









后面增添了如何加载同层的预训练参数以及到底要不要用ImageNet预训练的解析。
1. Pytorch中加入注意力机制
第一步:找到ResNet源代码
在里面添加通道注意力机制和空间注意力机制
通道注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
在ResNet网络中添加注意力机制
注意点:因为不能改变ResNet的网络结构,所以CBAM不能加在block里面(也可以加在block里面,此时网络不能加载预训练参数),因为加在block里面网络结构发生了变化,所以不能用预训练参数。加在最后一层卷积和第一层卷积不改变网络,可以用预训练参数。
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
# 网络的第一层加入注意力机制
self.ca = ChannelAttention(self.inplanes)
self.sa = SpatialAttention()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
# 网络的卷积层的最后一层加入注意力机制
self.ca1 = ChannelAttention(self.inplanes)
self.sa1 = SpatialAttention()
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.ca(x) * x
x = self.sa(x) * x
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.ca1(x) * x
x = self.sa1(x) * x
x = self.avgpool(x)
x = x.reshape(x.size(0), -1)
x = self.fc(x)
return x
请详细阅读代码加的位置:
# 网络的第一层加入注意力机制
self.ca = ChannelAttention(self.inplanes)
self.sa = SpatialAttention()
和
# 网络的卷积层的最后一层加入注意力机制
self.ca1 = ChannelAttention(self.inplanes)
self.sa1 = SpatialAttention()
forWord部分代码
x = self.ca(x) * x
x = self.sa(x) * x
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.ca1(x) * x
x = self.sa1(x) * x
请大家详细阅读,一定能看懂的。
2. 扩充知识
2.1 加载预训练参数
1.增添在自己写的网络中加载预训练参数:
model_path = resnet18-5c106cde.pth' # 预训练参数的位置
model = resnet50()
model_dict = model.state_dict() # 网络层的参数
# 需要加载的预训练参数
pretrained_dict = torch.load(model_path)['state_dict'] # torch.load得到是字典,我们需要的是state_dict下的参数
# 删除pretrained_dict.items()中model所没有的东西
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} # 只保留预训练模型中,自己建的model有的参数
model_dict.update(pretrained_dict) # 将预训练的值,更新到自己模型的dict中
model.load_state_dict(model_dict) # model加载dict中的数据,更新网络的初始值
或者按照评论区Mr DaYang同学给出的方法,修改之后如下:
model_path = 'https://download.pytorch.org/models/resnet18-5c106cde.pth' # 预训练参数的位置
# 自己重写的网络
model = resnet50()
model_dict = model.state_dict() # 网络层的参数
# 需要加载的预训练参数
pretrained_dict = torch.load(model_path)['state_dict'] # torch.load得到是字典,我们需要的是state_dict下的参数
pretrained_dict = {k.replace('module.', ''): v for k, v in
pretrained_dict.items()} # 因为pretrained_dict得到module.conv1.weight,但是自己建的model无module,只是conv1.weight,所以改写下。
# 删除pretrained_dict.items()中model所没有的东西
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} # 只保留预训练模型中,自己建的model有的参数
model_dict.update(pretrained_dict) # 将预训练的值,更新到自己模型的dict中
model.load_state_dict(model_dict) # model加载dict中的数据,更新网络的初始值
按照上述步骤按层读取参数还是报错, 解决方案有以下两种:
model.load_state_dict(torch.load(PATH), strict=False)里面的strict参数没有设置成False。如果是strict=True表示严格按照字典读取(修改网络结构后会报错),所以可以将strict设置为False,这样就能避免这种情况了。- (万能)在
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}构造词典的过程中,删除那些不能加载预训练的k,假设你现在报错的模型是classifier.1.weight和classifier.1.bias,那就可以改为pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict and k not in ['classifier.1.weight', 'classifier.1.bias']}。
对于注意力机制的个人理解:
- 网络越深、越宽、结构越复杂,注意力机制对网络的影响就越小。
- 在网络中加上CBAM不一定带来性能上的提升,对性能影响因素有数据集、网络自身、注意力所在的位置等等。
- 建议直接在网络中加上SE系列,大部分情况下性能都会有提升的。
CBAM的解析:CBAM:卷积注意力机制模块
贴出一些和SE相关的:SE-Inception v3架构的模型搭建(keras代码实现)和PyTorch Hub发布!一行代码调用所有模型:torch.hub
ResNet(CBAM)源码解析链接,增加ResNet的图:ResNet_CBAM源码
2.2 到底要不要用ImageNet预训练?
