






1.思考因果关系
你是否注意到 YouTube 视频中的厨师在描述食物时表现得非常出色?“将酱汁收浓至丝绒般的质地”。如果你刚开始学习烹饪,你可能根本不知道这意味着什么。直接告诉我应该把这东西在炉子上放多久!在因果关系方面也是如此。假设你走进一家酒吧,听到有人讨论因果关系(可能是在经济学系旁边的酒吧),你会听到他们说收入的混杂因素使得识别移民对社区的影响变得困难,因此他们不得不使用工具变量。到目前为止,你可能不太明白他们在说什么。但我现在至少可以解决部分问题。
图形模型是因果关系的语言。它们不仅是你与其他勇敢且追求真相的因果关系爱好者交流的工具,也是让你自己的思考更加透明的工具。
作为起点,以潜在结果的条件独立性为例。这是我们进行因果推断时需要满足的主要假设之一:
( Y 0 , Y 1 ) ⊥ T ∣ X (Y_0, Y_1) \perp T | X (Y0,Y1)⊥T∣X
条件独立性使我们能够仅测量由于处理而导致的结果效应,而不是任何其他潜伏变量的影响。经典的例子是药物对患病患者的影响。如果只有病情严重的患者才能得到药物,那么可能看起来药物会降低患者的健康状况。这是因为病情严重程度的影响与药物的效应混杂在一起。如果我们把患者分为严重和非严重病例,并在每个子组中分析药物的影响,我们将得到更清晰的实际效应图。这种根据特征对人群进行细分的方法被称为控制或条件于 X。通过条件于严重病例,处理机制变得几乎随机。在严重组内的患者是否接受药物仅由于偶然,而不是由于高严重程度,因为在这一维度上所有患者都相同。如果在组内随机分配处理,那么处理将与潜在结果条件独立。
独立性和条件独立性是因果推断的核心。然而,理解它们可能相当困难。但如果我们使用正确的语言来描述这个问题,这种情况可以改变。这里就是因果图形模型的用武之地。因果图形模型是一种表示因果关系如何运作的方式。
图形模型如下所示:
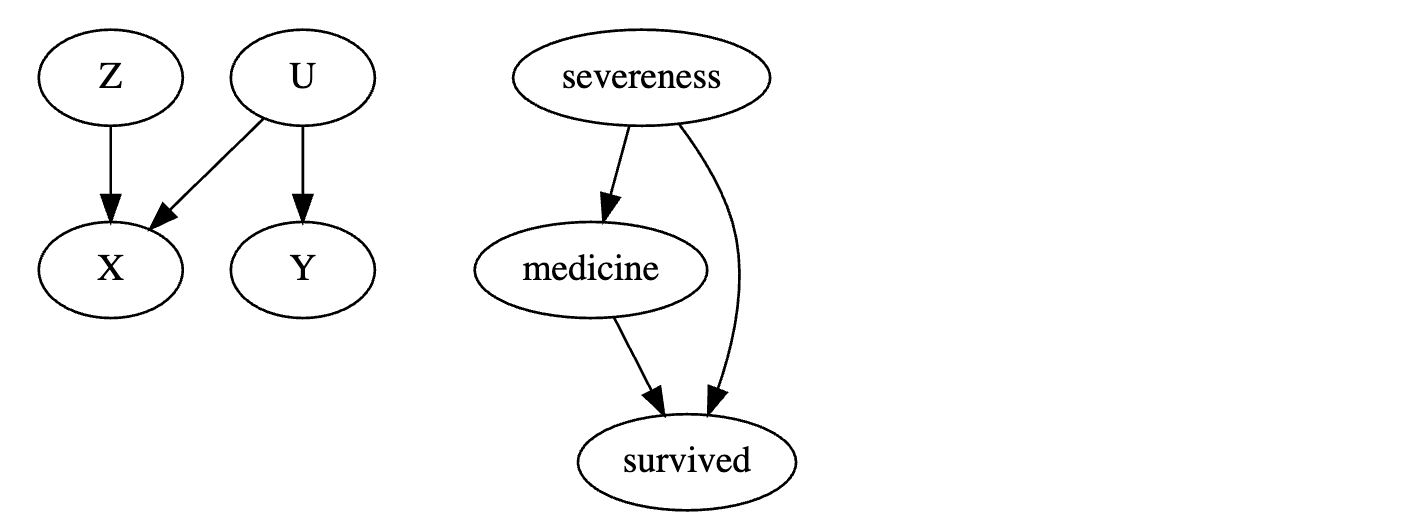
每个节点是一个随机变量。我们使用箭头或边来表示一个变量是否导致另一个变量。在上面的第一个图形模型中,我们表示 Z 导致 X,U 导致 X 和 Y。以更具体的例子来说,我们可以在第二个图中翻译我们对药物对患者生存影响的看法。病情严重程度导致药物使用和生存结果,药物也导致生存结果。正如我们将看到的,因果图形模型语言将帮助我们更清晰地思考因果关系,因为它阐明了我们对世界运作方式的信念。
2.图形模型速成课程
图形模型有整整一个学期的课程。但为了我们的目的,非常重要的是我们要理解图形模型所涉及的独立性和条件独立性假设。正如我们将看到的,独立性像水流经小溪一样流经图形模型。我们可以根据如何处理其中的变量来阻止或启用这种流动。为了理解这一点,让我们检查一些常见的图形结构和示例。它们将非常直接,但它们是理解图形模型中独立性和条件独立性一切的足够构建块。
