









 本文深入探讨了深度学习中为解决过拟合问题的标签正则化技术,包括标签平滑、知识蒸馏和知识精炼等方法。标签平滑通过引入软标签降低模型对one-hot编码的过度依赖,而知识蒸馏则通过教师网络传递软标签以提高学生网络的泛化能力。知识精炼则进一步考虑了类之间的关系,动态学习类别信息。此外,文章还提及了DisturbLabel和DropMax等正则化策略,旨在通过扰动标签或随机忽略非目标分类来增强模型的泛化性能。
本文深入探讨了深度学习中为解决过拟合问题的标签正则化技术,包括标签平滑、知识蒸馏和知识精炼等方法。标签平滑通过引入软标签降低模型对one-hot编码的过度依赖,而知识蒸馏则通过教师网络传递软标签以提高学生网络的泛化能力。知识精炼则进一步考虑了类之间的关系,动态学习类别信息。此外,文章还提及了DisturbLabel和DropMax等正则化策略,旨在通过扰动标签或随机忽略非目标分类来增强模型的泛化性能。
0. 引言
关于正则化,大家都非常熟悉。深度神经网络由于其强大的特征提取能力,近年来在各种任务中得到了广泛而成功的应用。然而,DNN通常包含数以百万计的可训练参数,这很容易导致过拟合问题。为了解决这个问题,已经开发了许多正则化方法,包括参数正则化(例如dropout)、数据正则化(例如数据增强)和标签正则化(例如标签平滑),以避免过度拟合问题。
1. 为什么需要标签正则化技术
简单说一下传统的one-hot标签有什么缺点:
- one-hot编码标签非常难学,使网络过于自信会导致过拟合,无法保证模型的泛化能力。
- 全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难adapt。会造成模型过于相信预测的类别。
- 通常将数据标注为hard label,但事实上同一个数据包含不同类别的相关信息,直接标注为hard label会导致大量信息的损失,简单分类中监督信号不足(信息熵比较少)。
2. 标签正则化技术的发展
2.1 标签平滑
Rethinking the Inception Architecture for Computer Vision
Label Smoothing的想法是让目标不再是one-hot标签,而是变为如下形式:
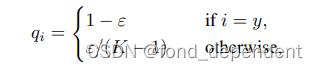
其中ε为一个较小的常数,这使得softmax损失中的概率优目标不再为1和0,同时z值的最优解也不再是正无穷大,而是一个具体的数值。这在一定程度上避免了过拟合,也缓解了错误标签带来的影响。
soft label在一定程度上是提供了噪声。
Feature Normalized Knowledge Distillation for Image Classification
上述做法的soft label在一定程度上是提供了均匀噪声,他们没有考虑类之间的关系。例如,视觉外观与“猫”相似的“狗”图像的标签分数应高于视觉外观不同的“飞机”图像的标签分数。这个工作它考虑到大多数图像在每个类别中表现出不同程度的视觉相似性,而不是上篇文章假设的均匀多样性,我们提出了一种各向异性噪声,它引入了另一种非均匀分布来更好地估计软标签分布,如下式所示:
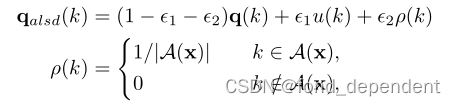