相关论文链接:Rethinking ImageNet Pre-training
这篇论文是Kaiming He, Ross Girshick, Piotr Dollár之作,这篇重新思考ImageNet预训练(Rethinking ImageNet Pre-training)就给出了他们的答案。
FAIR(Facebook AI Research)的三位研究员从随机初始状态开始训练神经网络,然后用COCO数据集目标检测和实例分割任务进行了测试。结果,丝毫不逊于经过ImageNet预训练的对手。
甚至能在没有预训练、不借助外部数据的情况下,和COCO 2017冠军平起平坐。
这里贴出来该论文的实验结果:
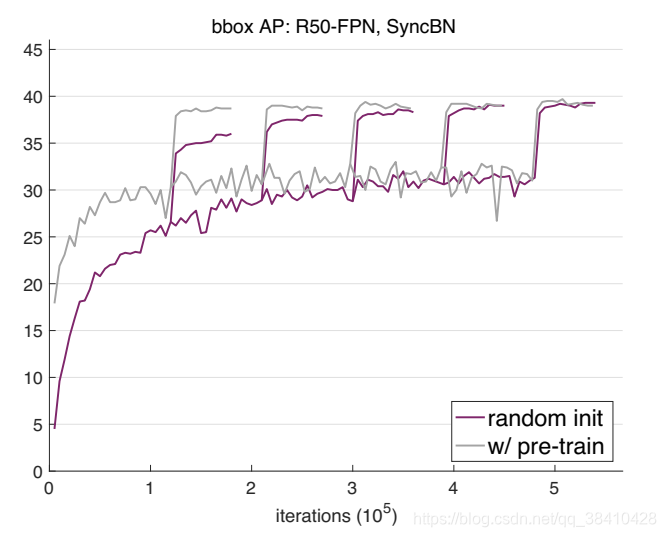
他们用2017版的COCO训练集训练了一个Mask R-CNN模型,基干网络是用了群组归一化(GroupNorm)的ResNet-50 FPN。
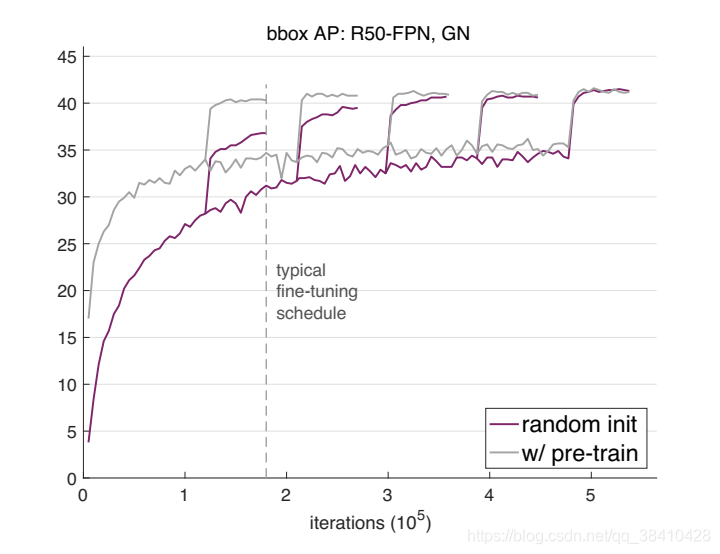
随后,用相应的验证集评估随机权重初始化(紫色线)和用ImageNet预训练后再微调(灰色线)两种方法的边界框平均检测率(AP)。
可以看出,随机权重初始化法开始不及预训练方法效果好,但随着迭代次数的增加,逐渐达到了和预训练法相当的结果。
为了探索多种训练方案,何恺明等人尝试了在不同的迭代周期降低学习率。
结果显示,随机初始化方法训练出来的模型需要更多迭代才能收敛,但最终收敛效果不比预训练再微调的模型差。
主干网络换成ResNet-101 FPN,这种从零开始训练的方法依然呈现出一样的趋势:从零开始先是AP不及预训练法,多次迭代后两者终趋于不分上下。
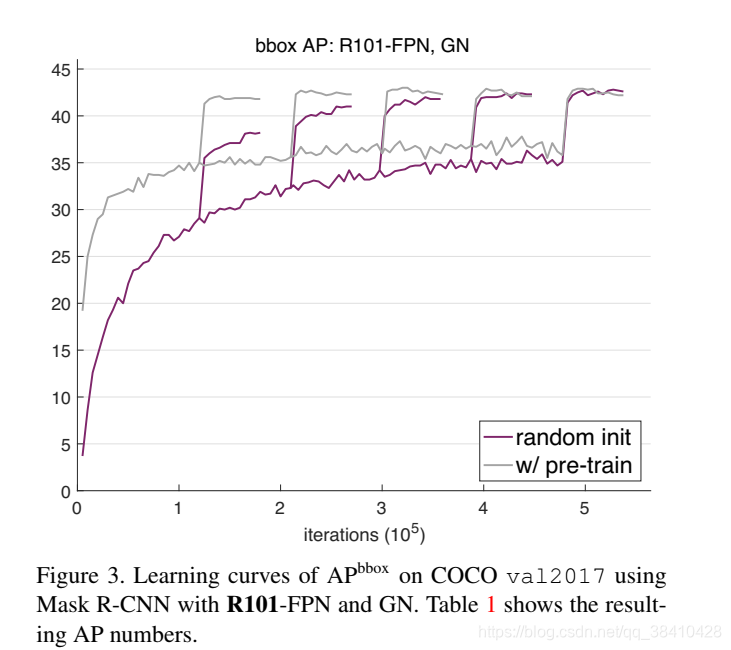
效果究竟能有多好?答案前面也说过了,和COCO 2017冠军选手平起平坐。
从零开始模型的效果,由COCO目标检测任务来证明。在2017版验证集上,模型的bbox(边界框)和mask(实例分割)AP分别为50.9和43.2;