首先,查看这个非常简单的图。A 导致 B,B 导致 C。或者 X 导致 Y,Y 导致 Z。
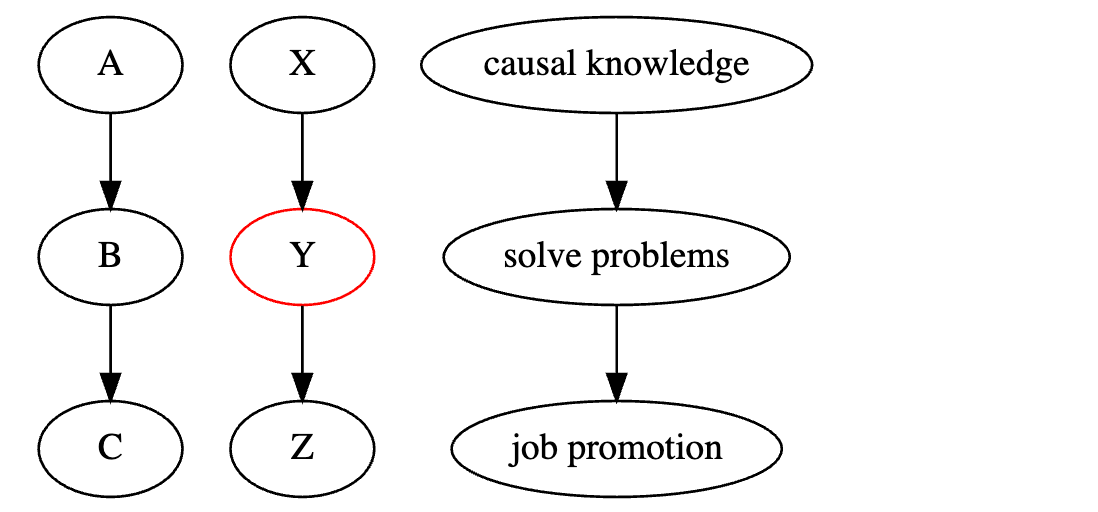
在第一个图中,依赖关系沿箭头方向流动。请注意,依赖关系是对称的,尽管这不太直观。以更具体的例子来说,假设了解因果推断是解决业务问题的唯一途径,而解决这些问题又是获得晋升的唯一途径。因此,因果知识意味着解决问题的能力,从而导致晋升。我们可以说在这里,晋升依赖于因果知识。因果专业知识越高,你获得晋升的机会就越大。而且,晋升机会越大,你拥有因果知识的可能性也越大。否则,晋升将变得困难。
现在,假设我对中间变量进行条件限制。在这种情况下,依赖关系被阻断。因此,给定 Y 时,X 和 Z 是独立的。在上面的图中,红色表示 Y 是一个被条件限制的变量。同样,在我们的例子中,如果我知道你善于解决问题,那么知道你了解因果推断不会给我提供任何关于你晋升机会的进一步信息。用数学术语来说, E [ P r o m o t i o n ∣ S o l v e p r o b l e m s , C a u s a l k n o w l e d g e ] = E [ P r o m o t i o n ∣ S o l v e p r o b l e m s ] E[Promotion|Solve \ problems, Causal \ knowledge]=E[Promotion|Solve \ problems] E[Promotion∣Solve problems,Causal knowledge]=E[Promotion∣Solve problems]。反之亦然;一旦我知道你解决问题的能力如何,知道你的晋升状态也不会给我提供任何关于你了解因果推断可能性的进一步信息。
一般来说,在从 A 到 C 的直接路径中,当我们对中间变量 B 进行条件限制时,依赖关系流动被阻断。或者,
A
⊥̸
C
A \not \perp C
A⊥C
和
A
⊥
C
∣
B
A \perp C | B
A⊥C∣B
现在,考虑一个叉结构。同一个变量导致图中的另外两个变量。在这种情况下,依赖关系通过箭头向后流动,我们有一个后门路径。我们可以通过对共同原因进行条件限制来关闭后门路径并阻断依赖关系。
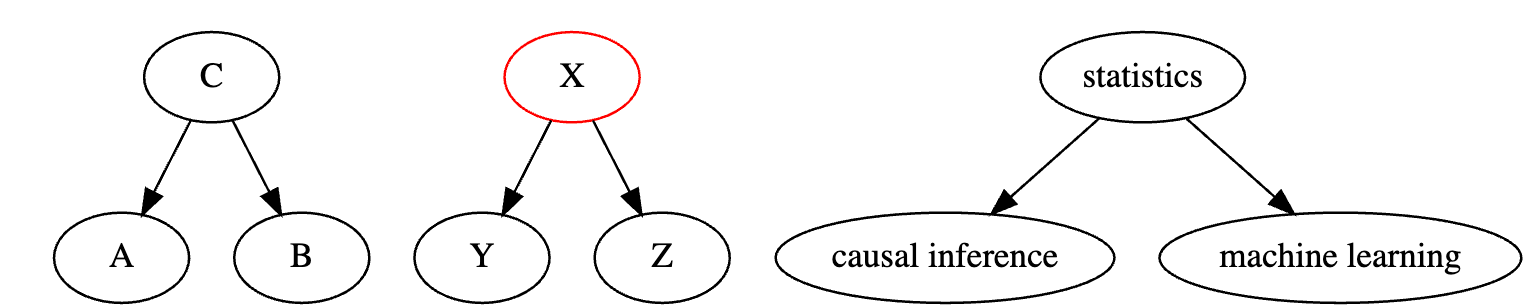
例如,假设你对统计学的了解导致你对因果推断和机器学习的更多了解。如果我不知道你的统计学知识水平,那么知道你擅长因果推断使我更有可能认为你也擅长机器学习。这是因为即使我不知道你的统计学知识水平,我也可以从你的因果推断知识中推断出来。如果你擅长因果推断,你可能在统计学方面也很出色,从而更有可能擅长机器学习。
