










1.下面讲解一个基于图自编码器实现简单的推荐任务的例子。推荐系统要建立的是用户与商品之间的关系,这里我们以简化后的用户对 商品的评分为例进行介绍,如图下图假设用户与商品之间的交互行为只 存在评分,分值从1分到5分。如果用户u对商品v进行评分,评分为r, 就是说用户u与商品v之间存在一条边,边的类型为r,其中r∈R。基于 这种交互关系对用户进行商品推荐实际上就是要预测哪些商品与用户之 间可能存在边,这样的问题称为边预测问题。对于这种边预测问题,我 们将其看作矩阵补全问题,用户与商品之间的交互行为构成了一个二部 图,可以通过用户与商品的邻接矩阵表示为A,矩阵中的值就是评分, 推荐就是要对矩阵没有评分的位置进行预测。
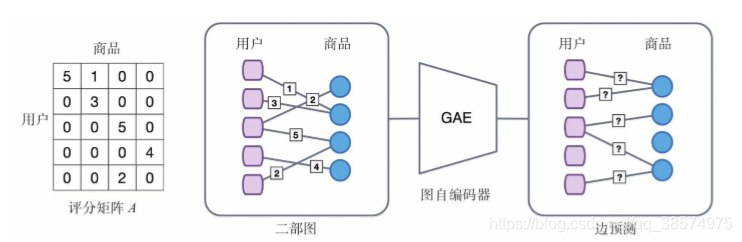
上图图自编码器的推荐系统的架构图。如图所示,首先将 用户–商品矩阵转化成用户–商品二部图,然后使用图自编码器对二部图 进行建模,这里使用GCN作为编码器,然后通过解码器对邻接矩阵中的 边信息进行重构,由此完成边预测的任务。对于邻接矩阵A按照不同的 评分r进行分解,可以得到每个评分r对应的一个邻接矩阵Ar,它在评分为V的位置上值为1,否则为0。请注意,在这里将不同的评分当作不同 的关系进行处理,而不是当作边上的属性进行预测。接下来,使用RGCN双重聚合的思路对节点的表示进行学习:先对同一关系的邻居进行 聚合,再对所有的邻居进行聚合。
2.下面是基于 MovieLens-100K 数据的GraphAutoEncoder代码
dataset
import os
import urllib.request
from zipfile import ZipFile
from io import StringIO
import numpy as np
import pandas as pd
import scipy.sparse as sp
def globally_normalize_bipartite_adjacency(adjacencies, symmetric=True):
""" Globally Normalizes set of bipartite adjacency matrices """
print('{} normalizing bipartite adj'.format(
['Asymmetrically', 'Symmetrically'][symmetric]))
adj_tot = np.sum([adj for adj in adjacencies])
degree_u = np.asarray(adj_tot.sum(1)).flatten()
degree_v = np.asarray(adj_tot.sum(0)).flatten()
# set zeros to inf to avoid dividing by zero
degree_u[degree_u == 0.] = np.inf
degree_v[degree_v == 0.] = np.inf
degree_u_inv_sqrt = 1. / np.sqrt(degree_u)
degree_v_inv_sqrt = 1. / np.sqrt(degree_v)
degree_u_inv_sqrt_mat = sp.diags([degree_u_inv_sqrt], [0])
degree_v_inv_sqrt_mat = sp.diags([degree_v_inv_sqrt], [0])
degree_u_inv = degree_u_inv_sqrt_mat.dot(degree_u_inv_sqrt_mat)
if symmetric:
adj_norm = [degree_u_inv_sqrt_mat.dot(adj).dot(
degree_v_inv_sqrt_mat) for adj in adjacencies]
else:
adj_norm = [degree_u_inv.dot(adj) for adj in adjacencies]
return adj_norm
def get_adjacency(edge_df, num_user, num_movie, symmetric_normalization):
user2movie_adjacencies = []
movie2user_adjacencies = []
train_edge_df = edge_df.loc[edge_df['usage'] == 'train']
for i in range(5):
edge_index = train_edge_df.loc[train_edge_df.ratings == i, [
'user_node_id', 'movie_node_id']].to_numpy()
support = sp.csr_matrix((np.ones(len(edge_index)), (edge_index[:, 0], edge_index[:, 1])),
shape=(num_user, num_movie), dtype=np.float32)
user2movie_adjacencies.append(support)
movie2user_adjacencies.append(support.T)
user2movie_adjacencies = globally_normalize_bipartite_adjacency(user2movie_adjacencies,
symmetric=symmetric_normalization)
movie2user_adjacencies = globally_normalize_bipartite_adjacency(movie2user_adjacencies,
symmetric=symmetric_normalization)
return user2movie_adjacencies, movie2user_adjacencies
def get_node_identity_feature(num_user, num_movie):
"""one-hot encoding for nodes"""
identity_feature = np.identity(num_user + num_movie, dtype=np.float32)
user_identity_feature, movie_indentity_feature = identity_feature[
:num_user], identity_feature[num_user:]
return user_identity_feature, movie_indentity_feature
