







Randomized Algorithms
-
Las Vegas Algorithm for quick sort
-
Monte Carlo Algorithm for find min cut
-
The quick sort:
- Best case: each time the chose pivot is in the middle; O ( n log n ) O(n\log n) O(nlogn);
- Worst case: in a sorted list, each time the chosen pivot is in the beginning; O ( n 2 ) O(n^2) O(n2)
1. Random quicksort(Las Vegas Algorithm)
- Always return the right answer or none, but the running time is not sure.
randomly choose the pivot

Lemma: RandQS sorts the numbers. Proof: induction on n n n.
-
Lucky case: s i s_i si is always the median: O ( n log n ) O(n\log n) O(nlogn)
-
Unlucky case: s i s_i si is always the minimum: O ( n 2 ) O(n^2) O(n2)
1.3 Average case analysis
Theorem: E [ X ] = O ( n log n ) E[X]=O(n\log n) E[X]=O(nlogn)
Proof:
Let
S
1
,
S
2
,
.
.
.
,
S
n
S_1,S_2,...,S_{n}
S1,S2,...,Sn be the numbers in sorted order, and for example:
(
s
1
,
s
2
,
.
.
.
s
5
)
=
(
3
,
2
,
1
,
5
,
4
)
(s_1,s_2,...s_5)=(3,2,1,5,4)
(s1,s2,...s5)=(3,2,1,5,4) and
(
S
1
,
S
2
,
.
.
.
,
S
5
)
=
(
1
,
2
,
3
,
4
,
5
)
(S_1,S_2,...,S_5)=(1,2,3,4,5)
(S1,S2,...,S5)=(1,2,3,4,5)
Let X i j X_{ij} Xij denotes comparison between S i S_i Si and S j S_j Sj, and X i j ∈ 0 , 1 X_{ij}\in {0,1} Xij∈0,1:
E [ X ] = E [ ∑ i = 1 n ∑ j > i X i j ] = ∑ i = 1 n ∑ j > i E [ X i j ] E[X]=E[\sum_{i=1}^n\sum_{j>i}X_{ij}]=\sum_{i=1}^n\sum_{j>i}E[X_{ij}] E[X]=E[i=1∑nj>i∑Xij]=i=1∑nj>i∑E[Xij]
Let p i j p_{ij} pij denotes the probability that S i S_{i} Si and S j S_j Sj are compared.
Then E [ X i j ] = 0 × ( 1 − p i j ) + 1 × p i j = p i j E[X_{ij}]=0\times(1-p_{ij})+1\times p_{ij}=p_{ij} E[Xij]=0×(1−pij)+1×pij=pij
We can observe that S i S_i Si and S j S_j Sj are compared if and only if when one of them are the pivot. Then the probability of one of them to be chosen as the pivot: 2 j − i + 1 = p i j \frac{2}{j-i+1}=p_{ij} j−i+12=pij, (pick 2 elements from the number of S S S need to be compared in an iteration)
Then E [ X ] = ∑ i = 1 n ∑ k = 2 n − i + 1 2 k ≤ ∑ i = 1 n ∑ k = 1 n 2 k = 2 n ∑ k = 1 n 1 k = 2 n H n E[X]=\sum_{i=1}^n\sum_{k=2}^{n-i+1}\frac{2}{k}\le \sum_{i=1}^n\sum_{k=1}^n\frac{2}{k}=2n\sum_{k=1}^n\frac{1}{k}=2nH_n E[X]=∑i=1n∑k=2n−i+1k2≤∑i=1n∑k=1nk2=2n∑k=1nk1=2nHn;
by integration, we can know that H n − 1 ≤ ∫ 1 n 1 x d x = l n ( n ) H_n-1\le\int_1^{n}\frac{1}{x}dx=ln(n) Hn−1≤∫1nx1dx=ln(n), then H n = O ( log n ) H_n=O(\log n) Hn=O(logn); and E [ X ] = O ( n log n ) E[X]=O(n\log n) E[X]=O(nlogn).
2. Randomized min-cut
- Monte Carlo Algorithm, might give the wrong answer
Given: Graph G = ( V , E ) , ∣ V ∣ ≥ 2 G=(V,E),|V|\ge2 G=(V,E),∣V∣≥2.
Find: Min. set of edges C ⊆ E C\subseteq E C⊆E, s.t. G − C G-C G−C is disconnected.