现在,如果我对你的统计学知识进行条件限制,那么你对机器学习的了解与你对因果推断的了解就变得独立。知道你的统计学知识水平已经给了我所有我需要的信息来推断你的机器学习技能水平。在这种情况下,知道你对因果推断的了解不会提供任何进一步的信息。
一般来说,共享一个共同原因的两个变量是依赖的,但当我们对共同原因进行条件限制时,它们是独立的。或者
A
⊥̸
B
A \not \perp B
A⊥B
和
A ⊥ B ∣ C A \perp B | C A⊥B∣C
唯一缺失的结构是碰撞结构。当两个箭头在一个单一变量上碰撞时,我们可以说在这种情况下,两个变量共享一个共同效应。
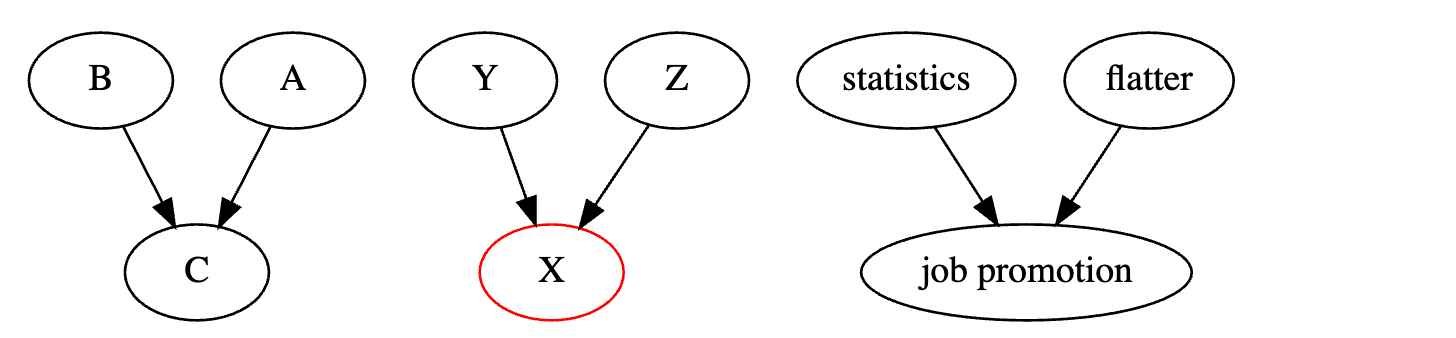
例如,考虑获得晋升的两种方式。你可以擅长统计学或拍马屁。如果我不对你的晋升进行条件限制,即我不知道你会不会晋升,那么你的统计学水平和拍马屁能力是独立的。换句话说,知道你有多擅长统计学不会告诉我你有多擅长拍马屁。另一方面,如果你确实获得了晋升,突然之间,知道你的统计学水平会告诉我你的拍马屁水平。如果你在统计学方面表现不佳但获得了晋升,你很可能擅长拍马屁。否则,你不会获得晋升。反之,如果你不擅长拍马屁,那么你一定在统计学方面很出色。这种现象有时被称为“解释排除”,因为一个原因已经解释了效应,使得另一个原因的可能性降低。
一般来说,对碰撞节点进行条件限制会打开依赖路径。不对它进行条件限制会保持路径关闭。或者
A ⊥ B A \perp B A⊥B
和
A ⊥̸ B ∣ C A \not \perp B | C A⊥B∣C
了解这三种结构后,我们可以推导出一个更一般的规则。当且仅当路径满足以下条件之一时,路径被阻断:
-
它包含一个非碰撞节点,该节点已被条件限制
-
它包含一个碰撞节点,该节点未被条件限制,并且其后裔也未被条件限制。
这里有一个关于依赖关系如何在图中流动的备忘单。我引用了斯坦福大学 Mark Paskin 的一个演示。箭头尖端有线的箭头表示独立性,而箭头尖端无线的箭头表示依赖性。
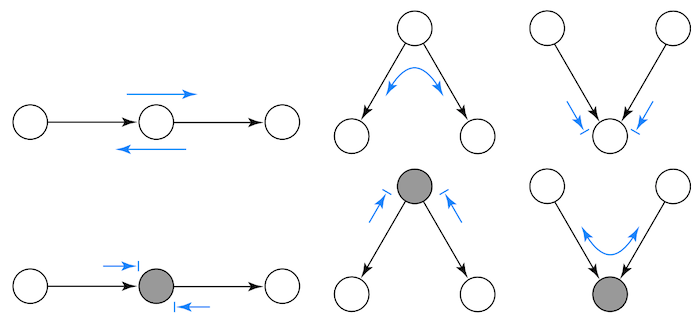
作为一个最终示例,尝试在以下因果图中找出一些独立性和依赖性关系。
-
Is D ⊥ C D \perp C D⊥C?
-
Is D ⊥ C ∣ A D \perp C| A D⊥C∣A ?
-
Is D ⊥ C ∣ G D \perp C| G D⊥C∣G ?
-
Is A ⊥ F A \perp F A⊥F ?
-
Is A ⊥ F ∣ E A \perp F|E A⊥F∣E ?
-
Is A ⊥ F ∣ E , C A \perp F|E,C A⊥F∣E,C ?

