注意力计算效率的方法:SWA(sliding window attention)。Qwen系列和Mistral就使用了SWA。
对于原始的 causal attention,其注意力矩阵是一个下三角矩阵,这样每个 token 都能看到自己和在自己前面的所有的 token。这样随着输入长度 s s s 增大,这个下三角矩阵中 1 的元素数量以 s 2 s_2 s2 的速度增长,计算量以序列长度平方的速度增长,缓存和长度成线性关系增长。
1 SWA
CNN 中的感受野:
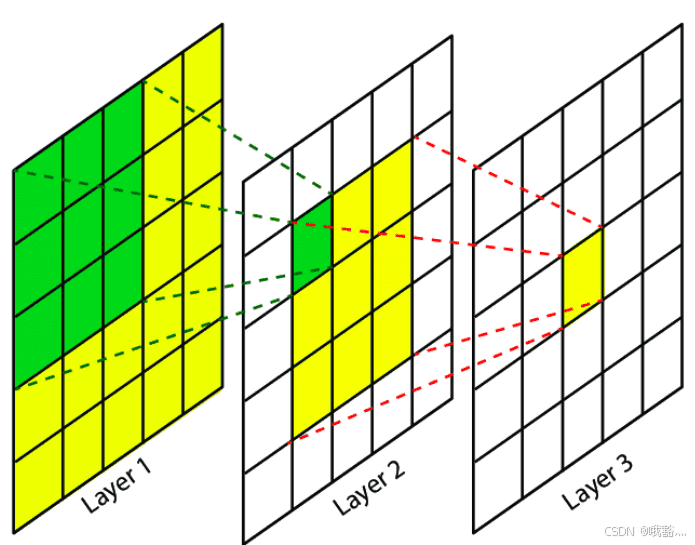
如上图,假设模型有 3 层,每层卷积核大小为 [ 3 , 3 ] [3, 3] [3,3](实际上CNN里卷积操作就是一个 sliding window)。
对于 layer3,每一个像素能看到 layer2 中的一个 [ 3 , 3 ] [3, 3] [3,3] 的区域,layer2 中其他较远的像素就看不到了。再往前推,layer2 里的每个像素也可以看到 layer1 中的一个 [ 3 , 3 ] [3, 3] [3,3] 区域,那么 layer2 中的 [ 3 , 3 ] [3, 3] [3,3] 区域就可以看到 layer1 中一个 [ 5 , 5 ] [5, 5] [5,5] 的区域,相当于 layer3 中一个像素可以间接看到 layer1 中一个 [ 5 , 5 ] [5, 5] [5,5] 的输入。以此类推,如果再增加一层 layer4,那么 layer4 中一个像素就能获取 layer1 一个 [ 7 , 7 ] [7, 7] [7,7] 区域的信息。
每层只能多看周围一格的信息,但是只要层数够多,理论上靠近输出端的层想看多远就能看多远。