其中A(x)表示包含更“接近”基本事实类的集合。A(x)由数据集提供的类别名称决定。例如,CUB-200-2011包含5个不同种类的“啄木鸟”,那么每个“啄木鸟”子类的概率将比其他真实类多1/5。由于引入了关于类别的元信息,我们可以得到更好的估计,并且将导致更高的模型精度。
2.2 知识蒸馏
Distilling the knowledge in a neural network
知识蒸馏可以看做教师网络通过提供soft label的方式将知识传递到学生网络中,可以被视为一种更高级的label smoothing。knowledge distillation相比于label smoothing,最主要的差别在于,知识蒸馏的soft label是通过网络推理得到的,而label smoothing的soft label是人为设置的。
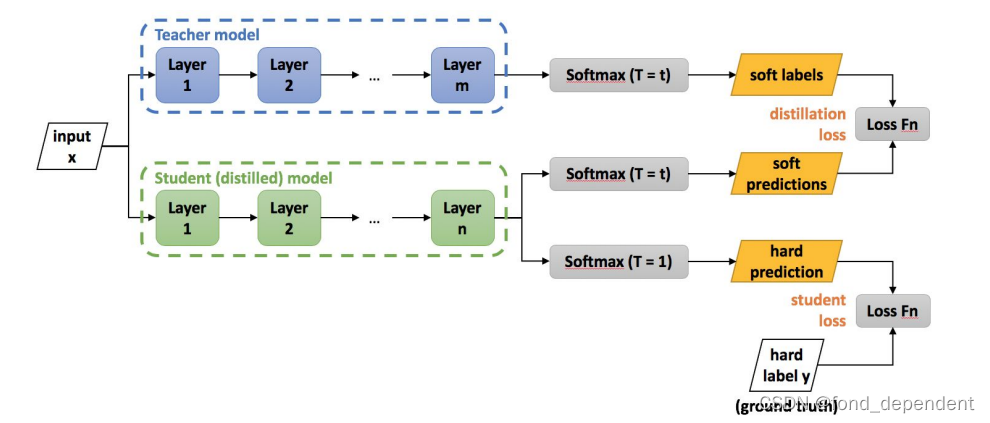
过训练后的原模型,其softmax分布包含有一定的知识:真实标签只能告诉我们,某个图像样本是一辆宝马,不是一辆垃圾车,也不是一颗萝卜;而经过训练的softmax可能会告诉我们,它最可能是一辆宝马,不大可能是一辆垃圾车,但绝不可能是一颗萝卜。知识蒸馏得到的soft label相当于对数据集的有效信息进行了统计,保留了类间的关联信息,剔除部分无效的冗余信息。 相比于label smoothing是一种更加可靠的方式。
优化目标定义如下所示:
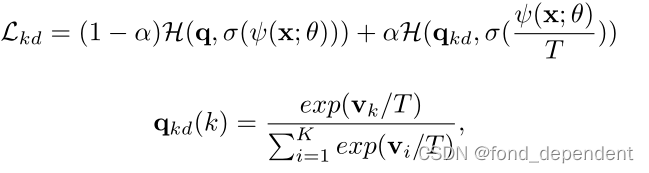
Revisiting Knowledge Distillation via Label Smoothing Regularization
这篇文章的作者认为,训练一个大的教师模型是繁琐且成本高的,尤其是再算资源有限的情况下。所以作者想要提出一个无教师模型(Tf-KD),框架具体有两个实现:
第一种Tf-KD方法是自训练知识提取,称为Tf-KDself。如果没有更强大的教师模式,我们建议“自我培训”。我们首先以正常的方式训练学生模型,以获得预先训练的模型,然后使用该模型提供软标签来训练自己,然后,我们试图通过最小化Logit在模型和他预训练版本之间的KL差异。损失函数如下:
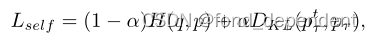
第二种Tf-KD方法Tf KD是手动设计一个100%准确的教师。传统的标签平滑是一种均匀噪声,这里我们希望噪声仍然可以保持百分百的准确性,那么保证参数
α
>
0.9
\alpha>0.9
α>0.9即可。
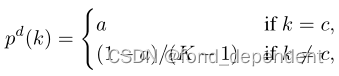
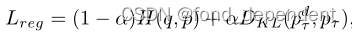
Improving Knowledge Distillation via Category Structure
这个工作,作者认为知识蒸馏传递的信息缺少结构化信息,他的设想是提出了类别结构来传递类别级结构关系,实现知识提取。它模拟了两种结构关系,包括类别内结构和类别间结构,这是样本之间关系的内在性质。类别内结构惩罚来自同一类别的样本中的结构化关系,类别间结构关注类别级别上的跨类别关系。将类别结构从教师转移到学生,可以补充类别层次的结构化关系,从而培养更好的学生。
