







 本文详细介绍了如何使用OneAPI部署LLM模型(如ChatGLM3-6B),以及如何配置FastGPT和嵌入模型,包括创建接口令牌,设置环境变量,部署步骤和模型验证。同时提及了在FastGPT中创建对话应用和知识库应用的配置过程。
本文详细介绍了如何使用OneAPI部署LLM模型(如ChatGLM3-6B),以及如何配置FastGPT和嵌入模型,包括创建接口令牌,设置环境变量,部署步骤和模型验证。同时提及了在FastGPT中创建对话应用和知识库应用的配置过程。
部署OneAPI
One API是一个 API 管理和分发系统,支持 OpenAI、Azure、Anthropic Claude、Google Gemini、DeepSeek、字节豆包、ChatGLM、文心一言、讯飞星火、通义千问、360 智脑、腾讯混元等主流模型,统一 API 适配,可用于 key 管理与二次分发。单可执行文件,提供 Docker 镜像,一键部署,开箱即用。
拉取镜像
docker pull justsong/one-api
创建挂载目录
mkdir -p /usr/local/docker/oneapi
启动容器
docker run --name one-api -d --restart always -p 3001:3000 -e TZ=Asia/Shanghai -v /usr/local/docker/oneapi:/data justsong/one-api
访问IP:3001
注意:
用户默认
root密码默认123456,首次登录后务必修改密码
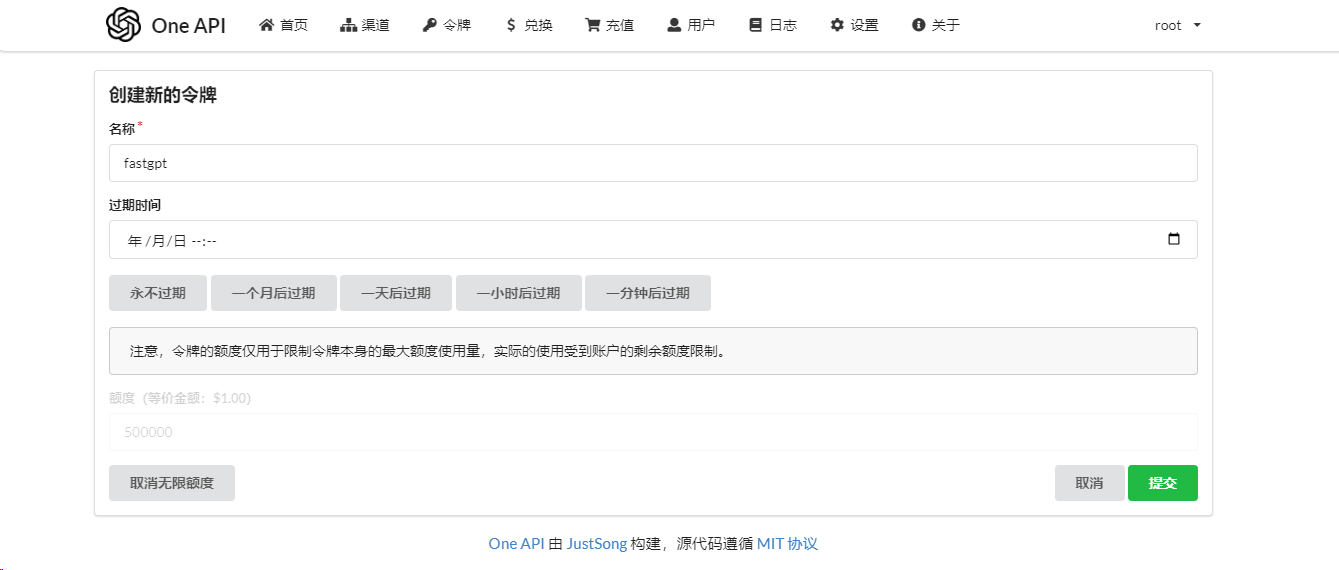
创建接口令牌API Key备用
根据需要配置,这里点击“永不过期”+“设为无限额度”
特别说明:近日在内网环境,离线部署oneapi,启动oneapi时遇到如下异常:
failed to get gpt-3.5-turbo token encoder: Get "https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken": read tcp xxxxx -> xxxxx: read: connection reset by peer, if you are using in offline environment, please set TIKTOKEN_CACHE_DIR to use exsited files, check this link for more information:
failed to get gpt-4o token encoder: Get "https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken"
参阅:
https://stackoverflow.com/questions/76106366/how-to-use-tiktoken-in-offline-mode-computer
https://github.com/songquanpeng/one-api/issues/1819
解决方法:
执行以下命令下载相关文件,并将其复制到oneapi挂载目录oneapi/data/cache
curl -o 9b5ad71b2ce5302211f9c61530b329a4922fc6a4 https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken &&
curl -o fb374d419588a4632f3f557e76b4b70aebbca790 https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken
创建启动容器时使用环境变量TIKTOKEN_CACHE_DIR指定tiktoken的路径即可解决这个问题
docker run --name one-api -d --restart always -p 3001:3000 -e TZ=Asia/Shanghai -e TIKTOKEN_CACHE_DIR=/data/cache -v /usr/local/docker/oneapi:/data justsong/one-api
部署一个LLM模型
下载ChatGLM3项目
git clone https://github.com/THUDM/ChatGLM3
创建conda环境
cd /work/ChatGLM3
conda create -n ChatGLM3 python=3.10
conda activate ChatGLM3
编辑ChatGLM3/openai_api_demo/api_server.py文件,指定LLM模型、嵌入模型位置
相关模型可以从huggingface下载
# set LLM path
MODEL_PATH = os.environ.get('MODEL_PATH', '/root/work/models/chatglm3-6b')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
# set Embedding Model path
EMBEDDING_PATH = os.environ.get('EMBEDDING_PATH', '/root/work/models/bge-large-zh')
启动项目
(ChatGLM3) root@master:~/work/ChatGLM3/openai_api_demo# python api_server.py
Setting eos_token is not supported, use the default one.
Setting pad_token is not supported, use the default one.
Setting unk_token is not supported, use the default one.
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:04<00:00, 1.07it/s]
