










一、简介
perf c2c命令主要用于检测系统中的缓存行竞争使用,能够用于:
- 发现伪共享的cache line
- 发现谁在读写上述cache line,记忆访问发生处的cache line的内部偏移
- 读写上述cache line进程的pid,tid,指令地址,函数名,二进制文件
- 对应进程的源代码文件,代码行号
- 热点cache line上的load操作的平均时延
- 这些cache line来自哪些numa节点,哪些cpu参与了读写
二、使用方式
perf c2c命令支持与perf record相同的选项,以及c2c的一些子命令选项,记录的数据保存在当前目录的perf.data文件中,用于后续的分析。
最简单的使用示例:
perf c2c record -a sleep 5
可以使用任何命令来替换上面的sleep命令。这个示例用于抽样CPU中缓存行的信息。此命令执行完成后在当前目录下生成perf.data文件由于后续的分析。
使用如下命令打开perf.data文件进行分析:
perf c2c report --stdio
这会在终端打开perf.data文件并显示相关信息。
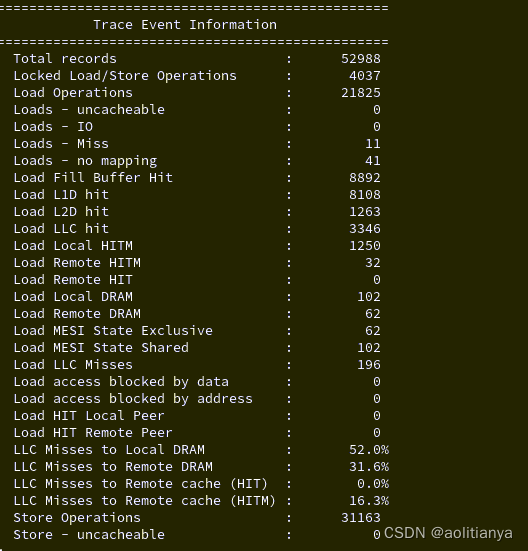
这里需要重点关注的是LLC Misses to Remote cache(HITM)的值,这个值表示由于cache line的修改造成了远端的cache无法命中的情况占所有cache miss的百分比,此值是由Load Remote HITM/Load LLC Misses得到的。这个值越大,表示伪共享的问题越严重。
其他一些使用方法:
使用-F参数设置采样频率(太高的采样频率会带来过高的负载,影响系统的使用,避免在实际生产环境中使用过高的采样频率)
perf c2c record -F 60000 -a sleep 5
使用--all-user只采集用户态样本
perf c2c record --all-user -a sleep 5
使用--all-kernel只采集内核态样本
perf c2c record --all-kernel -a sleep 5
只采集load延迟大于50的样本
perf c2c record --ldlat 60 -a sleep 5
以tui的方式显示输出
perf c2c report -NN -c pid,iaddr
找到cache line的调用栈信息,一般不会直接使用上述命令,只有当找到问题需要确定位置的时候采用使用下面的调用图
perf c2c record --call-graph dwarf,8192 -F 6000 -a --all-user sleep 3
perf c2c report -NN -g --call-graph -c pid,iaddr --stdio
关于perf的采样频率,需要注意的是,默认最大的采样频率是24000Hz,在/proc/sys/kernel/perf_event_max_sample_rate中进行了定义,如果设置的采样频率高于24000Hz,则在执行perf c2c record命令的时候会产生warning提示频率过高。