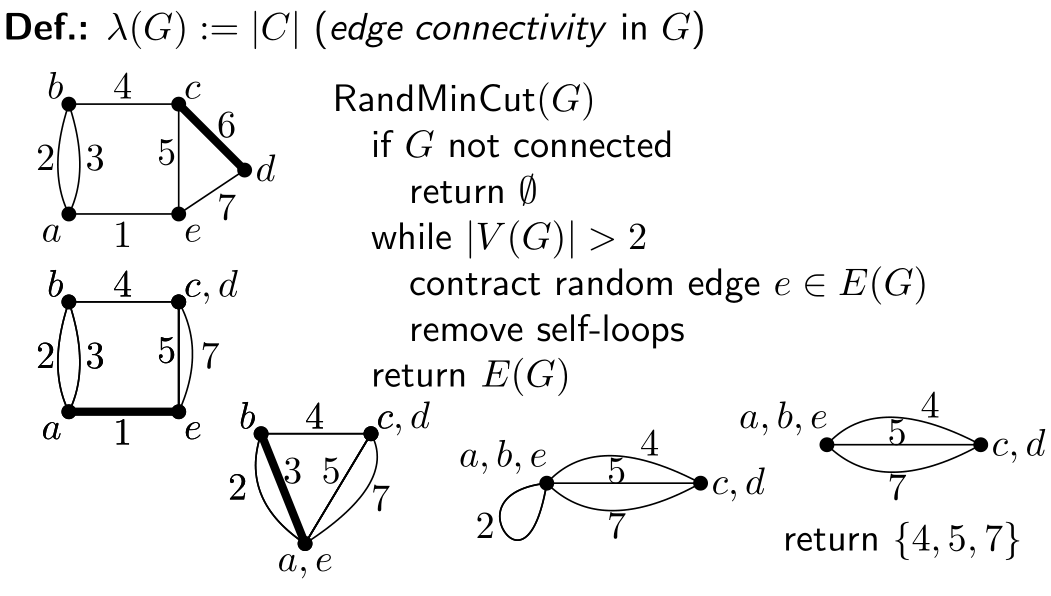
2.1Lemma: RandMinCut(G) returns a cut.
Proof: If C C C is not a cut, there is path π \pi π in the original graph G G G from u ∈ V 1 u\in V_1 u∈V1 to v ∈ V 2 v\in V_2 v∈V2 that are not in C C C, but we have removed all edges of π \pi π. Contradiction!
2.2Probability of min-cut
Theorem: For any min-cut C C C, P r [ R a n d M i n C u t r e t u r n s C ] ≥ 2 n ( n − 1 ) Pr[RandMinCut\;returns\;C]\ge \frac{2}{n(n-1)} Pr[RandMinCutreturnsC]≥n(n−1)2
Proof:
-
Define: G i = ( V i , E i ) G_i=(V_i,E_i) Gi=(Vi,Ei): graph at the beginning of step i ∈ { 1 , . . . , n − 1 } i\in\{1,...,n-1\} i∈{1,...,n−1}. Step i ∈ { 1 , . . , n − 2 } i\in \{1,..,n-2\} i∈{1,..,n−2} contracts edge e i ∈ E i e_i\in E_i ei∈Ei
-
n i : = ∣ V i ∣ = n − i + 1 n_i:=|V_i|=n-i+1 ni:=∣Vi∣=n−i+1 so that n 1 = ∣ V ∣ n_1=|V| n1=∣V∣;
-
Define events: ε : e i ∉ C \varepsilon:e_i\notin C ε:ei∈/C, and ε j : = ∩ i = 1 j = 1 ε i \varepsilon_j:=\cap_{i=1}^{j=1}\varepsilon_i εj:=∩i=1j=1εi
-
Need to show: P r [ ε < n − 1 ] ≥ 2 n ( n − 1 ) Pr[\varepsilon_{<n-1}]\ge\frac{2}{n(n-1)} Pr[ε<n−1]≥n(n−1)2
-
Since in each step, the event that we would not make a mistake is independent, P r [ ε 1 ∣ ε < 1 ] = P r [ ε 1 ] Pr[\varepsilon_{1}|\varepsilon_{<1}]=Pr[\varepsilon_1] Pr[ε1∣ε<1]=Pr[ε1], and P r [ ε < 3 ] = P r [ ε 2 ∣ ε < 2 ] = P r [ ε 2 ] P r [ ε 1 ∣ ε < 1 ] Pr[\varepsilon_{<3}]=Pr[\varepsilon_2|\varepsilon_{<2}]=Pr[\varepsilon_2]Pr[\varepsilon_{1}|\varepsilon_{<1}] Pr[ε<3]=Pr[ε2∣ε<2]=Pr[ε2]Pr[ε1∣ε<1]
-
Due to this, we know that: P r [ ε < n − 1 ] = ∏ i = 1 n − 2 P r [ ε i ∣ ε < i ] Pr[\varepsilon_{<n-1}]=\prod_{i=1}^{n-2}Pr[\varepsilon_i|\varepsilon_{<i}] Pr[ε<n−1]=∏i=1n−2Pr[εi∣ε<i]
-