INFO: Started server process [517231]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
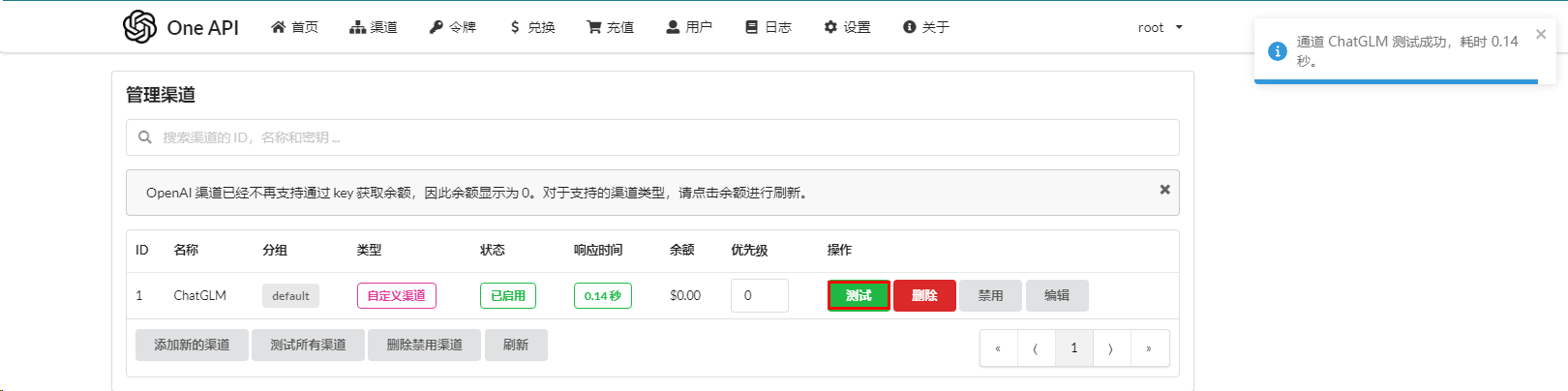
在OneAPI中创建一个渠道,并使用事先创建的API Key
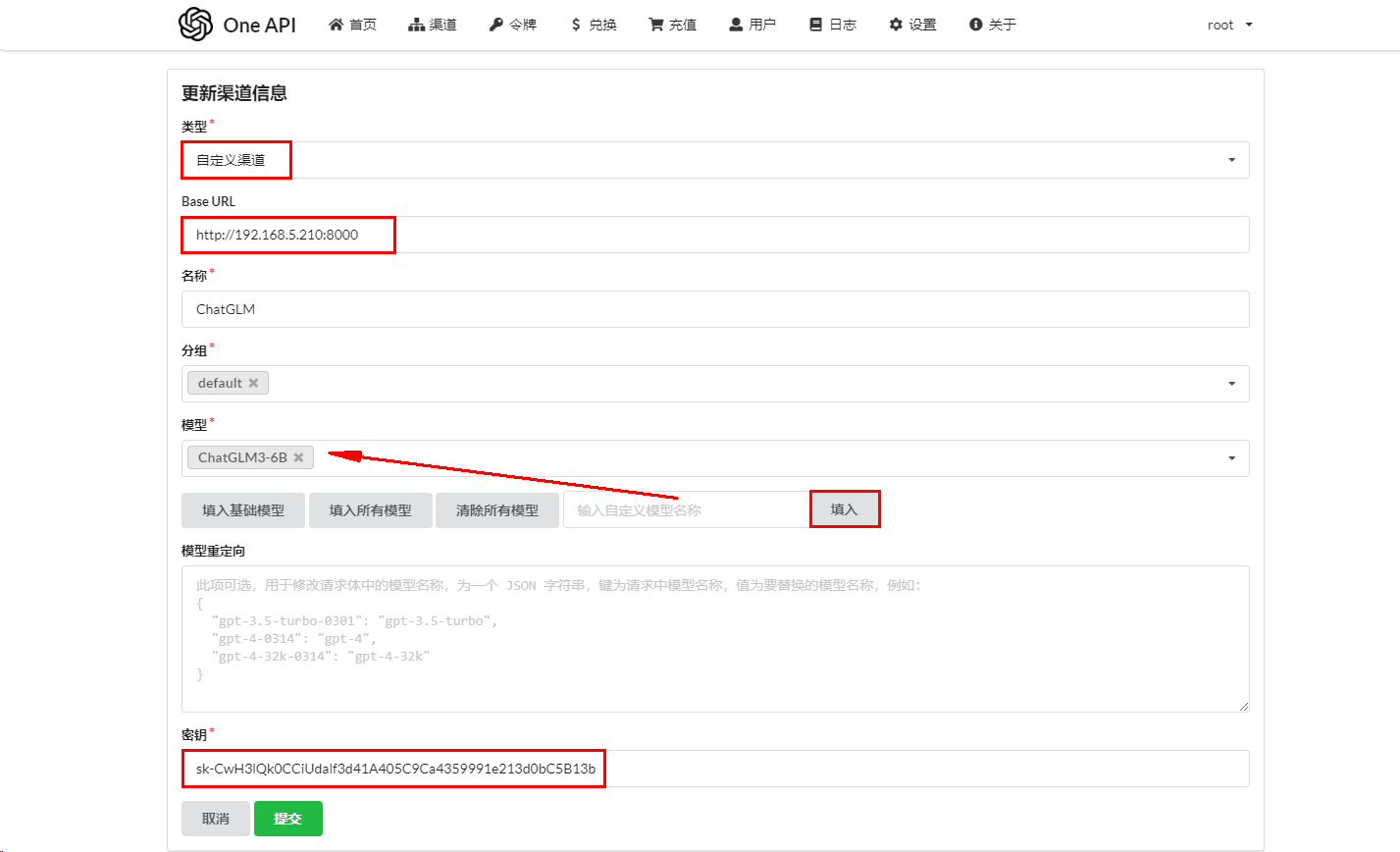
注意:
当完成下面
部署FastGPT操作后,可以测试对接是否成功。前提:这里配置的模型名称ChatGLM3-6B需要与在部署FastGPT中的fastgpt/config.json文件中配置模型名称一致。具体参考下面新建FastGPT对话应用操作。
部署嵌入模型
这里使用m3e嵌入模型
docker pull registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
在运行容器的时候调用GPU,直接使用--gpus all参数指定即可
docker run -d -p 6008:6008 --name m3e --gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
接入One API,添加一个渠道,根据官方参数说明如下:
设置安全凭证
默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
也可以通过环境变量引入:sk-key
注意:渠道对应鉴权密匙一定是sk-aaabbbcccdddeeefffggghhhiiijjjkkk

测试服务
这里将出现404异常,原因:由于不是对话生成模型(/v1/chat/completions)所以会404
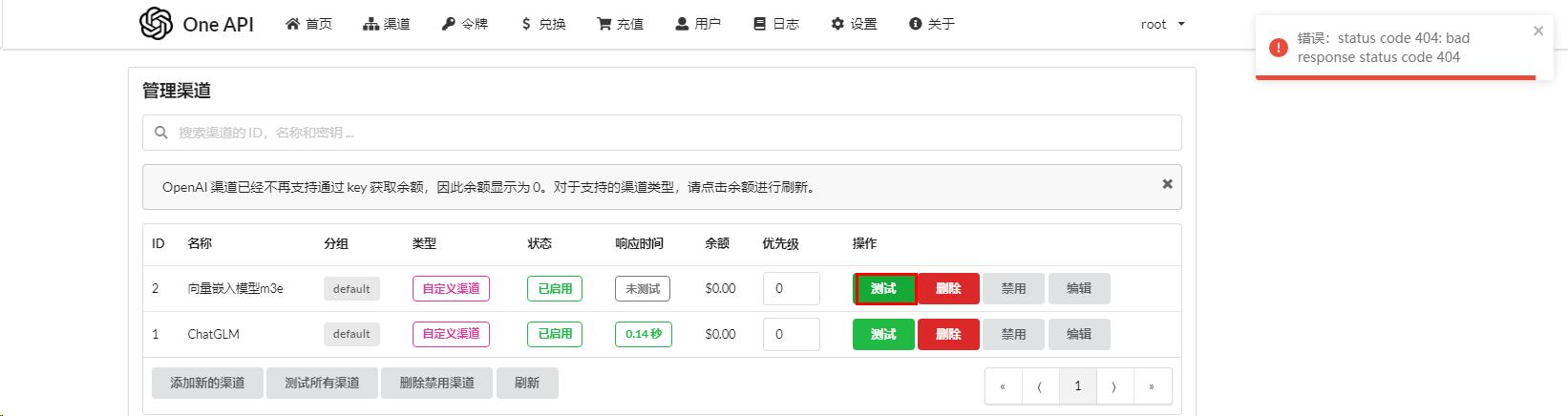
进一步验证,查看容器内部运行日志信息
root@master:~/work/# docker logs -f friendly_feistel