def get_user_side_feature(node_user: pd.DataFrame):
"""用户节点属性特征,包括年龄,性别,职业"""
age = node_user['age'].to_numpy().astype('float32')
age /= age.max()
age = age.reshape((-1, 1))
gender_arr, gender_index = pd.factorize(node_user['gender'])
gender_arr = np.reshape(gender_arr, (-1, 1))
occupation_arr = pd.get_dummies(node_user['occupation']).to_numpy()
user_feature = np.concatenate([age, gender_arr, occupation_arr], axis=1)
return user_feature
def get_movie_side_feature(node_movie: pd.DataFrame):
"""电影节点属性特征,主要是电影类型"""
movie_genre_cols = ['Action', 'Adventure', 'Animation',
'Childrens', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy',
'Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi',
'Thriller', 'War', 'Western']
movie_genre_arr = node_movie.loc[:,
movie_genre_cols].to_numpy().astype('float32')
return movie_genre_arr
def convert_to_homogeneous(user_feature: np.ndarray, movie_feature: np.ndarray):
"""通过补零将用户和电影的属性特征对齐到同一维度"""
num_user, user_feature_dim = user_feature.shape
num_movie, movie_feature_dim = movie_feature.shape
user_feature = np.concatenate(
[user_feature, np.zeros((num_user, movie_feature_dim))], axis=1)
movie_feature = np.concatenate(
[movie_feature, np.zeros((num_movie, user_feature_dim))], axis=1)
return user_feature, movie_feature
class MovielensDataset(object):
url = "http://files.grouplens.org/datasets/movielens/ml-100k.zip"
def __init__(self, data_root="data"):
self.data_root = data_root
self.maybe_download()
@staticmethod
def build_graph(edge_df: pd.DataFrame, user_df: pd.DataFrame,
movie_df: pd.DataFrame, symmetric_normalization=False):
node_user = edge_df[['user_node']
].drop_duplicates().sort_values('user_node')
node_movie = edge_df[['movie_node']
].drop_duplicates().sort_values('movie_node')
node_user.loc[:, 'user_node_id'] = range(len(node_user))
node_movie.loc[:, 'movie_node_id'] = range(len(node_movie))
edge_df = edge_df.merge(node_user, on='user_node', how='left')\
.merge(node_movie, on='movie_node', how='left')
node_user = node_user.merge(user_df, on='user_node', how='left')
node_movie = node_movie.merge(movie_df, on='movie_node', how='left')
num_user = len(node_user)
num_movie = len(node_movie)
# adjacency
user2movie_adjacencies, movie2user_adjacencies = get_adjacency(edge_df, num_user, num_movie,
symmetric_normalization)
# node property feature
user_side_feature = get_user_side_feature(node_user)
movie_side_feature = get_movie_side_feature(node_movie)
user_side_feature, movie_side_feature = convert_to_homogeneous(user_side_feature,
movie_side_feature)
# one-hot encoding for nodes
user_identity_feature, movie_indentity_feature = get_node_identity_feature(
num_user, num_movie)
# user_indices, movie_indices, labels, train_mask
user_indices, movie_indices, labels = edge_df[[
'user_node_id', 'movie_node_id', 'ratings']].to_numpy().T
train_mask = (edge_df['usage'] == 'train').to_numpy()
return user2movie_adjacencies, movie2user_adjacencies, \
user_side_feature, movie_side_feature, \