他们还在2018年竞赛中提交了这个模型,bbox和mask AP分别为51.3和43.6。
这个成绩,在没有经过ImageNet预训练的单模型中是最好的。
这是一个非常庞大的模型,使用了ResNeXt-152 8×32d基干(如下表),GN归一化方法。从这个成绩我们也能看出,这个大模型没有明显过拟合,非常健壮(robust)。
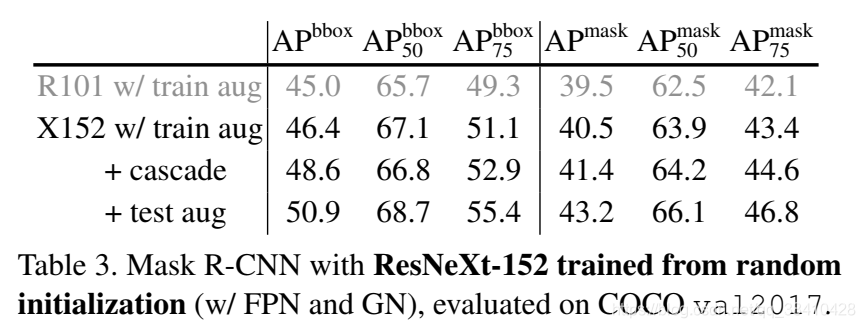
实验中,何恺明等人还用ImageNet预训练了同样的模型,再进行微调,成绩没有任何提升。
这种健壮性还有其他体现。
比如说,用更少的数据进行训练,效果还是能和预训练再微调方法持平。何恺明在论文中用Even more surprising来形容这个结果。
当他们把训练图像数量缩减到整个COCO数据集的1/3(35000张图)、甚至1/10(10000张图)时,经过多次迭代,随机初始化看起来还略优于预训练法的效果。
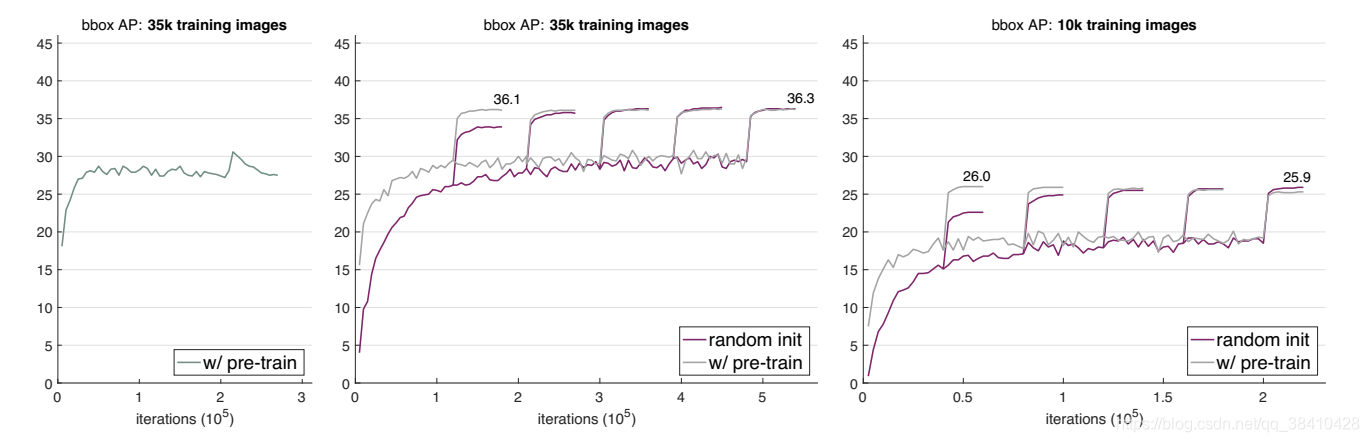
不过,10000张图已经是极限,继续降低数据量就不行了。当他们把训练数据缩减到1000张图片,出现了明显的过拟合。
想抛弃ImageNet预训练,用不着大动干戈提出个新架构。不过,两点小改动在所难免。
第一点是模型的归一化方法,第二点是训练长度。
我们先说模型归一化(Normalization)。
因为目标检测任务的输入数据通常分辨率比较高,导致批次大小不能设置得太大,所以,批归一化(Batch Normalization,BN)不太适合从零开始训练目标检测模型。
于是,何恺明等人从最近的研究中找了两种可行的方法:群组归一化(Group Normalization,GN)和同步批归一化(Synchronized Batch Normalization,SyncBN)。
GN是吴育昕和何恺明合作提出的,发表在ECCV 2018上,还获得了最佳论文荣誉提名。这种归一化方法把通道分成组,然后计算每一组之内的均值和方差。它的计算独立于批次维度,准确率也不受批次大小影响。