答案:
-
D ⊥ C D \perp C D⊥C。它包含一个未被条件限制的碰撞节点。
-
D ⊥̸ C ∣ A D \not\perp C| A D⊥C∣A.。它包含一个已被条件限制的碰撞节点。
-
D ⊥̸ C ∣ G D \not\perp C| G D⊥C∣G。它包含一个已被条件限制的碰撞节点的后裔。你可以将 G 视为 A 的某种代理。
-
A ⊥ F A \perp F A⊥F。它包含一个未被条件限制的碰撞节点 B->E<-F。
-
A ⊥̸ F ∣ E A \not\perp F|E A⊥F∣E。它包含一个已被条件限制的碰撞节点 B->E<-F。
-
A ⊥ F ∣ E , C A \perp F|E, C A⊥F∣E,C。它包含一个已被条件限制的碰撞节点 B->E<-F,但也包含一个已被条件限制的非碰撞节点。对 E 进行条件限制会打开路径,但对 C 进行条件限制又将其关闭。
了解因果图形模型使我们能够理解因果推断中出现的问题。正如我们所见,问题总是归结为偏差。
E [ Y ∣ T = 1 ] − E [ Y ∣ T = 0 ] = E [ Y 1 − Y 0 ∣ T = 1 ] ⏟ A T E T + { E [ Y 0 ∣ T = 1 ] − E [ Y 0 ∣ T = 0 ] } ⏟ B I A S E[Y|T=1] - E[Y|T=0] = \underbrace{E[Y_1 - Y_0|T=1]}_{ATET} + \underbrace{\{ E[Y_0|T=1] - E[Y_0|T=0] \}}_{BIAS} E[Y∣T=1]−E[Y∣T=0]=ATET E[Y1−Y0∣T=1]+BIAS {E[Y0∣T=1]−E[Y0∣T=0]}
图形模型使我们能够诊断我们正在处理的偏差类型以及需要使用哪些工具来纠正它们。
3.混杂偏差
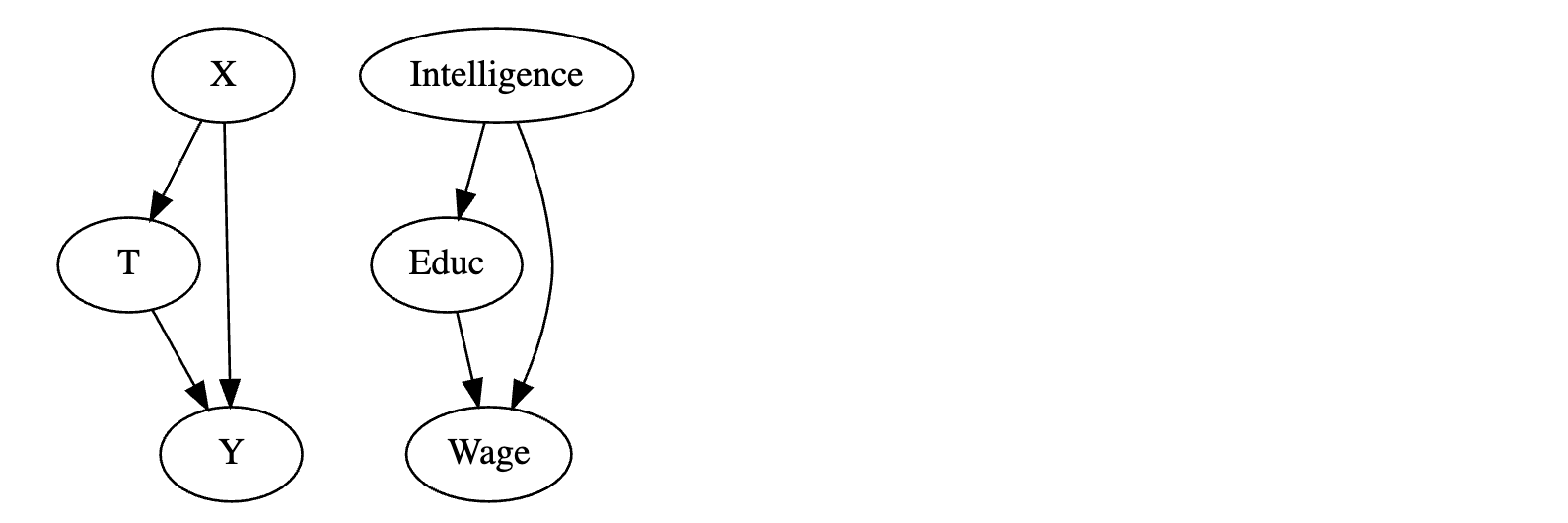
第一个重要的偏差原因是混杂。当处理和结果共享一个共同原因时就会发生混杂。例如,假设处理是教育,结果是收入。很难知道教育对工资的因果效应,因为两者都共享一个共同原因:智力。因此,我们可以认为,受教育程度高的人收入更高仅仅是因为他们更聪明,而不是因为他们受教育程度更高。我们需要关闭处理和结果之间的所有后门路径,以识别因果效应。如果我们这样做,唯一剩下的效应将是直接效应 T->Y。在我们的例子中,如果我们控制智力,即比较智力水平相同但教育水平不同的人,结果的差异将仅由于教育水平的差异,因为此时智力对所有人来说都是相同的。为了纠正混杂偏差,我们需要控制处理和结果的所有共同原因。