一般认为模型低层部分提取比较基础的特征,高层会提取高级的语义特征。在 CNN 里,前几层提取的可能更多是关于简单的边界、颜色、形状等基础特征,后面的层则提取较复杂的语义特征,比如在分类任务中会是和分类类别相关的花纹、物体大小、风格等特征。
如果我们把模型设计成最后一层的一个像素刚好要到第一层才能接收到全局信息(在其它层都只能看到局部),那对于图像边缘的语义特征识别能力可能会受到一些限制。假设我们做猫和狗的图像分类任务,如果这个时候决定性的特征出现在图像最边缘几个像素里,那这种情况下的错误率会比特征出现在图像中间时要高。
对于语言模型,一般情况下,越远距离的信息,对当前位置的重要性越低,因此只要我们的窗口大小不要太过极限小,问题应该都还不大。
1.1 SWA 的具体做法
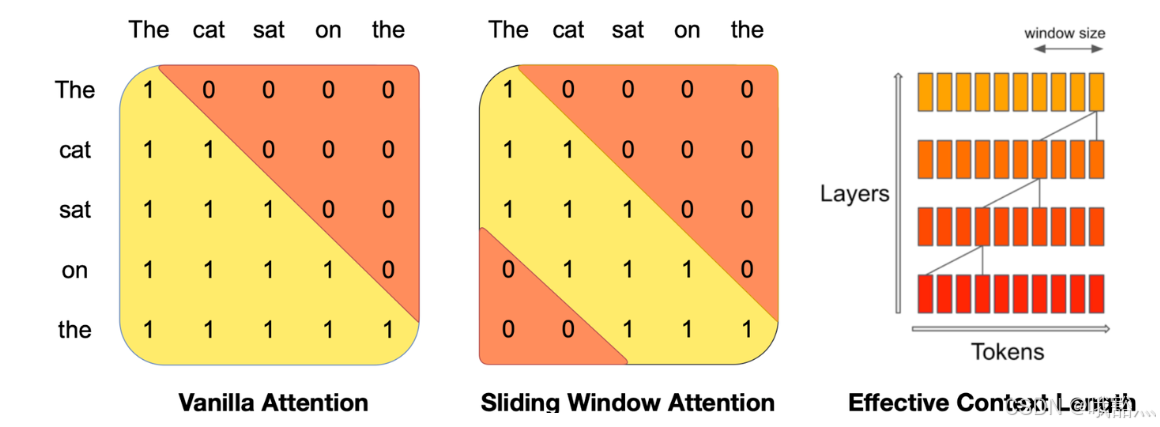
- 左边是正常的 causal attention,每个位置能看到自己和自己前面的所有位置,attention mask 是个下三角矩阵;
- 中间则是 SWA 的 attention mask,这里的窗口大小为 3。包括自己在内,每个位置只能往前看 3 个输入。
同 CNN 的感受野一样,随着层数的堆叠,模型理论上能处理的最远距离也逐层线性递增。LLM 里递增的方向是单向的,只能往前。
Mistral 7B 使用了 4096 的窗口大小,模型层数为 32,则最终输出的感受野为 4096 × 32 = 128 K 4096 \times 32 = 128K 4096×32=128K 。
Attention 的计算量与 sequence length 的二次方成正比,而使用 SWA 的理论计算量与 sequence length 的一次方成正比。而缓存和上下文长度 sequence length 成线性关系。