No sentence-transformers model found with name ./moka-ai_m3e-large. Creating a new one with MEAN pooling.
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:6008 (Press CTRL+C to quit)
本次加载模型的设备为GPU: Tesla V100S-PCIE-32GB
INFO: 172.17.0.1:59468 - "POST /v1/chat/completions HTTP/1.1" 404 Not Found
到这里,嵌入模型准备完毕,在接下来接入FastGPT即可。
特别说明: 在内网环境,离线部署时遇到如下异常:
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='openaipublic.blob.core.windows.net', port=443): Max retries exceeded with url: /encodings/cl100k_base.tiktoken (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7f61bcf675e0>: Failed to establish a new connection: [Errno 101] Network is unreachable'))
解决办法是:
拷贝容器中
/app目录下的文件到本地机器上,然后利用拷贝出来的localembedding.py文件,执行以下命令手动启动嵌入模型
nohup python localembedding.py > logs.log 2>&1 &
部署FastGPT
具体部署可参考官方文档:FastGPT
创建挂载目录
mkdir -p /usr/local/docker/fastgpt
下载文件
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
在项目fastgpt目录中,创建mongo密钥
openssl rand -base64 756 > ./mongodb.key
chmod 600 ./mongodb.key
chown 999:root ./mongodb.key
root@master:/usr/local/docker/fastgpt# ls
config.json docker-compose.yml mongodb.key
执行命令拉取容器镜像
docker-compose pull
启动容器
docker-compose up -d
初始化 Mongo 副本集(4.6.8以前可忽略)
# 查看 mongo 容器是否正常运行
docker ps
# 进入容器
docker exec -it mongo bash
# 连接数据库
mongo -u myname -p mypassword --authenticationDatabase admin
# 初始化副本集。如果需要外网访问,mongo:27017 可以改成 ip:27017。但是需要同时修改 FastGPT 连接的参数(MONGODB_URI=mongodb://myname:mypassword@mongo:27017/fastgpt?authSource=admin => MONGODB_URI=mongodb://myname:mypassword@ip:27017/fastgpt?authSource=admin)
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
# 检查状态。如果提示 rs0 状态,则代表运行成功
rs.status()
访问IP:3000
注意:
用户默认 root
密码默认 1234
密码设置修改:docker-compose.yml 文件中的 DEFAULT_ROOT_PSW
environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
配置docker-compose.yml文件,使用 OneAPI接口、令牌