不幸的是,控制所有共同原因并不总是可能的。有时,存在未知的原因或已知但无法测量的原因。智力的情况就是一个后者。我将用 U 来表示未测量的变量。现在,假设智力不能直接影响你的教育。它影响你的 SAT 成绩,但 SAT 决定了你的教育水平,因为它为你打开了进入好大学的可能性。即使我们无法控制无法测量的智力,我们也可以控制 SAT 并关闭后门路径。
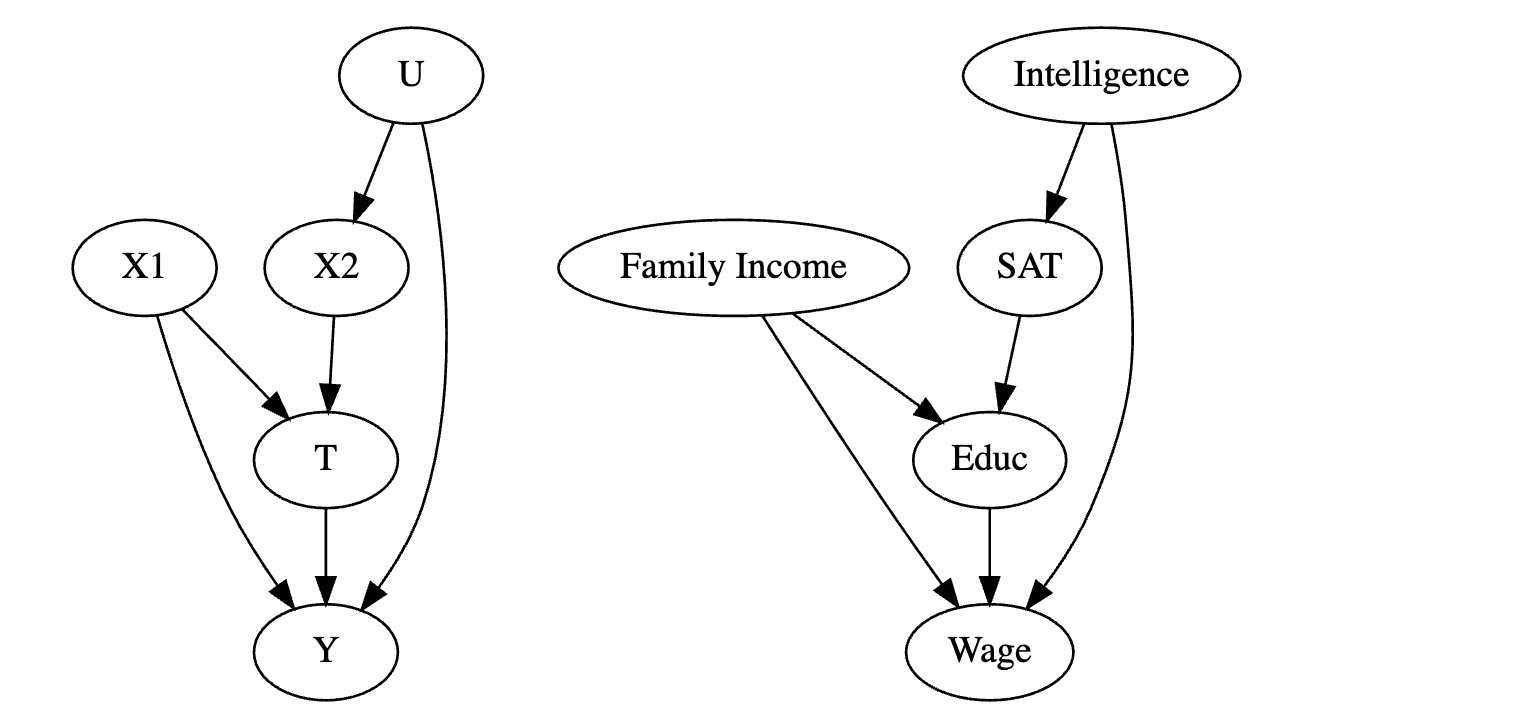
在下面的图中,对 X1 和 X2 或 SAT 和家庭收入进行条件限制足以关闭处理和结果之间的所有后门路径。换句话说,
(
Y
0
,
Y
1
)
⊥
T
∣
X
1
,
X
2
(Y_0, Y_1) \perp T | X1, X2
(Y0,Y1)⊥T∣X1,X2。因此,即使我们无法测量所有共同原因,如果我们控制可测量的变量,这些变量介于未测量变量对处理的影响之间,我们仍然可以实现条件独立性。一个快速说明,我们也有
(
Y
0
,
Y
1
)
⊥
T
∣
X
1
,
U
(Y_0, Y_1) \perp T | X1, U
(Y0,Y1)⊥T∣X1,U,但由于我们无法观察 U,我们无法对其进行条件限制。
但如果情况并非如此呢?如果未测量变量直接导致处理和结果呢?在下面的例子中,智力现在导致教育和收入。因此,在处理教育和结果工资之间的关系中存在混杂。在这种情况下,我们无法控制混杂因素,因为它无法测量。然而,我们有其他已测量的变量可以作为混杂因素的代理。这些变量不在后门路径中,但控制它们将有助于降低偏差(但不会消除偏差)。这些变量有时被称为替代混杂因素。
在我们的例子中,我们无法测量智力,但我们可以测量它的一些原因,如父母的教育程度,以及它的一些影响,如智商或 SAT 成绩。控制这些替代变量不足以消除偏差,但会有所帮助。
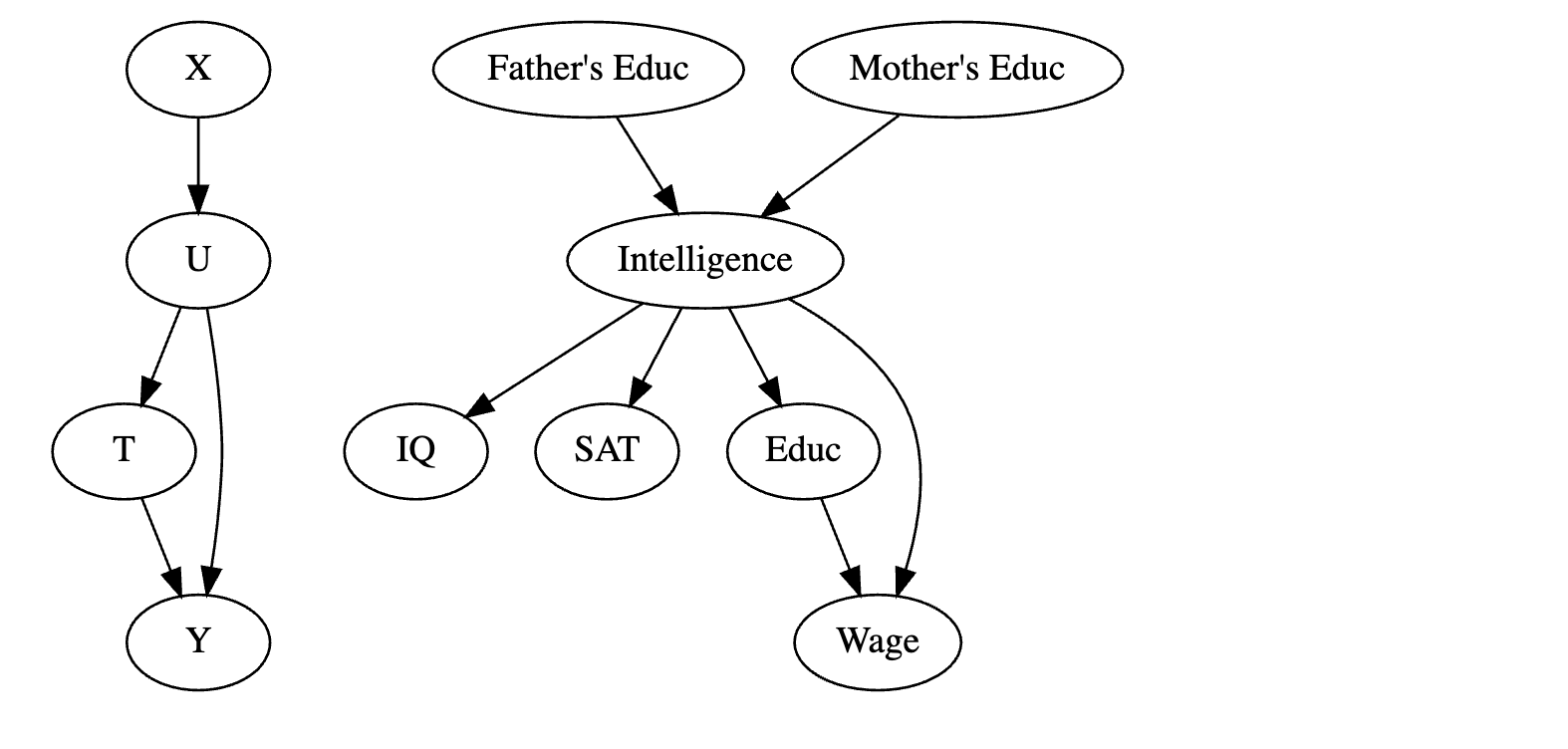
4.选择偏差
你可能认为将所有能测量的变量添加到模型中是一个好主意,以确保没有混杂偏差。好吧,再想想。

第二种重要的偏差来源是我们将称之为选择偏差。在这里,我认为将它与混杂偏差区分开来是有建设性的,所以我将坚持使用它。如果混杂偏差发生在我们没有控制共同原因时,选择偏差更多地与效应相关。在这里,我必须谨慎,因为经济学家倾向于将各种偏差都称为选择偏差。