Since cut in G i G_i Gi is also a cut in G G G: λ ( G i ) ≥ λ ( G ) = ∣ C ∣ \lambda(G_i)\ge\lambda(G)=|C| λ(Gi)≥λ(G)=∣C∣ and m i n v ∈ V i d ( v ) ≥ λ ( G i ) ≥ ∣ C ∣ min_{v\in V_i}d(v)\ge\lambda(G_i)\ge|C| minv∈Vid(v)≥λ(Gi)≥∣C∣, where d ( v ) d(v) d(v) is the degree of a vertex.
-
∣ E i ∣ = ∑ v ∈ V i d ( v ) 2 ≥ ∑ v ∈ V i ∣ C ∣ 2 = n i ∣ C ∣ 2 |E_i|=\sum_{v\in V_i}\frac{d(v)}{2}\ge\sum_{v\in V_i}\frac{|C|}{2}=\frac{n_i|C|}{2} ∣Ei∣=∑v∈Vi2d(v)≥∑v∈Vi2∣C∣=2ni∣C∣
-
P r [ ε ˉ i ∣ ε < i ] = ∣ C ∣ ∣ E i ∣ ≤ ∣ C ∣ n i ∣ C ∣ / 2 = 2 n i Pr[\bar \varepsilon_i|\varepsilon_{<i}]=\frac{|C|}{|E_i|}\le\frac{|C|}{n_i|C|/2}=\frac{2}{n_i} Pr[εˉi∣ε<i]=∣Ei∣∣C∣≤ni∣C∣/2∣C∣=ni2
-
P r [ ε i ∣ ε < i ] = 1 − P r [ ε ˉ i ∣ ε < i ] ≥ n − i − 1 n − i + 1 Pr[\varepsilon_i|\varepsilon_{<i}]=1-Pr[\bar \varepsilon_i|\varepsilon_{<i}]\ge\frac{n-i-1}{n-i+1} Pr[εi∣ε<i]=1−Pr[εˉi∣ε<i]≥n−i+1n−i−1
-
P r [ ε < n − 1 ] = ∏ i = 1 n − 2 P r [ ε i ∣ ε < i ] ≥ ∏ i = 1 n − 2 n − i − 1 n − i + 1 = 2 n ( n − 1 ) Pr[\varepsilon_{<n-1}]=\prod_{i=1}^{n-2}Pr[\varepsilon_i|\varepsilon_{<i}]\ge\prod_{i=1}^{n-2}\frac{n-i-1}{n-i+1}=\frac{2}{n(n-1)} Pr[ε<n−1]=∏i=1n−2Pr[εi∣ε<i]≥∏i=1n−2n−i+1n−i−1=n(n−1)2
2.3Analyze the probability
-
Tightness: find a min cut in a circle: C n 2 = n ( n − 1 ) 2 C_{n}^2=\frac{n(n-1)}{2} Cn2=2n(n−1); P r [ f i n d a c u t ] = 2 n ( n − 1 ) Pr[find\;a\;cut]=\frac{2}{n(n-1)} Pr[findacut]=n(n−1)2
-
The probability is very small when n n n is very large, but we can bound it:
- If we run it many many times: P r [ n o t f i n d ] = ( 1 − 1 x x ) ≤ ( e − 1 / x ) x = 1 / e Pr[not\;find]=(1-\frac{1}{x^x})\le(e^{-1/x})^x=1/e Pr[notfind]=(1−xx1)≤(e−1/x)x=1/e;where x x x is the running times and 1 / x 1/x 1/x is the probability of finding a cut.















 5207
5207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