SyncBN则来自旷视的MegDet,和香港中文大学Shu Liu等人的CVPR 2018论文Path Aggregation Network for Instance Segmentation。这是一种跨GPU计算批次统计数据来实现BN的方法,在使用多个GPU时增大了有效批次大小。
归一化方法选定了,还要注意收敛问题,简单说是要多训练几个周期。
道理很简单:你总不能指望一个模型从随机初始化状态开始训练,还收敛得跟预训练模型一样快吧。
所以,要有耐心,多训练一会儿。
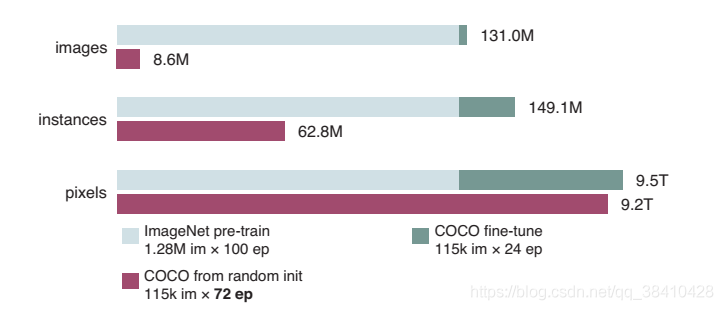
也就是说,要想从随机初始化状态开始训练,要有大量样本。
这篇论文还贴心地放出了从实验中总结的几条结论:
- 不改变架构,针对特定任务从零开始训练是可行的。
- 从零开始训练需要更多迭代周期,才能充分收敛。
- 在很多情况下,甚至包括只用10000张COCO图片,从零开始训练的效果不逊于用ImageNet预训练模型微调。
- 用ImageNet预训练能加速在目标任务上的收敛。
- ImageNet预训练未必能减轻过拟合,除非数据量极小。
- 如果目标任务对定位比识别更敏感,ImageNet预训练的作用较小。
所以,关于ImageNet预训练的几个关键问题也就有了答案:
它是必需的吗?并不是,只要目标数据集和计算力足够,直接训练就行。这也说明,要提升模型在目标任务上的表现,收集目标数据和标注更有用,不要增加预训练数据了。
它有帮助吗?当然有,它能在目标任务上数据不足的时候带来大幅提升,还能规避一些目标数据的优化问题,还缩短了研究周期。
我们还需要大数据吗?需要,但一般性大规模分类级的预训练数据集就不用了,在目标领域收集数据更有效。
我们还要追求通用表示吗?依然需要,这还是个值得赞赏的目标。















 3323
3323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









