






 本文介绍了如何通过ArmSPE硬件加速器收集CPUpipeline执行信息,以及如何利用perftool如perfrecord和Perfc2c工具检测共享问题。Armstreamline工具支持SPE,使得系统profiling更加高效。重点在于通过硬件优化减少采样对性能的影响,提高采样率并准确追踪指令地址。
本文介绍了如何通过ArmSPE硬件加速器收集CPUpipeline执行信息,以及如何利用perftool如perfrecord和Perfc2c工具检测共享问题。Armstreamline工具支持SPE,使得系统profiling更加高效。重点在于通过硬件优化减少采样对性能的影响,提高采样率并准确追踪指令地址。
触发PMU中断到内核中断处理,调用PMU driver然后将record通过软件写入buffer
这些过程是比较耗时耗CPU执行cycle的。为了避免对正常应用/系统的性能影响,这种方式不能将采样频率设置太高。
利用perf tool的’perf record‘可以获取这些信息
Arm SPE可以通过硬件采集CPU pipeline执行过程中的发生的event, 然后根据软件设置的count number周期性地(当采集的event数量达到count number,即count down到0时)采样这时这条指令的执行信息,并由硬件产生SPE的record packet, 并由硬件将packet写入外部内存。你可以简单理解为SPE将之前PMU软件需要做的事情硬件化实现了(SPE能记录的event种类一般会少于PMU event,但也会有一些PMU没有的信息)。
由上面介绍的SPE工作方式可知,SPE采样的指令地址信息是非常精确的,不会漂移。而且采样记录的开销较小,因而采样率可以设置的很高(当然也是有限制的,不会到每条指令都被采样的精度)。
SPE packet

Note:
- 记录PC的address packet包含采样的PC virtual address, EL level和安全状态。
- Branch操作可能会产生一个记录Branch target address的address packet
- Data source Packet是CPU实现相关的(Implementation Dependent)
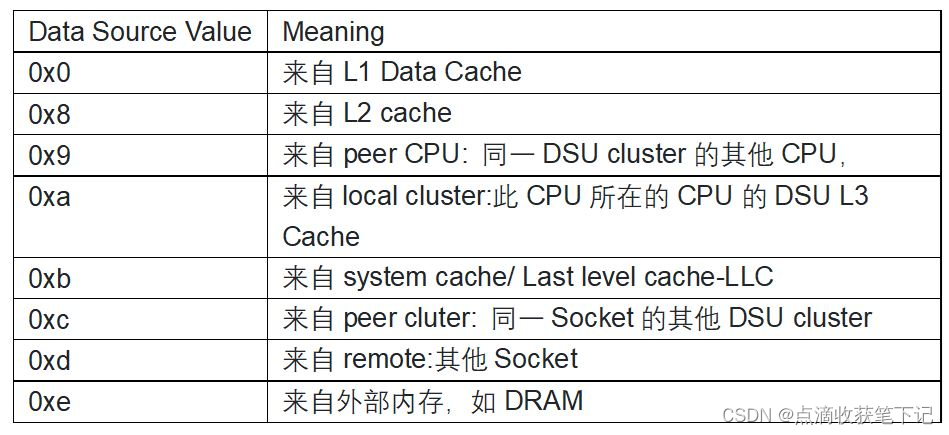
Perf c2c工具
Perf c2c工具可以用来检测cache line的false sharing的场景。在arm上也可以利用SPE来获取所需要的信息。
当多个Core同时读写同一个内存地址时,需要通过Cache Coherence硬件机制完成一致性,会产生额外的性能开销。这种情况是真正的“共享”。
当多个Core同时读写多个不同的地址,但这些地址由于相邻会被映射到同一个Cache Line时,虽然从程序逻辑上不存在内存地址“共享”,但因为Cache实现机制的问题存在一个隐式的“共享”,我们称之为False Sharing。
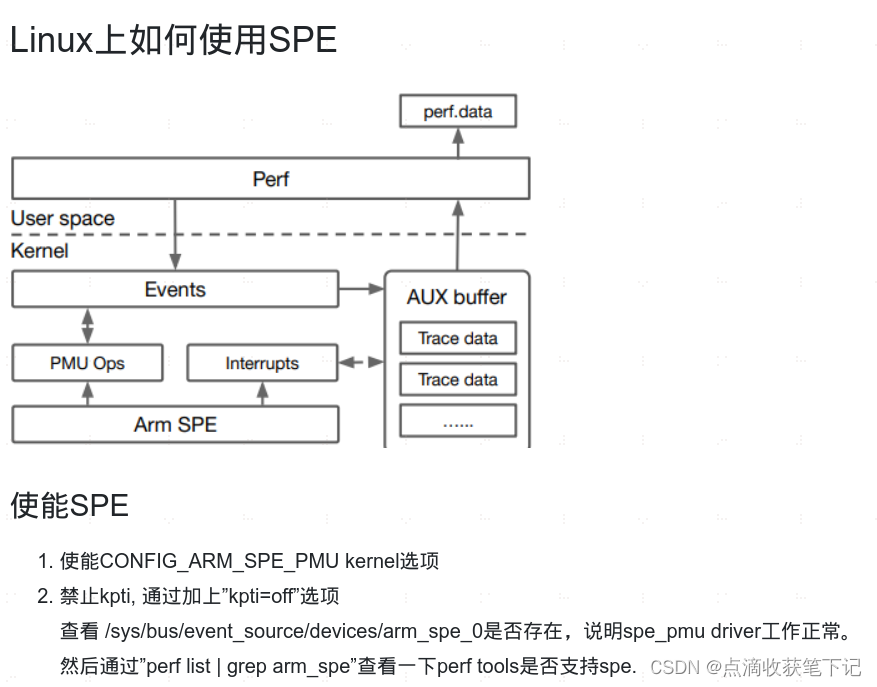
Arm streamline对SPE的支持
Arm streamline工具已经支持SPE,可以利用SPE数据进行系统的profiling。

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