user_identity_feature, movie_indentity_feature, \
user_indices, movie_indices, labels, train_mask
def read_data(self):
data_dir = os.path.join(self.data_root, "ml-100k")
# edge data
edge_train = pd.read_csv(os.path.join(data_dir, 'u1.base'), sep='\t',
header=None, names=['user_node', 'movie_node', 'ratings', 'timestamp'])
edge_train.loc[:, 'usage'] = 'train'
edge_test = pd.read_csv(os.path.join(data_dir, 'u1.test'), sep='\t',
header=None, names=['user_node', 'movie_node', 'ratings', 'timestamp'])
edge_test.loc[:, 'usage'] = 'test'
edge_df = pd.concat((edge_train, edge_test),
axis=0).drop(columns='timestamp')
edge_df.loc[:, 'ratings'] -= 1
# item feature
sep = r'|'
movie_file = os.path.join(data_dir, 'u.item')
movie_headers = ['movie_node', 'movie_title', 'release_date', 'video_release_date',
'IMDb_URL', 'unknown', 'Action', 'Adventure', 'Animation',
'Childrens', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy',
'Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi',
'Thriller', 'War', 'Western']
movie_df = pd.read_csv(movie_file, sep=sep, header=None,
names=movie_headers, encoding='latin1')
# user feature
users_file = os.path.join(data_dir, 'u.user')
users_headers = ['user_node', 'age',
'gender', 'occupation', 'zip_code']
users_df = pd.read_csv(users_file, sep=sep, header=None,
names=users_headers, encoding='latin1')
return edge_df, users_df, movie_df
def maybe_download(self):
save_path = os.path.join(self.data_root)
if not os.path.exists(save_path):
self.download_data(self.url, save_path)
if not os.path.exists(os.path.join(self.data_root, "ml-100k")):
zipfilename = os.path.join(self.data_root, "ml-100k.zip")
with ZipFile(zipfilename, "r") as zipobj:
zipobj.extractall(os.path.join(self.data_root))
print("Extracting data from {}".format(zipfilename))
@staticmethod
def download_data(url, save_path):
"""数据下载工具,当原始数据不存在时将会进行下载"""
print("Downloading data from {}".format(url))
if not os.path.exists(save_path):
os.makedirs(save_path)
request = urllib.request.urlopen(url)
filename = os.path.basename(url)
with open(os.path.join(save_path, filename), 'wb') as f:
f.write(request.read())
return True
if __name__ == "__main__":
data = MovielensDataset()
user2movie_adjacencies, movie2user_adjacencies, \
user_side_feature, movie_side_feature, \
user_identity_feature, movie_indentity_feature, \
user_indices, movie_indices, labels, train_mask = data.build_graph(
*data.read_data())
autoencoder
import torch
import torch.nn as nn
import torch.nn.functional as F
import scipy.sparse as sp
import numpy as np
import torch.nn.init as init
class StackGCNEncoder(nn.Module):
def __init__(self, input_dim, output_dim, num_support,
use_bias=False, activation=F.relu):
"""对得到的每类评分使用级联的方式进行聚合
Args:
----
input_dim (int): 输入的特征维度
output_dim (int): 输出的特征维度,需要output_dim % num_support = 0
num_support (int): 评分的类别数,比如1~5分,值为5
use_bias (bool, optional): 是否使用偏置. Defaults to False.
activation (optional): 激活函数. Defaults to F.relu.