通常,当我们在模型中控制了过多变量时,就会出现选择偏差。可能的情况是,处理和潜在结果在边缘上是独立的,但一旦我们对碰撞节点进行条件限制,它们就会变得依赖。
假设借助某种奇迹,你终于可以随机分配教育以测量其对工资的影响。但为了确保没有混杂因素,你控制了许多变量。其中,你控制了投资。但投资并不是教育和工资的共同原因。相反,它是两者的后果。受教育程度高的人收入更高且投资更多。此外,收入高的人也投资更多。由于投资是一个碰撞节点,通过对它进行条件限制,你打开了处理和结果之间的第二条路径,这将使测量直接效应变得更加困难。一种思考方式是,通过对投资进行控制,你在观察投资相同的小群体中寻找教育效应。但这样做时,你也在间接和无意中限制了工资的变化程度。因此,你无法看到教育如何改变工资,因为你没有允许工资按应有的方式变化。
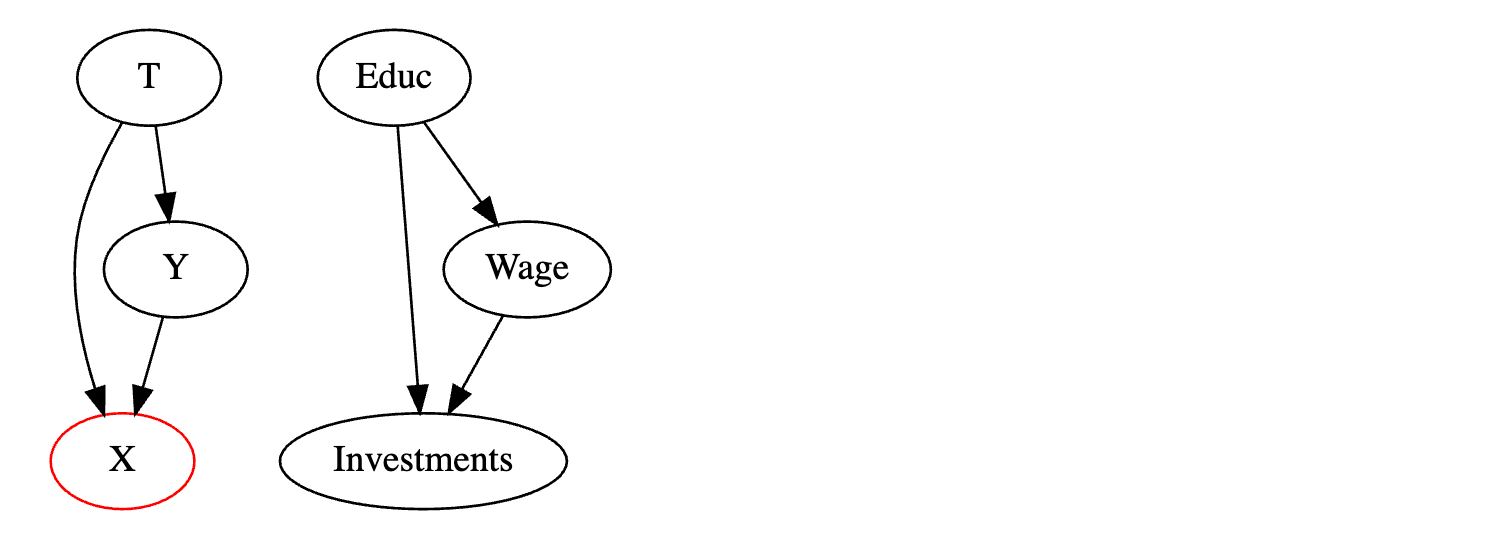
假设投资和教育只取 2 个值来说明为什么会出现这种情况。无论人们是否投资。他们是否受过教育。最初,当我们不对投资进行控制时,偏差项为零:
E
[
Y
0
∣
T
=
1
]
−
E
[
Y
0
∣
T
=
0
]
=
0
E[Y_0|T=1] - E[Y_0|T=0] = 0
E[Y0∣T=1]−E[Y0∣T=0]=0,因为教育是随机分配的。这意味着,无论是否接受教育,人们在没有接受教育的情况下将拥有的工资
W
a
g
e
0
Wage_0
Wage0 是相同的。但如果我们对投资进行条件限制会发生什么?
在那些投资的人中,可能的情况是 E [ Y 0 ∣ T = 0 , I = 1 ] > E [ Y 0 ∣ T = 1 , I = 1 ] E[Y_0|T=0, I=1] > E[Y_0|T=1, I=1] E[Y0∣T=0,I=1]>E[Y0∣T=1,I=1]。也就是说,即使没有教育也能设法做到有投资这一点的人,无论其教育水平如何,其潜在工资 W a g e 0 ∣ T = 0 Wage_0|T=0 Wage0∣T=0 可能高于受过教育组如果没有接受教育将拥有的工资 W a g e 0 ∣ T = 1 Wage_0|T=1 Wage0∣T=1。对于没有投资的人,我们也可能有 E [ Y 0 ∣ T = 0 , I = 0 ] > E [ Y 0 ∣ T = 1 , I = 0 ] E[Y_0|T=0, I=0] > E[Y_0|T=1, I=0] E[Y0∣T=0,I=0]>E[Y0∣T=1,I=0]:那些即使受过教育也没有投资的人,如果没有接受教育,他们的工资可能低于那些没有投资也没有接受教育的人。