SWA 在上下文长度在 4k 以下时,和普通 causal attention 一样;当上下文长度超过4k时,则相对节省资源,长度越大,节省的比例越高。实际使用中,Mistral 通过把 SWA 实现在 FlashAttention 和 xFormers 中,对于 16k 的上下文长度,获得了 2 倍的速度提升。
1.2 SWA 和 KV Cache 的配合实现
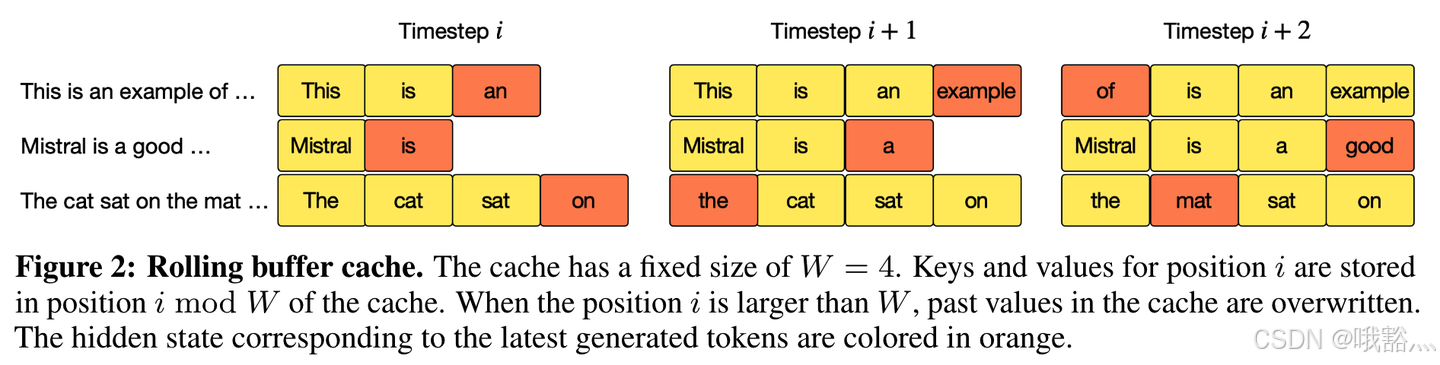
在不使用 sliding window 的情况下,随着自回归推理的进行,KV Cache 只增不减。在使用 SWA 的情况下,超出窗口长度的 kv 就可以不用再缓存了,使用一个轮转替换的策略。
比如窗口大小 W=4,当第 5 个 token 需要缓存时,直接替换掉第 1 个 token,这样就可以保持 kv 缓存有一个最大值(为窗口大小),而不会无限增长。
1.3 长 Prompt 的分块
更近一步,考虑到使用 RAG 或者 funciton call 的时候,会使用比较长的固定的 prompt 来指导模型的行为。
除了预先计算好 system prompt 的 kv 值,并保存在缓存中方便每次用户输入使用外。如果 system prompt 很长(比 sliding window 大),可以通过对 system prompt 的 kv 值进行切分来进一步优化计算。
比如窗口大小 W=4,system prompt 大小为 9 时,可以把 system prompt 的 kv 缓存切成 [4,4,1] 三块。
第一块由于和当前的输入距离超过了一个 window 的大小,是完全看不见的,对应的 attention mask 全为 0,可以完全忽略;第二块的 attention mask 是一个上三角矩阵,当前的输入需要用到这部分信息;第三块是一个下三角矩阵的左边部分,包含了当前的输入在内。
在推理的时候,只需要用到第二块和第三块的内容,这就节省了缓存。无论 prompt 有多长,只要按窗口大小分块,一定只用到最后两块。

