







一、动机
不完美的检索器,会误导LLM,目前传统的RAG方法通过直接预测答案来应对这个问题,这种隐式去噪,难以解释和验证,显示去噪监督成本高。
二、解决方案
提出新的RAG框架INSTRUCTRAG旨在使语言模型(LM)显式去噪检索到的信息,并通过生成去噪响应(即推理)来证明其预测的最终答案。
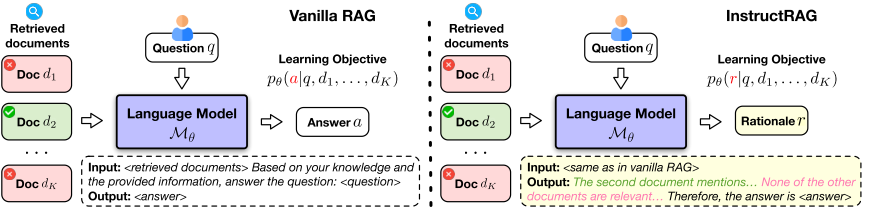
这个框架不需要额外的监督。
两个步骤:
1.给定一组问题-答案对,和可能带有噪声的检索文档,提示一个指令微调的LM合成去噪推理,这个推理就是分析文档并阐明这些文档是如何产生真实答案的。
2.生成的这些推理可以作为上下文学习示例或监督微调数据来使用,使LLM显示的学习去噪检索的内容。
三、方法实现
1.根据指令生成推理

给定一个问答对和一组检索到的文档,通过去噪指令提示一个现成的LLM生成相应的推理,区分有用的文档和噪声文档,并解释这些文档如何推到出真实答案。(为了去报合成的推理与真实答案一致,使用简单的字符串匹配来评估一致性),然后增强标准数据集
2.在RAG中学习去噪推理
通过上一步的推理增强数据集T+,开发一个推理学习器,直接学习RAG的显式去噪,并采用高效的学习策略分别是:
1.INSTRUCTRAG-ICL:
模型通过上下文学习ICL来学习去噪推理。给定一个测试问题q和一组检索到的文档,首先从推理增强的训练数据集T+中随机抽取N个示例,然后提示模型遵循这些示例并生成推理r。

2.INSTRUCTRAG-FT
这个是通过SFT学习去噪推理。
训练和推理的数据格式:
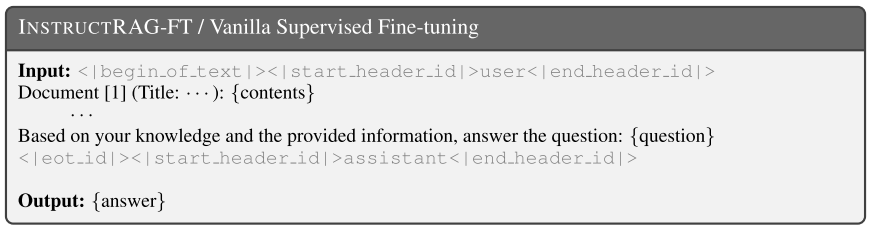
核心目标:
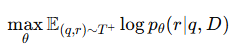
四、实验结果
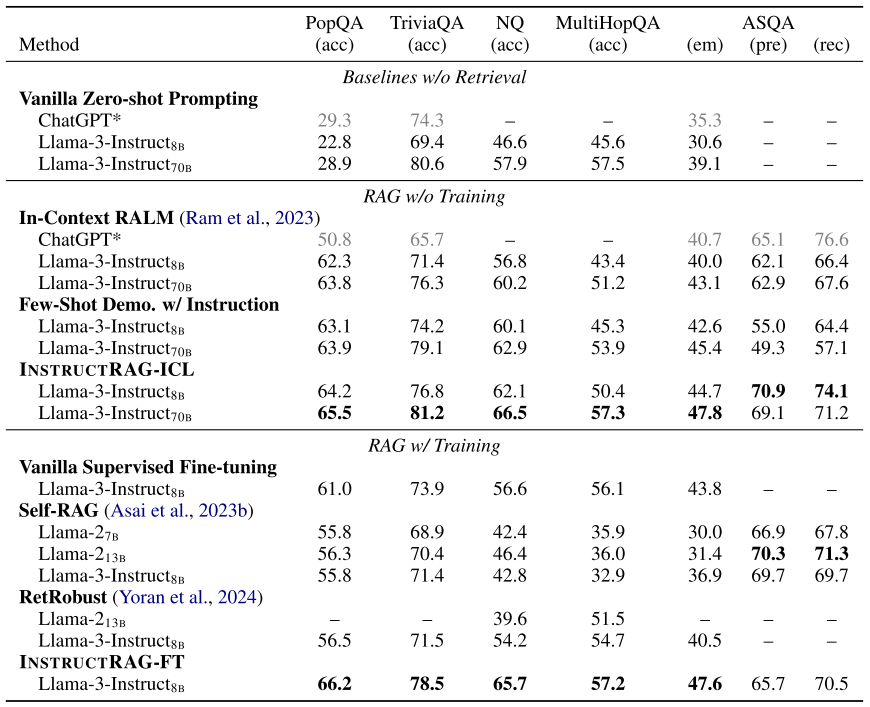
评估指标:
Precision = (检索到的相关文档数量) / (检索到的文档总数)
Recall = (检索到的相关文档数量) / (数据库中所有相关文档的数量)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