"""
super(StackGCNEncoder, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.num_support = num_support
self.use_bias = use_bias
self.activation = activation
assert output_dim % num_support == 0
self.weight = nn.Parameter(torch.Tensor(num_support,
input_dim, output_dim // num_support))
if self.use_bias:
self.bias = nn.Parameter(torch.Tensor(output_dim, ))
self.bias_item = nn.Parameter(torch.Tensor(output_dim, ))
self.reset_parameters()
def reset_parameters(self):
init.kaiming_uniform_(self.weight)
if self.use_bias:
init.zeros_(self.bias)
init.zeros_(self.bias_item)
def forward(self, user_supports, item_supports, user_inputs, item_inputs):
"""StackGCNEncoder计算逻辑
Args:
user_supports (list of torch.sparse.FloatTensor):
归一化后每个评分等级对应的用户与商品邻接矩阵
item_supports (list of torch.sparse.FloatTensor):
归一化后每个评分等级对应的商品与用户邻接矩阵
user_inputs (torch.Tensor): 用户特征的输入
item_inputs (torch.Tensor): 商品特征的输入
Returns:
[torch.Tensor]: 用户的隐层特征
[torch.Tensor]: 商品的隐层特征
"""
assert len(user_supports) == len(item_supports) == self.num_support
user_hidden = []
item_hidden = []
for i in range(self.num_support):
tmp_u = torch.matmul(user_inputs, self.weight[i])
tmp_v = torch.matmul(item_inputs, self.weight[i])
tmp_user_hidden = torch.sparse.mm(user_supports[i], tmp_v)
tmp_item_hidden = torch.sparse.mm(item_supports[i], tmp_u)
user_hidden.append(tmp_user_hidden)
item_hidden.append(tmp_item_hidden)
user_hidden = torch.cat(user_hidden, dim=1)
item_hidden = torch.cat(item_hidden, dim=1)
user_outputs = self.activation(user_hidden)
item_outputs = self.activation(item_hidden)
if self.use_bias:
user_outputs += self.bias
item_outputs += self.bias_item
return user_outputs, item_outputs
class SumGCNEncoder(nn.Module):
def __init__(self, input_dim, output_dim, num_support,
use_bias=False, activation=F.relu):
"""对得到的每类评分使用求和的方式进行聚合
Args:
input_dim (int): 输入的特征维度
output_dim (int): 输出的特征维度,需要output_dim % num_support = 0
num_support (int): 评分的类别数,比如1~5分,值为5
use_bias (bool, optional): 是否使用偏置. Defaults to False.
activation (optional): 激活函数. Defaults to F.relu.
"""
super(SumGCNEncoder, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.num_support = num_support
self.use_bias = use_bias
self.activation = activation
self.weight = nn.Parameter(torch.Tensor(
input_dim, output_dim * num_support))
if self.use_bias:
self.bias = nn.Parameter(torch.Tensor(output_dim, ))
self.reset_parameters()
self.weight = self.weight.view(input_dim, output_dim, 5)
def reset_parameters(self):
init.kaiming_uniform_(self.weight)
if self.use_bias:
init.zeros_(self.bias)
def forward(self, user_supports, item_supports, user_inputs, item_inputs):
"""SumGCNEncoder计算逻辑
Args:
user_supports (list of torch.sparse.FloatTensor):
归一化后每个评分等级对应的用户与商品邻接矩阵
item_supports (list of torch.sparse.FloatTensor):
归一化后每个评分等级对应的商品与用户邻接矩阵
user_inputs (torch.Tensor): 用户特征的输入
item_inputs (torch.Tensor): 商品特征的输入
Returns:
[torch.Tensor]: 用户的隐层特征
[torch.Tensor]: 商品的隐层特征
"""
assert len(user_supports) == len(item_supports) == self.num_support
user_hidden = 0
item_hidden = 0
w = 0
for i in range(self.num_support):
w += self.weight[..., i]
tmp_u = torch.matmul(user_inputs, w)
tmp_v = torch.matmul(item_inputs, w)
tmp_user_hidden = torch.sparse.mm(user_supports[i], tmp_v)
tmp_item_hidden = torch.sparse.mm(item_supports[i], tmp_u)
user_hidden += tmp_user_hidden
item_hidden += tmp_item_hidden
user_outputs = self.activation(user_hidden)
item_outputs = self.activation(item_hidden)
if self.use_bias:
user_outputs += self.bias
item_outputs += self.bias_item
return user_outputs, item_outputs
class FullyConnected(nn.Module):
def __init__(self, input_dim, output_dim, dropout=0.,
use_bias=False, activation=F.relu,
share_weights=False):
"""非线性变换层
Args:
----
input_dim (int): 输入的特征维度
output_dim (int): 输出的特征维度,需要output_dim % num_support = 0
use_bias (bool, optional): 是否使用偏置. Defaults to False.
activation (optional): 激活函数. Defaults to F.relu.
share_weights (bool, optional): 用户和商品是否共享变换权值. Defaults to False.