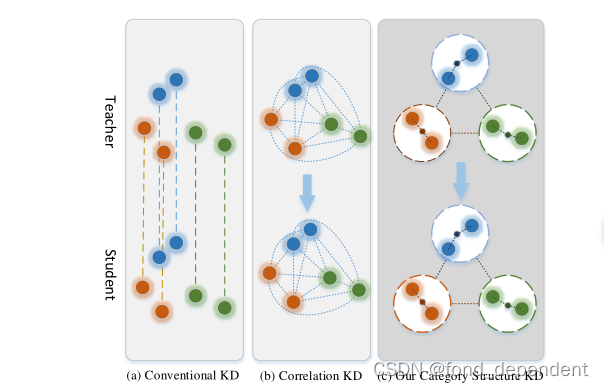
损失函数相当于增加了两项,一个是类别内结构信息的监督,另外一个是不同类别之间结构信息的监督。
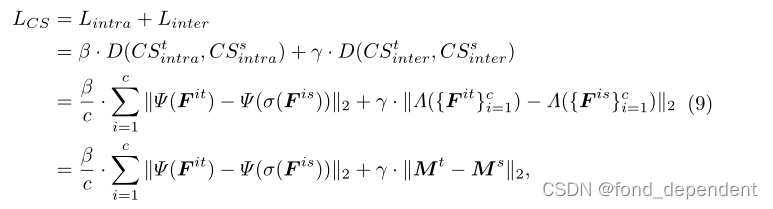
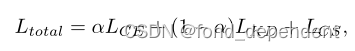
其中无论是类别内还是不同类别都是首先求一个类别的置心点
C
C
C。
类别内结构关系可以表示如下,它保留了每个样本与其分类中心之间的相对距离的结构化信息:
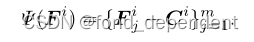
进一步定义了基于相似性的类间结构的关系函数,它反映了任意两个类别之间的结构化关系。高度相关的类别具有较高的相似性得分,而不相关的类别具有较低的相似性得分:
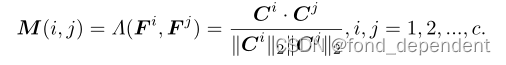
2.3 知识精炼
Knowledge Refinery: Learning from Decoupled Label
作者首先分析了现有工作的缺点,标签平滑通过将10%的权重从基本真相类均匀地重新分配到错误类,同时忽略类级关系的知识,从而降低了置信度得分。例如,视觉外观与“猫”相似的“狗”图像的标签分数应高于视觉外观不同的“飞机”图像的标签分数。为了使标签更具信息性,基于标签软化的方法试图提取类之间的视觉关系,将这些知识应用到训练阶段。这种类型的典型方法是知识提炼方法,它们从繁琐的教师模型生成软标签,以训练学生模型。
作者认为一种理想的标签正则需要满足下面三种条件:1)关系表达式。标签的表示考虑了类之间的关系。2)在线培训。在不预先培训额外教师的情况下,动态学习关系。3)灵活性。不需要调整标签表示的柔和度。
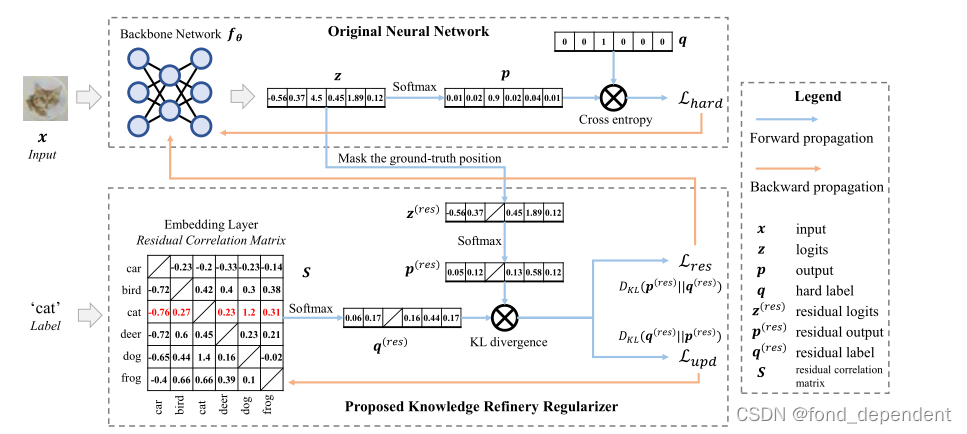
为此作者提出知识提炼(KR),通过动态学习特定于类的信息和类级关系的知识。我们将“理想”标签分解为两个部分,目标标签(即硬标签或平滑标签)和非目标标签(即剩余标签),损失函数如下:
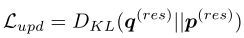
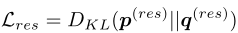
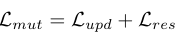
作者将剩余相关矩阵初始化为零填充矩阵。这意味着类别的初始剩余标签是均匀分布的。.通过这种相互学习策略,我们允许主干网络和残差相关矩阵同时相互学习。
2.4 其它工作
Regularizing cnn on the loss layer
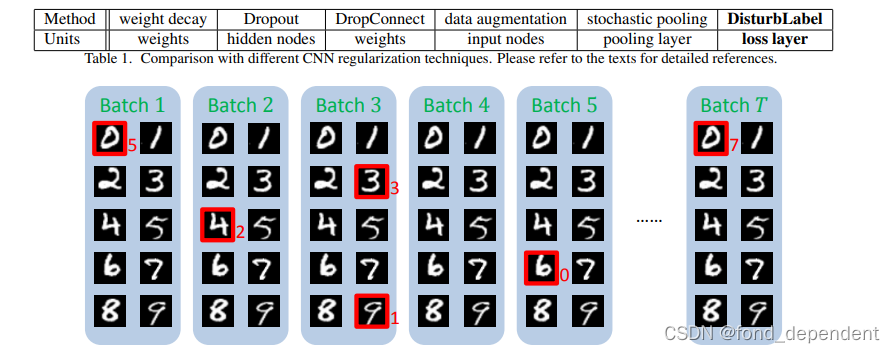
为防止过拟合,本文针对 CNN模型正则化提出了一个简单的算法:DisturbLabel , 就是在每次迭代过程中,我们随机选择一些样本,使用错误的标记值进行训练。我们发现这个简单的方法可以很好的防止CNN模型过拟合。并且可以和 Dropout 一起使用得到更好的效果。这个想法真是简单有效。
DropMax: Adaptive variational softmax
