



Baselines(基线):是指在实验或评估中用于比较的基准方法或模型。它们通常是已有的、相对简单或广泛认可的模型,用来衡量新方法或模型的改进程度。
HotpotQA数据集:一个多跳(Multi-hop)问答数据集,需要模型结合多个文档的信息来回答问题。
2WikiMultiHopQA数据集:一个多跳问答数据集,来源于 Wikipedia,问题的答案需要结合两个不同的维基页面的信息。
MuSiQue数据集:问题的答案需要结合多个段落的信息(不仅仅是两个文档),以增强推理的难度。
ARC-Challenger(McQ多项选择):是一个多项选择推理数据集,测试模型的常识推理和科学知识。
PubHealth(公共卫生事实验证数据集):一个关于公共卫生事实验证的数据集,用于判断一条健康相关的声明是真实、虚假,还是需要更多信息。
PopQA(开放式问答):是一个开放域问答数据集,主要测试模型的世界知识和事实性知识,测试通用知识能力。
Biography:是一个针对长文本生成任务的数据集,主要用于评估模型在生成具有生动描述和丰富细节的长篇人物传记内容时的能力。
Bamboogle:是一个多跳问答(multi-hop question answering,简称QA)数据集,旨在评估模型在处理涉及多个推理步骤的复杂问题时的表现。
SqUAD:主要用于问答系统的训练和评估。这个数据集的目标是测试机器理解文本并从中提取信息的能力。
Natural Questions (NQ):该数据集特别强调了对 真实世界问题 的理解,而非仅仅依赖于标准化或特定格式的问题。
ObliQA:一个用于评估 开放域问答 系统的自然语言处理(NLP)数据集。该数据集专注于 理解复杂问题和推理能力,特别是在处理带有模糊、复杂或间接语言的情况下。
评估指标:
问答指标:
- EM:模型生成的答案和标准答案完全一致才能的1分,否则0分。最终取所有测试样本的平均值,0~1之间越接近1越好
- F1分数:是召回率和精确率的调和平均数,当精确率和召回率接近时,F1就会高否则就会低,能综合反映模型的整体表现。
- 精确率(Precision):预测结果中,预测为正确的样本中真正的正确的,占预测为正确的数量之比。
- 召回率:预测结果中,预测到的真正正确的,占数据集中真正正确的比值。
- RePASs:是一种用于评估生成的答案在多个维度上稳定性和准确性的评分方法
Entailment Score (Es):衡量生成的答案中每个句子在多大程度上得到了检索到的段落中的句子的支持。
Contradiction Score (Cs):评估生成的答案中是否有任何句子与检索到的段落中的信息相矛盾。
Obligation Coverage Score (OCs):检查生成的答案是否涵盖了检索到的段落中所有的义务内容。
检索指标:
- 检索精确率:检索器检索到的段落集中和真实答案相关的段落集合于检索到的段落的比值。越接近1越好。
- 检索的召回率:检索到的段落中和答案相关的段落数量占全部和答案相关的段落数量的比值。
- 检索的F1分数:是检索准确率和检索召回率的调和平均数。
- NDCG@K:是一种用于评估信息检索(IR)系统性能的指标,主要衡量检索结果的排序质量。归一化后的 NDCG@K 值介于 0 和 1 之间,值越接近 1,表示检索结果的排序质量越高。高相关性的文档是否排在靠前的位置。
- MAP@10(前 10 的平均精确度):是精确度的平均值,在计算时考虑了每个查询的精确度,并对所有查询的平均值进行求解。是一个综合指标,反映了系统在多个查询上的平均表现。
- 准确率(Accuracy):准确率衡量的是模型正确预测的样本占所有样本的比例。
以往研究中:
PopQA、PubHealth 和 ARC-Challenge 采用准确率(Accuracy)
Biography 采用 FactScore(Min et al., 2023)作为评估指标。
- FactScore:将生成的答案与金标准答案进行对比。FactScore 通过检查文本中的事实是否与标准答案一致,并根据匹配程度给出一个评分。评分通常是一个介于 -1 和 1 之间的值。-1 代表生成的答案完全错误,0 代表答案不明确或部分正确,而 1 代表答案完全正确并包含必要的事实细节。
实验案例:
一、案例一
数据集:PopQA、Biography、PubHealth、Arc-Challenge
评估指标:
评估LLM:准确率和FactScore
评估检索器:准确率
数据集在LLM和其他RAG方法上的性能
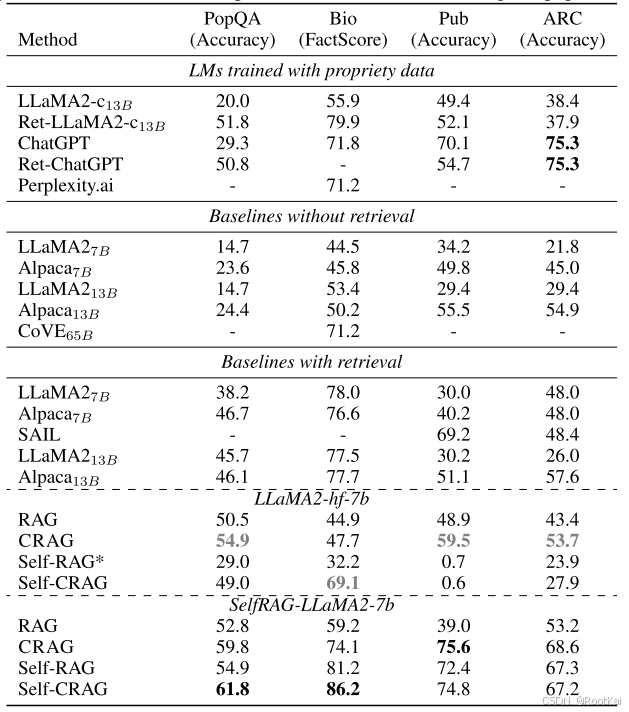
基线:
- 无检索的LLM
- 有检索的LLM
- 标准的RAG
- 高级RAG
二、案例二
数据集:HotpotQA、2WikiMultiHopQA、MuSiQue多跳问答数据集
评估指标:
评估LLM:准确匹配(EM)、F1 分数
评估检索器:检索F1
三、案例三
数据集:ObliQA
评估指标:
评估LLM:RePASs
评估检索器:Recall@10 MAP@10

















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