从纯粹的图形论证角度来看,如果有人投资,知道他们拥有高教育水平可以排除第二种原因,即工资。在投资的条件下,较高的教育水平与较低的工资相关,我们有一个负偏差
E
[
Y
0
∣
T
=
0
,
I
=
i
]
>
E
[
Y
0
∣
T
=
1
,
I
=
i
]
E[Y_0|T=0, I=i] > E[Y_0|T=1, I=i]
E[Y0∣T=0,I=i]>E[Y0∣T=1,I=i].
顺便说一下,如果我们对共同效应的任何后裔进行条件限制,所有这些讨论都是正确的。

类似的情况发生在我们对处理的中介变量进行过度控制时。中介变量是位于处理和结果之间的变量。它介导了因果效应。例如,再次假设你可以随机分配教育。但为了确保万无一失,你决定控制一个人是否拥有白领工作。同样,这种条件限制会使因果效应估计产生偏差。这一次,不是因为它打开了一个带有碰撞节点的前门路径,而是因为它关闭了处理起作用的渠道之一。在我们的例子中,获得白领工作是更多教育导致更高工资的一种方式。通过对其进行控制,我们关闭了这一渠道,只留下了教育对工资的直接影响。
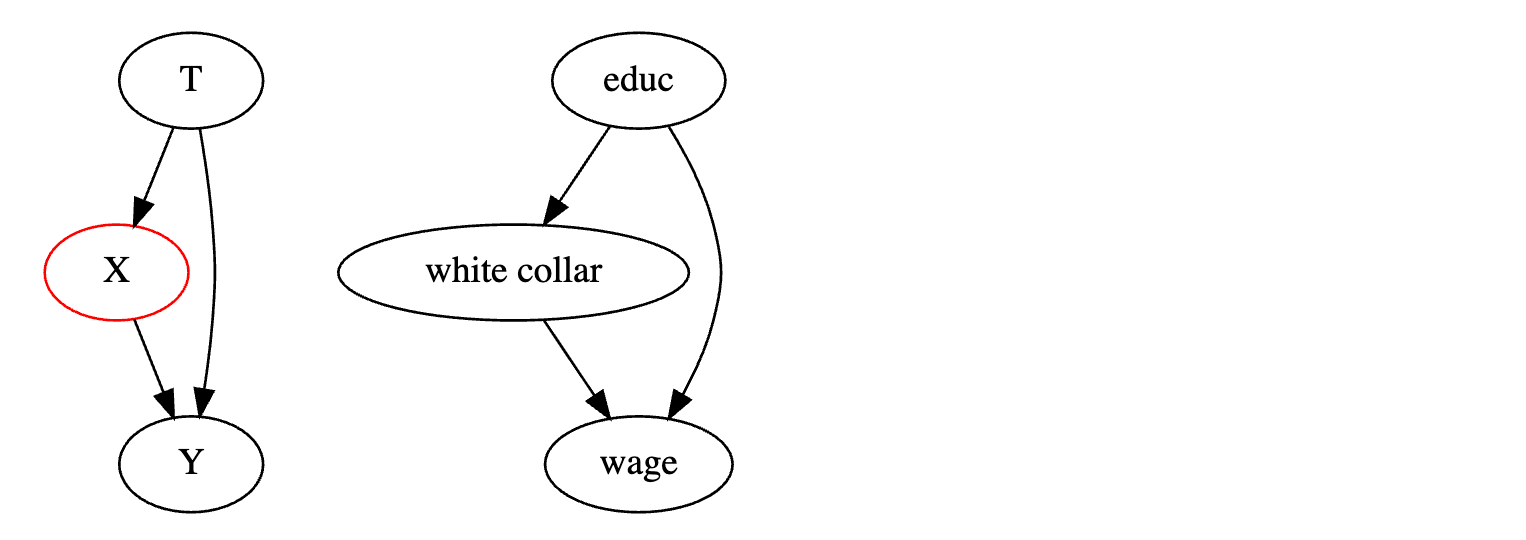
从潜在结果的角度来看,由于随机分配,偏差为零
E
[
Y
0
∣
T
=
0
]
−
E
[
Y
0
∣
T
=
1
]
=
0
E[Y_0|T=0] - E[Y_0|T=1] = 0
E[Y0∣T=0]−E[Y0∣T=1]=0。然而,如果我们对白领工人进行条件限制,我们有
E
[
Y
0
∣
T
=
0
,
W
C
=
1
]
>
E
[
Y
0
∣
T
=
1
,
W
C
=
1
]
E[Y_0|T=0, WC=1] > E[Y_0|T=1, WC=1]
E[Y0∣T=0,WC=1]>E[Y0∣T=1,WC=1]。这是因为在那些没有接受教育却设法获得白领工作的人中,他们可能比那些需要教育帮助才能获得相同工作的人更勤奋。同样的推理也适用于那些没有白领工作的人,我们也可能有
E
[
Y
0
∣
T
=
0
,
W
C
=
0
]
>
E
[
Y
0
∣
T
=
1
,
W
C
=
0
]
E[Y_0|T=0, WC=0] > E[Y_0|T=1, WC=0]
E[Y0∣T=0,WC=0]>E[Y0∣T=1,WC=0],因为那些即使受过教育也没有获得白领工作的人可能比那些没有获得白领工作也没有接受教育的人更不勤奋。