2 sparse attention
SWA 实际上是一种 sparse attention。
2.1 Longformer
Longformer 主要目的是为了解决长上下文的问题。
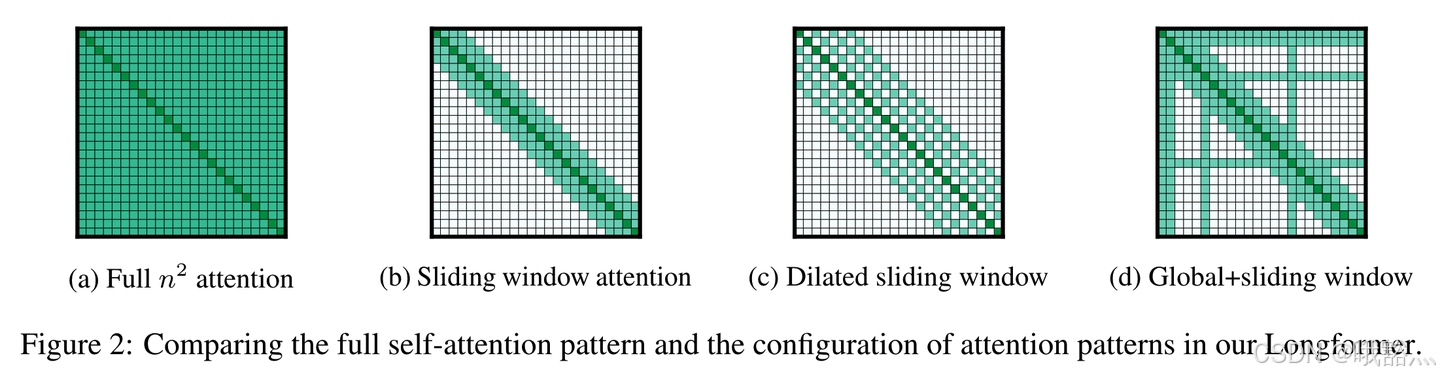
上图中的(b)就是 SWA。在 SWA 的基础上,还可以进行空洞滑窗(dilated sliding window),在不增加计算量的情况下,提升感受野。这也是从空洞卷积来的灵感。
还可以更进一步优化 attention。无论是 SWA 还是 dilated sliding window,每个位置都只能看到局部的信息。但是实际上有些位置就是对全局信息有很高的需求。
在 Bert 中,[CLS] token就常常作为分类 token 或者相似度向量使用,这种情况下就需要它能获取整个上下文的完整信息。在 GPT 中,instruction,或者说 prompt 的部分也对全局信息有更高要求,因为我们希望在整个对话过程中,模型都能遵循我们给出的规则。
对于这些 token,让它可以看到其他所有位置,使用完整的 global attention,而其他位置则使用sliding window,如(d)中所示。
2.2 Big Bird
sliding window 和 global attention 结合的思路和 Longformer 相似。Big Bird 还额外加入了一个 random attention 的做法。
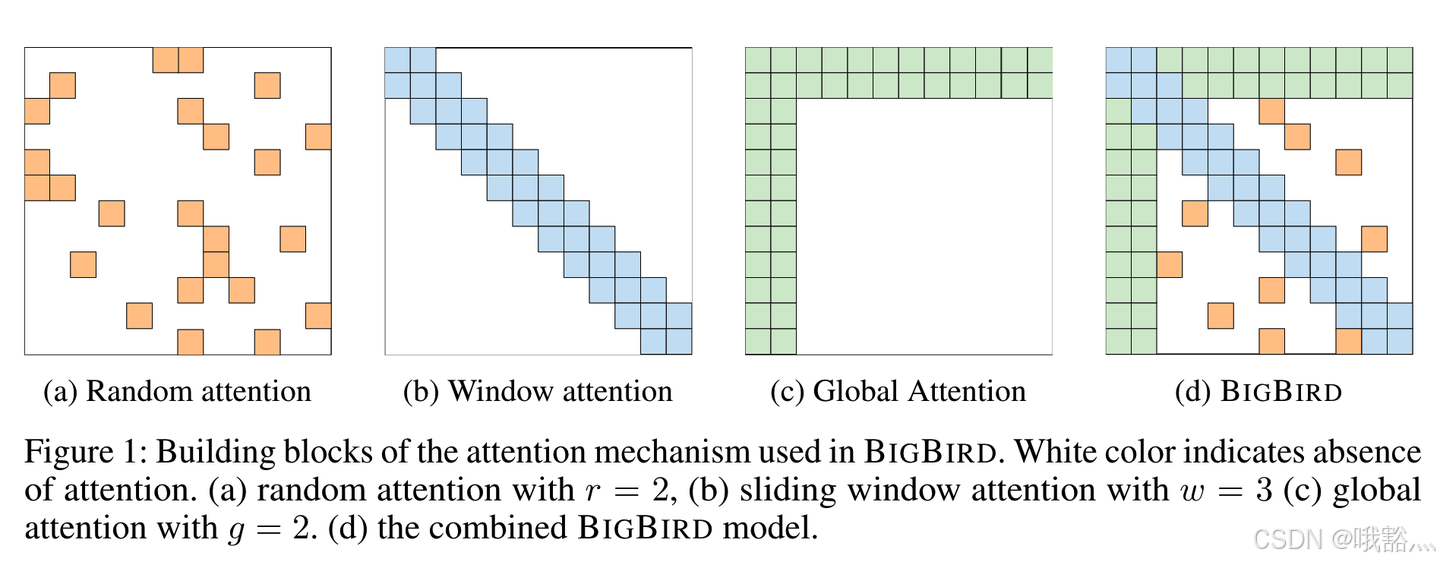
上图中 r = 2 r = 2 r=2 即每个位置使用2个随机注意力。


















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