提出了一种新的随机softmax分类器,DropMax。DropMax在每次迭代中随机抛弃一些非目标分类,从而起到正则化作用。某种意义上,这种做法有点像boosting集成学习。因为分类任务中softmax层几乎是标配,所以DropMax的适用范围很广,可以应用于各种网络架构。
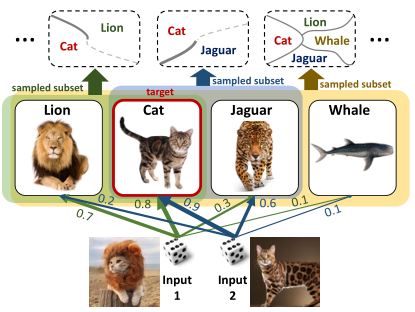
本文的核心公式如下所示,每次进行分类时作者都通过一个伯克利分布来决定哪些类来参与损失函数优化,这允许学习分类器来解决给定多类分类问题的不同子问题,使其能够关注目标类相对于采样类的区别性属性。最后,当训练结束时,我们可以获得具有不同决策边界的指数多分类器的集合:
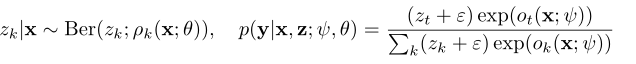
提出的自适应类选取也可以看作是一种随机注意机制,它选择每个实例应该注意的类的子集,以便很好地将其与任何错误类区分开来。
整篇读下来有点像label上的dropout (随机丢弃一些类,集成思想)+ label注意力(给困难标签更多关注)
Dimensionality-Driven Learning with Noisy Labels
这篇工作题目为有噪声标签的驱动学习,认为标签存在噪声,本质上也是减少模型置信度的做法,作者将神经网络的学习目标设为ground truth + 模型预测,权重
α
\alpha
α随着训练时间增加逐渐减小。
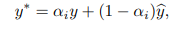
3. 一点感想
我们首先讨论如何更好的即插即用label smoothing,既然即插即用,那我们就不要涉及训练一个teachet模型。
其一,我们可以直接使用一种简单灵活的知识精炼算法,但是复现效果还是未知。
其二,纵观上述论文,我们可以将soft label解耦为下面几部分的加权求和,独热标签、全局类别关系标签、特定样本类别关系标签、规则类别关系标签。
其中全局标签反映一种全局的类别相似度关系,例如B和8的相似度要比B和Q高。这个全局相似度我们可以首先训练一个预训练模型,然后得到所有类别的embedding,求得每个类别的一个质心特征,就可以求得一个相似度矩阵。当然类别特征我们也可以设为一个随模型学习的embedding,训练完后我们求这些embedding之间相似度就可以。
特定样本标签反应对应于特定样本下不同类之间的相似度是不同的。所以我们特地样本类别关系标签可以为模型对于该样本的预测或者一个预训练模型对于该样本的预测。
规则类别就是根据我们的一些先验知识自己设计的,不过一般全局标签都可以学习的差不多。
进一步拓展:区分样本使用。所有样本都要soft-label嘛,不是这样的。他会让模型欠缺自信,对于模型一些非常自信,类别特征十分明显的我们不要使用soft-label让识别器失去自信。所以如何区分出这些样本呢,我简单的设想是看他的最大非目标类的概率和目标类的概率差值,如果差值比较大,我们认为他可以不执行标签正则化;反之如果差值比较小,我们认为他要执行soft-label,因为这种情况要么是极其困难样本,模型强行学下去会导致模型过拟合;要么是一种标注错误。

















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









