








 超级会员免费看
超级会员免费看

前言
前面讲到explode操作是把某一列中的嵌套列表拆分为多行
那有时候我们会有着相反的需求,即按照某一列,把相同值对应的多行合并成一行
原理
主要用到groupby函数+apply函数
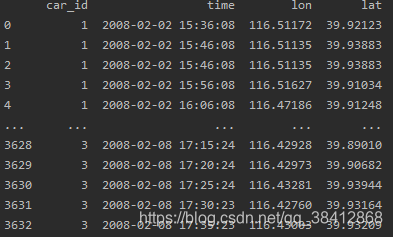
- 读取数据
data=pd.read_csv('data.csv',header=None)
data.columns=['car_id','time','lon','lat']
2. 多列合并为一列
def merge_cols(Series):
# 获取非空项
Series=Series[Series.notna()]
# 获取当行所有数据
value=Series.value
# 将每一行的数据变为一个一层嵌套的列表
result=[value[0],value[1],value[2]]
return result
data['tra_info']=data.iloc[:,1:].apply(merge_cols,axis=1)
也可以使用匿名函数写
data
 订阅专栏 解锁全文
订阅专栏 解锁全文
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











