







根据相同属性合并pandas行
代码
提供的代码可直接运行
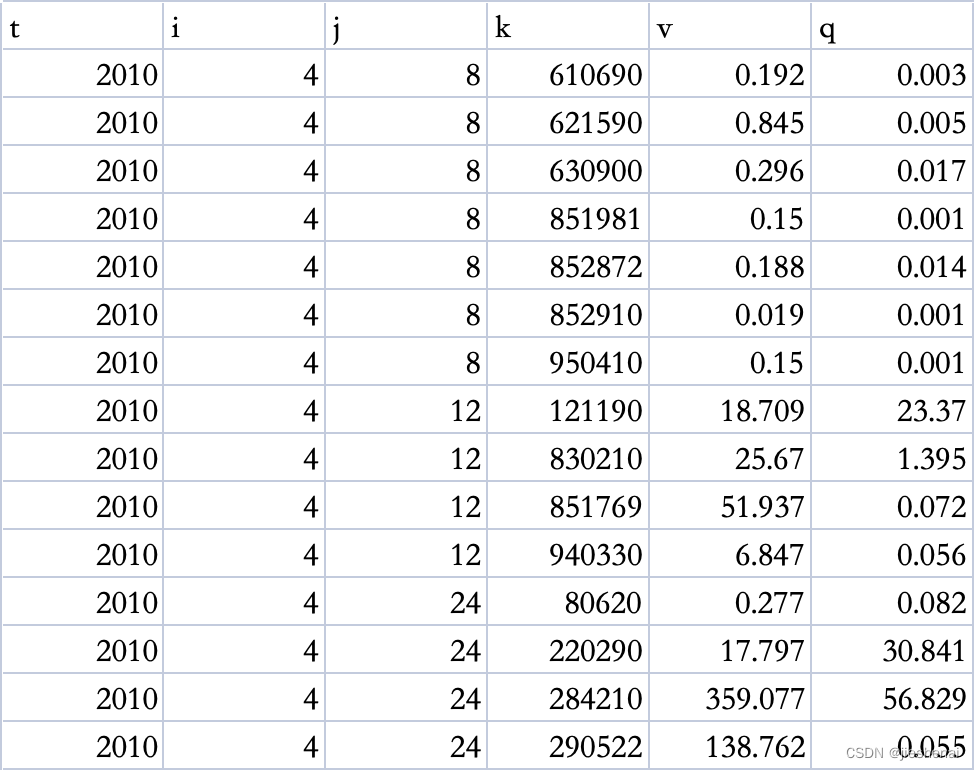
以如下表格数据为例,针对t, i, j相同的行,对其后的v属性数据实现相加。
data.csv的数据如下:
import os
import pandas as pd
from pandas import DataFrame, read_csv
filename = "文件路径/data.csv"
数据加载
若数据量大,可只加载几行数据
head = read_csv(filename, nrows=10)
init_df方法的作用:读取文件数据,创建一个新的容器存放最终的数据
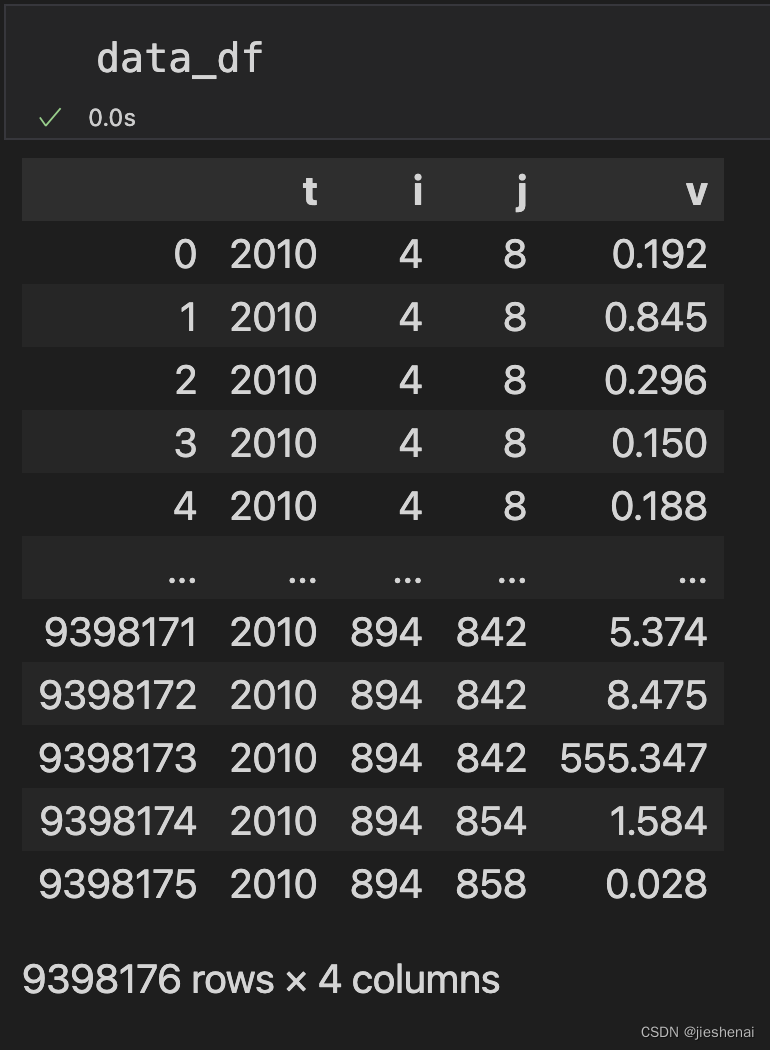
根据keys = ['t', 'i', 'j'],对key相同的属性行将其attrs=['v']的属性值进行相加。
只留下keys,attrs属性列,使用data.drop删除掉其他属性列。
keys = ['t', 'i', 'j']
attrs = ['v']
def init_df(filename):
data = read_csv(filename)
delete_col = set(data.columns.values) - set(keys) - set(attrs)
data = data.drop(list(delete_col), axis=1)
# 创建一个空容器,用于存放最终新的pandas数据
d = {key: [] for key in keys + attrs}
return data, pd.DataFrame.from_dict(d)
data_df: 读取的文件数据
new_df: 空的 pandas.DataFrame 容器
csv的数据是按照keys = ['t', 'i', 'j']的顺序排序好的。
故遍历data_df的每一行数据,将其与new_df最后一行数据的keys进行比较,若其相等则把v对应的属性值相加。
故需要实现如下几个函数
- 判断两行数据的
keys是否相等,is_equal() - 插入一行新数据到
new_df,insert()
自定义方法