"""
super(FullyConnected, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.use_bias = use_bias
self.activation = activation
self.share_weights = share_weights
self.linear_user = nn.Linear(input_dim, output_dim, bias=use_bias)
if self.share_weights:
self.linear_item = self.linear_user
else:
self.linear_item = nn.Linear(input_dim, output_dim, bias=use_bias)
self.dropout = nn.Dropout(dropout)
def forward(self, user_inputs, item_inputs):
"""前向传播
Args:
user_inputs (torch.Tensor): 输入的用户特征
item_inputs (torch.Tensor): 输入的商品特征
Returns:
[torch.Tensor]: 输出的用户特征
[torch.Tensor]: 输出的商品特征
"""
user_inputs = self.dropout(user_inputs)
user_outputs = self.linear_user(user_inputs)
item_inputs = self.dropout(item_inputs)
item_outputs = self.linear_item(item_inputs)
if self.activation:
user_outputs = self.activation(user_outputs)
item_outputs = self.activation(item_outputs)
return user_outputs, item_outputs
class Decoder(nn.Module):
def __init__(self, input_dim, num_weights, num_classes, dropout=0., activation=F.relu):
"""解码器
Args:
----
input_dim (int): 输入的特征维度
num_weights (int): basis weight number
num_classes (int): 总共的评分级别数,eg. 5
"""
super(Decoder, self).__init__()
self.input_dim = input_dim
self.num_weights = num_weights
self.num_classes = num_classes
self.activation = activation
self.weight = nn.Parameter(torch.Tensor(num_weights, input_dim, input_dim))
self.weight_classifier = nn.Parameter(torch.Tensor(num_weights, num_classes))
self.reset_parameters()
self.dropout = nn.Dropout(dropout)
def reset_parameters(self):
init.kaiming_uniform_(self.weight)
init.kaiming_uniform_(self.weight_classifier)
def forward(self, user_inputs, item_inputs, user_indices, item_indices):
"""计算非归一化的分类输出
Args:
user_inputs (torch.Tensor): 用户的隐层特征
item_inputs (torch.Tensor): 商品的隐层特征
user_indices (torch.LongTensor):
所有交互行为中用户的id索引,与对应的item_indices构成一条边,shape=(num_edges, )
item_indices (torch.LongTensor):
所有交互行为中商品的id索引,与对应的user_indices构成一条边,shape=(num_edges, )
Returns:
[torch.Tensor]: 未归一化的分类输出,shape=(num_edges, num_classes)
"""
user_inputs = self.dropout(user_inputs)
item_inputs = self.dropout(item_inputs)
user_inputs = user_inputs[user_indices]
item_inputs = item_inputs[item_indices]
basis_outputs = []
for i in range(self.num_weights):
tmp = torch.matmul(user_inputs, self.weight[i])
out = torch.sum(tmp * item_inputs, dim=1, keepdim=True)
basis_outputs.append(out)
basis_outputs = torch.cat(basis_outputs, dim=1)
outputs = torch.matmul(basis_outputs, self.weight_classifier)
outputs = self.activation(outputs)
return outputs
mian函数 (执行此函数)
"""基于 MovieLens-100K 数据的GraphAutoEncoder"""
import numpy as np
import torch
import torch.nn as nn
import scipy.sparse as sp
import torch.optim as optim
import torch.nn.functional as F
from test.dataset import MovielensDataset
from test.GNN import StackGCNEncoder, FullyConnected, Decoder
######hyper
DEVICE = torch.device('CPU')
LEARNING_RATE = 1e-2
EPOCHS = 2000
NODE_INPUT_DIM = 2625
SIDE_FEATURE_DIM = 41
GCN_HIDDEN_DIM = 500
SIDE_HIDDEN_DIM = 10
ENCODE_HIDDEN_DIM = 75
NUM_BASIS = 2
DROPOUT_RATIO = 0.7
WEIGHT_DACAY = 0.