如果当前设置的频率没有造成perf的interrupt过长,那么系统将会采用通过-F指定的频率进行采样。如果当前设置的频率造成了perf的interrupt过长,那么系统将会降低采样频率,并在dmesg中记录相关提示信息。
三、perf c2c输出解析
运行perf c2c report --stdio命令显示的输出会将数据排序到几个表格中进行统计
3.1 Trace Event Information
跟踪事件信息表提供了perf c2c record命令收集到的所有负载和存储样本的概述信息
Total records:采样期间中CPU的load和store操作的次数
Load Operations:采样期间CPU的load次数
Load Fill Buffer Hit:load操作没有命中L1 Cache,但是命中了L1 cache的fill buffer的次数
Load L1D hit:load操作命中了L1 Dcache的次数
Load L2D hit:load操作命中了L2 Dcache的次数
Load LLC hit:load操作命中了LLC cache的次数
Load Local HITM:load操作命中了本地NUMA节点修改过的cache的次数
Load Remote HITM:load操作命中了远端NUMA节点修改过的cache的次数
Load Remot HIT:load操作命中了远端NUMA节点中未修改过的cache的次数
Load Local DRAM:load操作命中本地NUMA节点内存的次数,这就是cache miss
Load Remote DRAM:load操作命中了远端NUMA节点内存的次数
Load MESI State Exclusive:load操作命中MESI状态中,处于Exclusive状态的cache的次数
Load MESI State Shared:load操作命中MESI状态中,处于Shared状态的cache的次数
Load LLC Misses:load操作产生的本地LLC cache miss的次数,是Load Remote DRAM,Load Local DRAM,Load Remote HITM,Load Remote HIT之和
LLC Misses to Local DRAM:load操作产生的LLC Cache Miss中,从本地NUMA节点的内存拿到数据占所有LLC Cache Miss的百分比,是Load Local DRAM/Load LLC Misses
LLC Misses to Remote DRAM:load操作产生的LLC Cache Miss中,从远端NUMA节点的内存拿到数据占所有LLC Cache Miss的百分比,是Load Remote DRAM/Load LLC Misses
LLC Misses to Remote cache(HIT):load操作产生的LLC Cache Miss中,从远端NUMA节点的Cache中命中的百分比,是Load Remote HIT/Load LLC Misses
LLC Misses to Remote cache(HITM):load操作产生的LLC Cache Miss中,从远端NUMA节点获取的被修改cache占所有Load LLC Misses的百分比,是Load Remote HITM/Load LLC Misses
Store Operations: 采样期间store操作的数目
3.2 Global Shared Cache Line Event Information
全局共享缓存行事件信息提供了共享cache line的统计信息
Total Shared Cache Lines:采样期间共享cache line的数量,会在后面Shared Data Cache Line Table和Shared Cache Line DisPareto表中的index体现
Load HITs on shared lines:在共享cache line上hits的次数
3.3 c2c details
c2c详情表提供了有关记录事件的信息以及perf c2c report数据在视觉化中组织的方式
Cachelines sort on:在Shared Data Cache Line Table中的cache line的排序方式
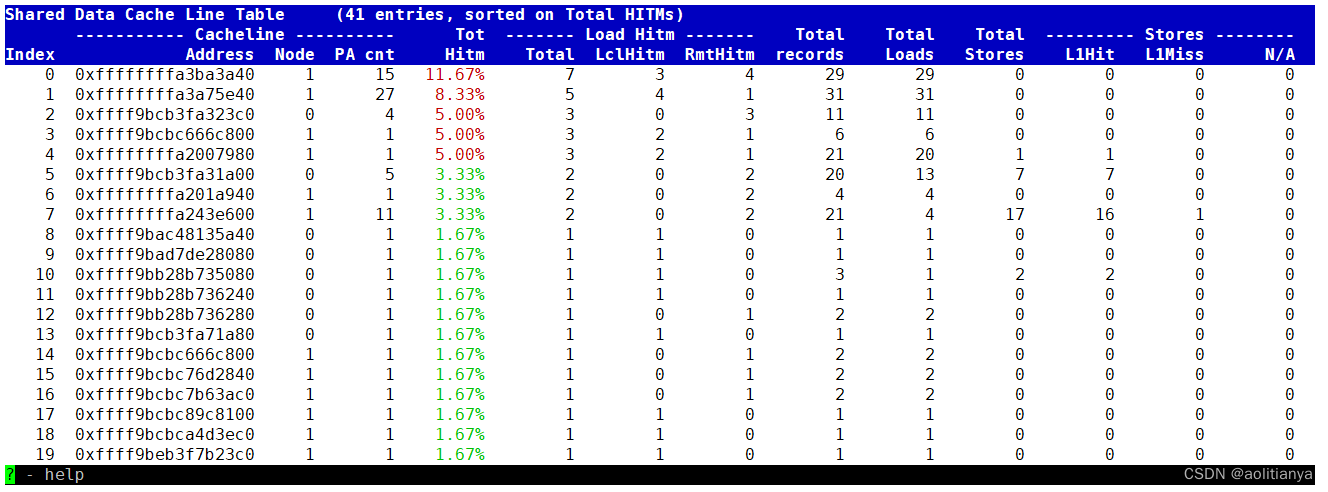
3.4 Shared Data Cache Line Table
共享数据缓存行表为监测到伪共享的热测试cache line提供了一行摘要,并默认按照每个cache line监测到的Hitm量降序排列
这个表中要关注Load Hitm中Remote LLC Hitm比较高的列,就是跨node的hitm
3.5 Shared Cache Line Distribution Pareto
共享缓存行分发Pareto:这个表提供了每个缓存行遇到竞争的各种信息:
cache line在NUM列中编号,从0开始
每个cache line的虚拟地址都包含在Data address Offset列中,随后是偏移到发生不同访问权限的cache line中
Pid列包含了进程的pid
Code Address包含了指令指针代码地址
cycles下的列显示平均负载延迟
cpu cnt列显示来自多少个不同CPU的样本
Symbol显示函数名称或者符号
Shared Object列显示来自的ELF镜像的名称(当样本来自内核的时候使用kernel.kallsyms
Source:Line 显示源文件和行号
Node显示来自哪个CPU
四、一些注意事项
perf c2c采集时间不宜过长,运行3-10s即可,运行过久,观测到的可能就不是并发的伪共享,而是时间错开的cache line访问
将-ldlat设置为一个稍大的值,例如50,perf能够更好的筛选样本
查看pareto表的时候,只需要关注最热的两三个cache line即可


















 2207
2207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