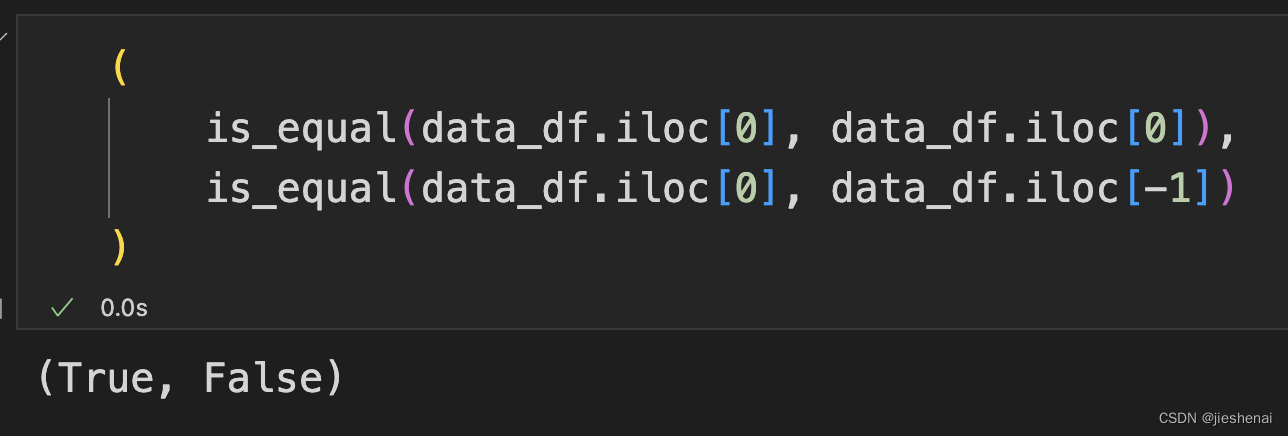
def is_equal(a: DataFrame, b: DataFrame) -> bool:
for key in keys:
if a[key] != b[key]:
return False
return True
# 属性值相加函数
def add(a: DataFrame, b: DataFrame):
assert is_equal(a, b)
for attr in attrs:
a[attr] += b[attr]
# 插入一行数据到容器最后一行
def insert(df: DataFrame, other: DataFrame):
df.loc[len(df)] = other
主函数
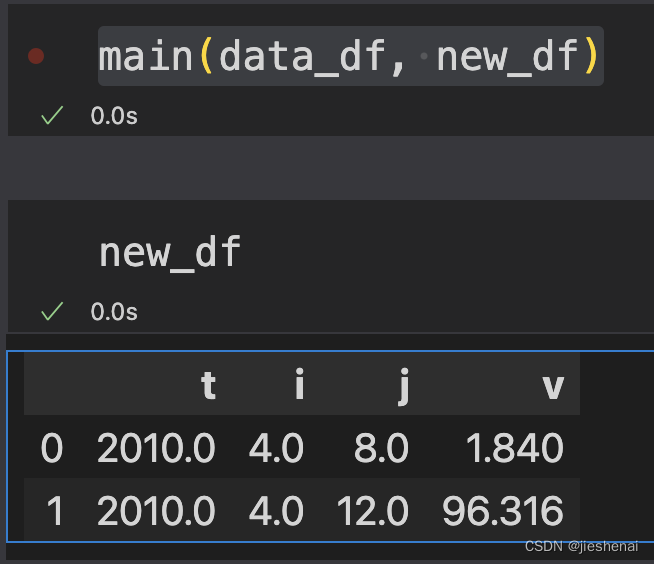
def main(df, res):
insert(res, df.iloc[0])
for idx in range(1, len(df)):
item = df.iloc[idx]
if is_equal(item, res.iloc[-1]):
add(res.iloc[-1], item)
else:
insert(res, item)
main(data_df, new_df)
点击查看此 ipynb 格式代码
完整代码如下
下图是一个完整的封装完成的py代码
处理source_folder文件夹下的所有表格数据,将其处理结果保存到output文件下。
import os
import pandas as pd
from pandas import DataFrame, read_csv
keys = ['t', 'i', 'j']
attrs = ['k']
def init_df(filename):
data = read_csv(filename)
delete_col = set(data.columns.values) - set(keys) - set(attrs)
data = data.drop(list(delete_col), axis=1)
d = {key: [] for key in keys + attrs}
return data, pd.DataFrame.from_dict(d)
def is_equal(a: DataFrame, b: DataFrame):
for key in keys:
if a[key] != b[key]:
return False
return True
def add(a: DataFrame, b: DataFrame):
assert is_equal(a, b)
for attr in attrs:
a[attr] += b[attr]
def insert(df: DataFrame, other: DataFrame):
df.loc[len(df)] = other
def main(df, res):
insert(res, df.iloc[0])
for idx in range(1, len(df)):
item = df.iloc[idx]
if is_equal(item, res.iloc[-1]):
add(res.iloc[-1], item)
else:
insert(res, item)
if __name__ == '__main__':
source_folder = '/Users/jshen/Desktop/jie/data'
output_folder = 'output'
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for root, dirs, files in os.walk(source_folder):
for file in files:
filename = os.path.join(root, file)
print(filename, "处理中...")
data, res_df = init_df(filename)
main(data, res_df)
res_df.to_csv(
f := os.path.join(
output_folder,
os.path.basename(filename)),
)
print("转换完成---> ", f)
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