######hyper
SCORES = torch.tensor([[1, 2, 3, 4, 5]]).to(DEVICE)
def to_torch_sparse_tensor(x, device='cpu'):
if not sp.isspmatrix_coo(x):
x = sp.coo_matrix(x)
row, col = x.row, x.col
data = x.data
indices = torch.from_numpy(np.asarray([row, col]).astype('int64')).long()
values = torch.from_numpy(x.data.astype(np.float32))
th_sparse_tensor = torch.sparse.FloatTensor(indices, values,
x.shape).to(device)
return th_sparse_tensor
def tensor_from_numpy(x, device='cpu'):
return torch.from_numpy(x).to(device)
class GraphMatrixCompletion(nn.Module):
def __init__(self, input_dim, side_feat_dim,
gcn_hidden_dim, side_hidden_dim,
encode_hidden_dim,
num_support=5, num_classes=5, num_basis=3):
super(GraphMatrixCompletion, self).__init__()
self.encoder = StackGCNEncoder(input_dim, gcn_hidden_dim, num_support)
self.dense1 = FullyConnected(side_feat_dim, side_hidden_dim, dropout=0.,
use_bias=True)
self.dense2 = FullyConnected(gcn_hidden_dim + side_hidden_dim, encode_hidden_dim,
dropout=DROPOUT_RATIO, activation=lambda x: x)
self.decoder = Decoder(encode_hidden_dim, num_basis, num_classes,
dropout=DROPOUT_RATIO, activation=lambda x: x)
def forward(self, user_supports, item_supports,
user_inputs, item_inputs,
user_side_inputs, item_side_inputs,
user_edge_idx, item_edge_idx):
user_gcn, movie_gcn = self.encoder(user_supports, item_supports, user_inputs, item_inputs)
user_side_feat, movie_side_feat = self.dense1(user_side_inputs, item_side_inputs)
user_feat = torch.cat((user_gcn, user_side_feat), dim=1)
movie_feat = torch.cat((movie_gcn, movie_side_feat), dim=1)
user_embed, movie_embed = self.dense2(user_feat, movie_feat)
edge_logits = self.decoder(user_embed, movie_embed, user_edge_idx, item_edge_idx)
return edge_logits
data = MovielensDataset()
user2movie_adjacencies, movie2user_adjacencies, \
user_side_feature, movie_side_feature, \
user_identity_feature, movie_identity_feature, \
user_indices, movie_indices, labels, train_mask = data.build_graph(
*data.read_data())
user2movie_adjacencies = [to_torch_sparse_tensor(adj, DEVICE) for adj in user2movie_adjacencies]
movie2user_adjacencies = [to_torch_sparse_tensor(adj, DEVICE) for adj in movie2user_adjacencies]
user_side_feature = tensor_from_numpy(user_side_feature, DEVICE).float()
movie_side_feature = tensor_from_numpy(movie_side_feature, DEVICE).float()
user_identity_feature = tensor_from_numpy(user_identity_feature, DEVICE).float()
movie_identity_feature = tensor_from_numpy(movie_identity_feature, DEVICE).float()
user_indices = tensor_from_numpy(user_indices, DEVICE).long()
movie_indices = tensor_from_numpy(movie_indices, DEVICE).long()
labels = tensor_from_numpy(labels, DEVICE)
train_mask = tensor_from_numpy(train_mask, DEVICE)
model = GraphMatrixCompletion(NODE_INPUT_DIM, SIDE_FEATURE_DIM, GCN_HIDDEN_DIM,
SIDE_HIDDEN_DIM, ENCODE_HIDDEN_DIM, num_basis=NUM_BASIS).to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE, weight_decay=WEIGHT_DACAY)
model_inputs = (user2movie_adjacencies, movie2user_adjacencies,
user_identity_feature, movie_identity_feature,
user_side_feature, movie_side_feature, user_indices, movie_indices)
def train():
model.train()
for e in range(EPOCHS):
logits = model(*model_inputs)
loss = criterion(logits[train_mask], labels[train_mask])
rmse = expected_rmse(logits[train_mask], labels[train_mask])
optimizer.zero_grad()
loss.backward() # 反向传播计算参数的梯度
optimizer.step() # 使用优化方法进行梯度更新
print("Epoch {:03d}: Loss: {:.4f}, RMSE: {:.4f}".format(e, loss.item(), rmse.item()))
if (e + 1) % 100 == 0:
test(e)
model.train()
def test(e):
model.eval()
with torch.no_grad():
logits = model(*model_inputs)
test_mask = ~train_mask
loss = criterion(logits[test_mask], labels[test_mask])
rmse = expected_rmse(logits[test_mask], labels[test_mask])
print('Test On Epoch {}: loss: {:.4f}, Test rmse: {:.4f}'.format(e, loss.item(), rmse.item()))
return logits
def expected_rmse(logits, label):
true_y = label + 1 # 原来的评分为1~5,作为label时为0~4
prob = F.softmax(logits, dim=1)
pred_y = torch.sum(prob * SCORES, dim=1)
diff = torch.pow(true_y - pred_y, 2)
return torch.sqrt(diff.mean())
if __name__ == "__main__":
train()
参考:
kdd18年paper














 3279
3279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