在这种情况下,对中介变量进行条件限制会产生一个负偏差。这使得教育的效应看起来比实际更小。这是因为因果效应是正的。如果效应是负的,对中介变量进行条件限制会产生正偏差。在所有情况下,这种条件限制使效应看起来比实际更弱。
更直白地说,假设你必须在两名候选人之间选择你公司的职位。两人都有同样令人印象深刻的专业成就,但其中一人没有高等教育学位。你应该选择哪一个?当然,你应该选择没有高等教育学位的那个人,因为他设法取得了与另一个人相同的成就,但面临着对他不利的条件。

5.关键思想
我们研究了图形模型作为一种更好地理解和表达因果关系思想的语言。我们快速总结了图中的条件独立性规则。这帮助我们探索了可能导致偏差的三种结构。
- 第一种是混杂,当处理和结果有一个我们没有考虑或控制的共同原因时就会发生。
- 第二种是由于对共同效应进行条件限制而导致的选择偏差。
- 第三种结构也是一种形式的选择偏差,这次是由于对中介变量过度控制。即使处理是随机分配的,这种过度控制也可能导致偏差。选择偏差通常可以通过简单地不采取行动来修复,这就是为什么它是危险的。因为我们倾向于行动,我们往往认为控制事物的想法是聪明的,而它们可能弊大于利。
参考文献
我喜欢将这本书视为对 Joshua Angrist、Alberto Abadie 和 Christopher Walters 的致敬,他们的计量经济学课程非常出色。这里的大多数想法都来自他们在美国经济协会的课程。观看他们的课程让我在艰难的 2020 年保持理智。
我也想参考 Angrist 的精彩书籍。它们让我明白计量经济学,或他们所说的“Metrics”,不仅极其有用,而且非常有趣。
我最后的参考书是 Miguel Hernan 和 Jamie Robins 的书。它一直是我在回答最棘手的因果问题时值得信赖的伙伴。

贡献
《为勇敢且追求真相者提供的因果推断》是一份关于因果推断的开源材料,因果推断是科学的统计学。其目标是在经济上和智力上都易于获取。它仅使用基于 Python 的免费软件。
如果你发现这本书有价值并希望支持它,请访问 Patreon。如果你尚未准备好进行财务贡献,你也可以通过修正错别字、提出编辑建议或反馈你无法理解的段落来提供帮助。前往书籍的存储库并打开一个 issue。最后,如果你喜欢这个内容,请与可能觉得它有用的人分享,并在 GitHub 上给它一个星。

















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









