







爆栈?栈的大小不够用怎么办?
Linux系统栈帧大小
我们先从一段代码开始:
#include<stdio.h>
const int N = 4*1024*1024;
int func(){
int buf[N];
printf("%d\n", N);
printf("%d\n", sizeof(buf));
return 0;
}
编译执行上述代码,显而易见,报Segment Fault错误。
用如下指令查看系统栈帧的最大size:
ulimit -s
8192
好的,我们看到系统支持的最大栈帧大小为8192KB,也就是8MB。而上述代码中,我们开的数组大小达到了16MB,自然就爆栈了。
那么我们应该怎么办呢?
修改系统栈帧大小
使用如下代码将栈帧大小修改为102400KB。
ulimit -s 102400
【奇技淫巧】将栈转移到堆中
如果我们不想或者没有修改系统栈帧大小的权限,怎么办?
首先,来复习一下x86-64架构的函数栈帧:
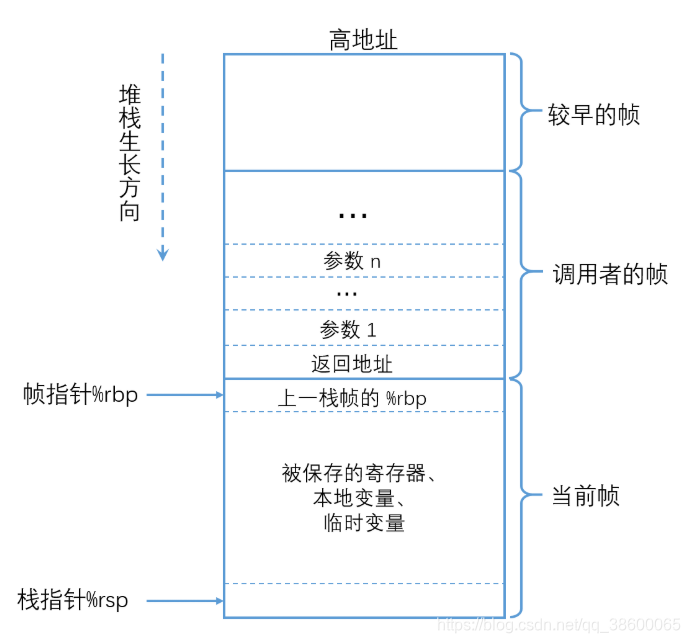
我们可以看到,rbp指针指向栈底,rsp指针指向栈顶。当发生子函数调用的时候,将父函数rbp压栈,新函数的rbp为现在的rsp。当函数返回时,将子函数rbp赋值给rsp,然后父函数rbp出栈。
即在子函数调用发生前,只需要合理地修改rsp寄存器的值,就能够改变子函数的栈帧位置。
了解这些之后,我们考虑先在堆上申请一大块的内存区域,在main函数调用子函数之前,将rsp寄存器的内容替换为我们之前申请的内存区域的地址。这里需要注意的是,栈帧是从高地址向低地址生长的,而我们申请的内存区域是从低地址开始的,所以我们需要将rsp的值设置为申请的内存区域的最后一个地址。
具体代码,由于需要操作寄存器,所以用到了内联汇编:
#include<stdio.h>
#include<stdlib.h>
const int N = 4*1024*1024;
int func(){
int buf[N];
printf("%d\n", N);
printf("%d\n", sizeof(buf));
return 0;
}
int main(){
int bytes = 32*1024*1024;
void *stack_top = malloc(bytes); //申请一块比我们所需栈帧大小更大的内存区域
void *stack_bottom = stack_top + bytes - 1;
void *rsp;
__asm__("movq %%rsp, %0":"=m"(rsp)::); //先记录下当前的rsp值
__asm__("movq %0, %%rsp"::"m"(stack_bottom):); //修改rsp值
func();
__asm__("movq %0, %%rsp"::"m"(rsp):); //恢复rsp值
return 0;
}
编译运行,完美运行!
需要注意的是,系统给栈帧设置大小的一个原因是为了不让栈帧不断生成的数据最终破坏我们的其它数据,因此不能够让栈帧无限增长,在栈帧区域的最顶端有一个保护帧,当我们访问到保护帧时,会触发Segment Fault异常。所以当我们使用上述技巧替换栈帧位置的时候,要确保栈帧的大小始终都在设置的范围内,而不会影响其它的数据。














 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