注意:这里地址指向OneAPI地址,令牌使用上面创建的令牌。
environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
# 中转地址,如果是用官方号,不需要管。务必加 /v1
- OPENAI_BASE_URL=http://192.168.5.210:3001/v1
- CHAT_API_KEY=sk-CwH3lQk0CCiUdalf3d41A405C9Ca4359991e213d0bC5B13b
重启FastGPT容器
docker-compose up -d
新建FastGPT对话应用
接下来配置FastGPT,修改fastgpt/config.json文件,复制一份gpt-3.5-turbo配置,修改为ChatGLM
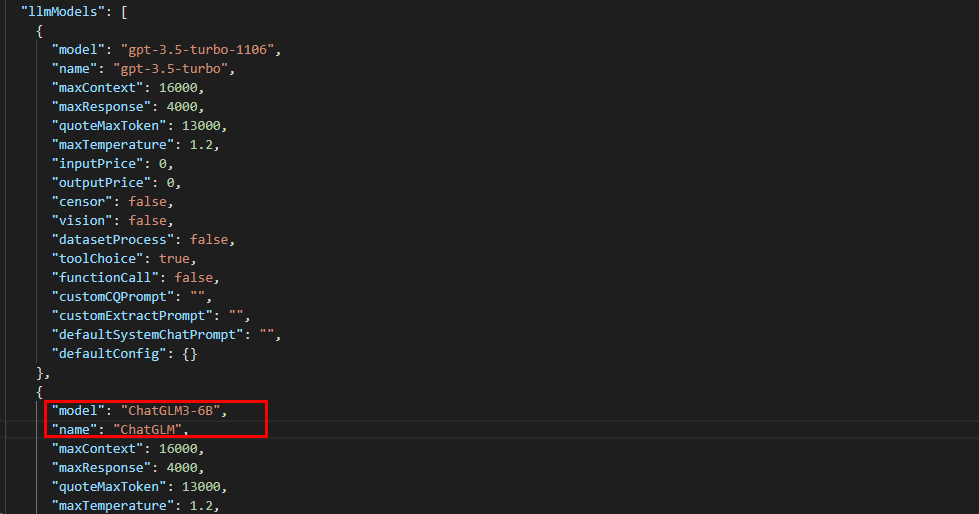
注意:这里配置的model值
ChatGLM3-6B需要与渠道中配置的模型名称一致
重启FastGP 容器
docker restart fastgpt
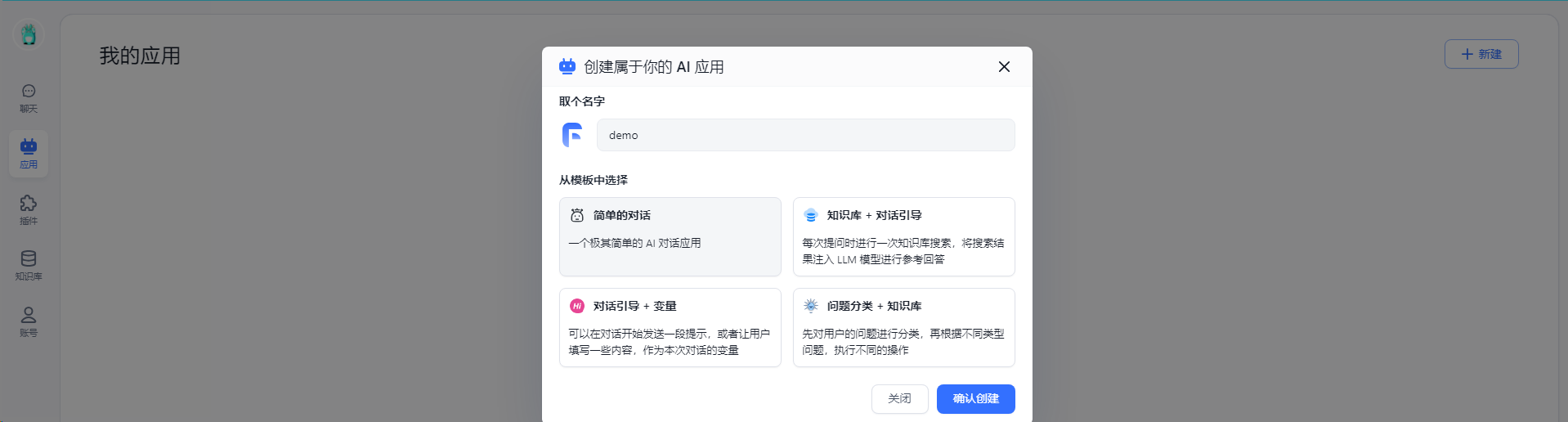
访问IP:3000/,新建FastGPT应用
取一个名称,从模板选择,这里选择“简单的对话”,点击“确认创建”按钮。
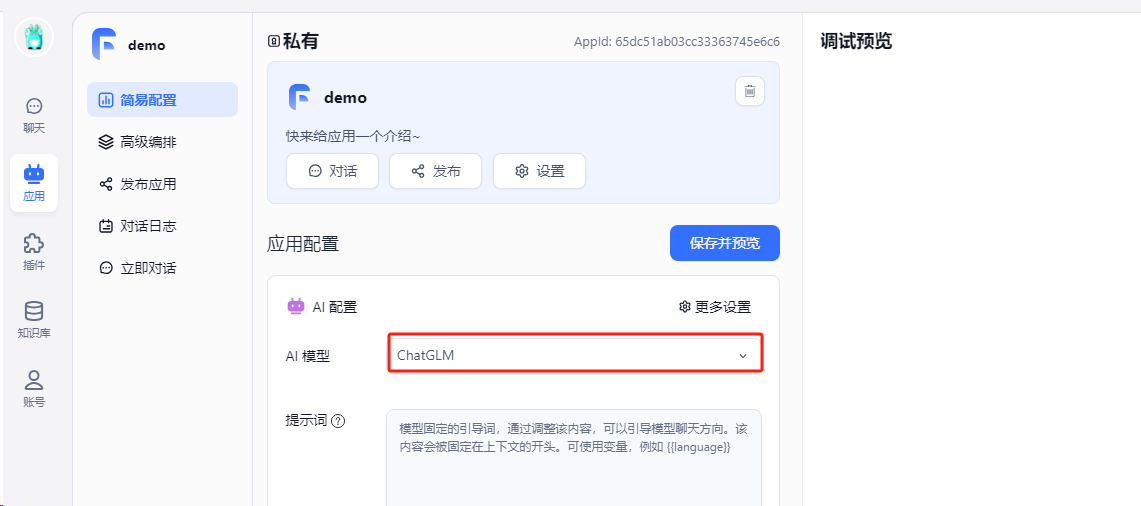
选择上面配置的ChatGLM模型,然后点击“保存并预览”
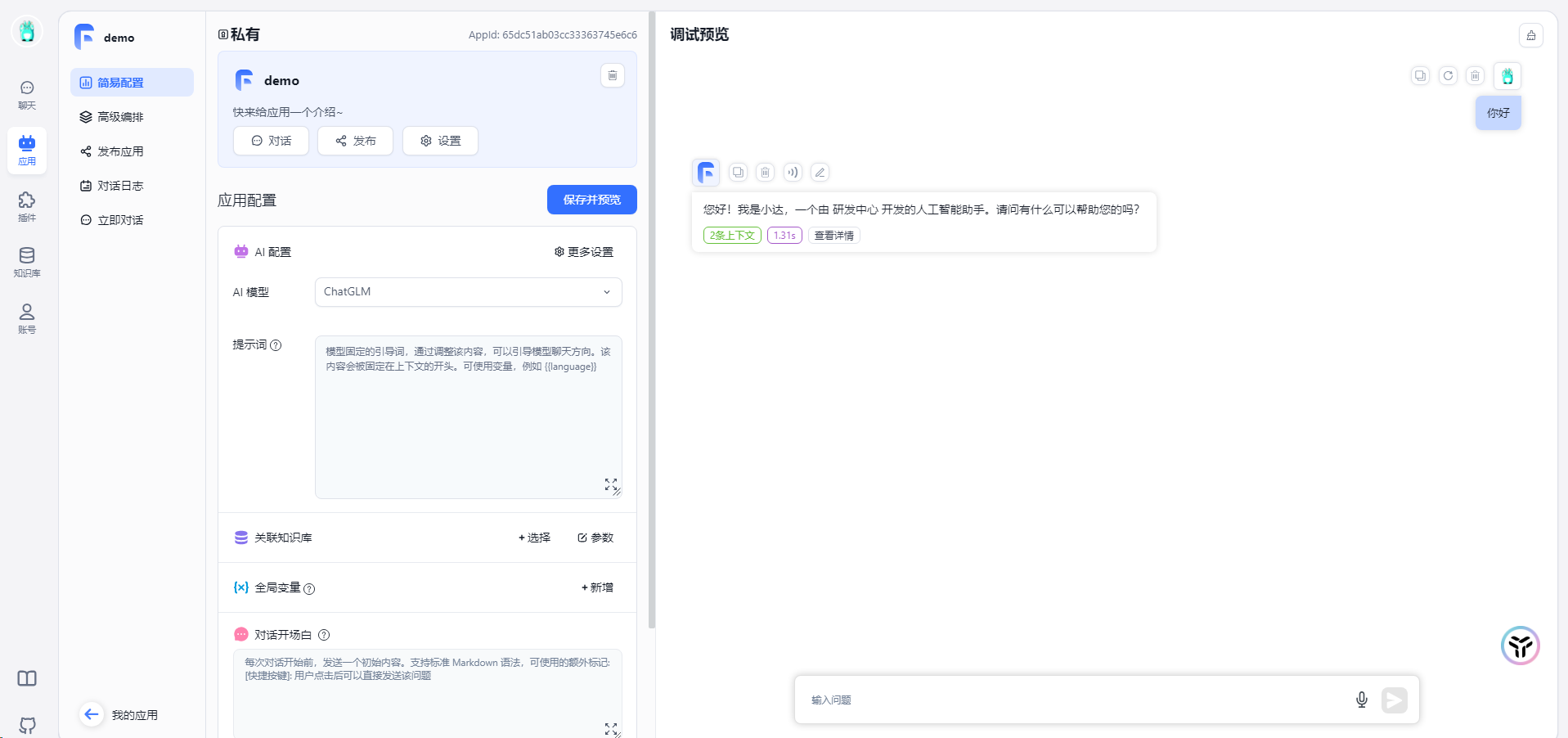
对话测试,输入问题,点击图标发送
新建 FastGPT 知识库应用
知识库需要使用嵌入模型,所以需要提前进行配置。
修改fastgpt/config.json配置文件,在vectorModels 中加入M3E模型:
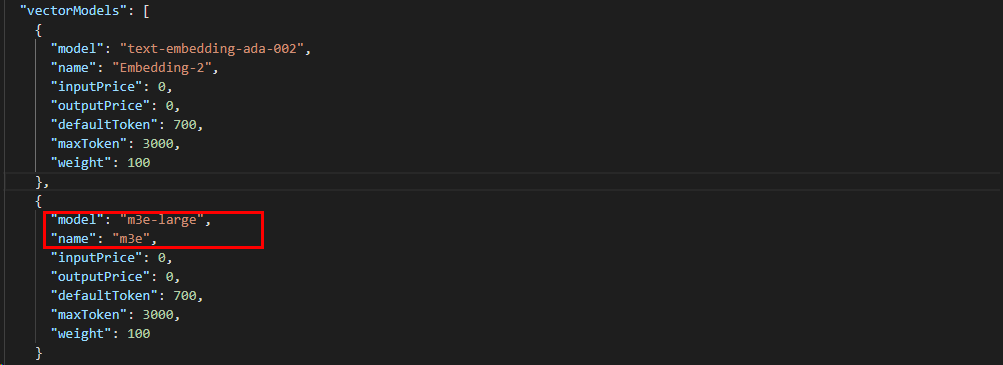
注意:这里配置的model值
m3e-large需要与渠道中配置的模型名称一致
重启FastGPT容器
docker restart fastgpt
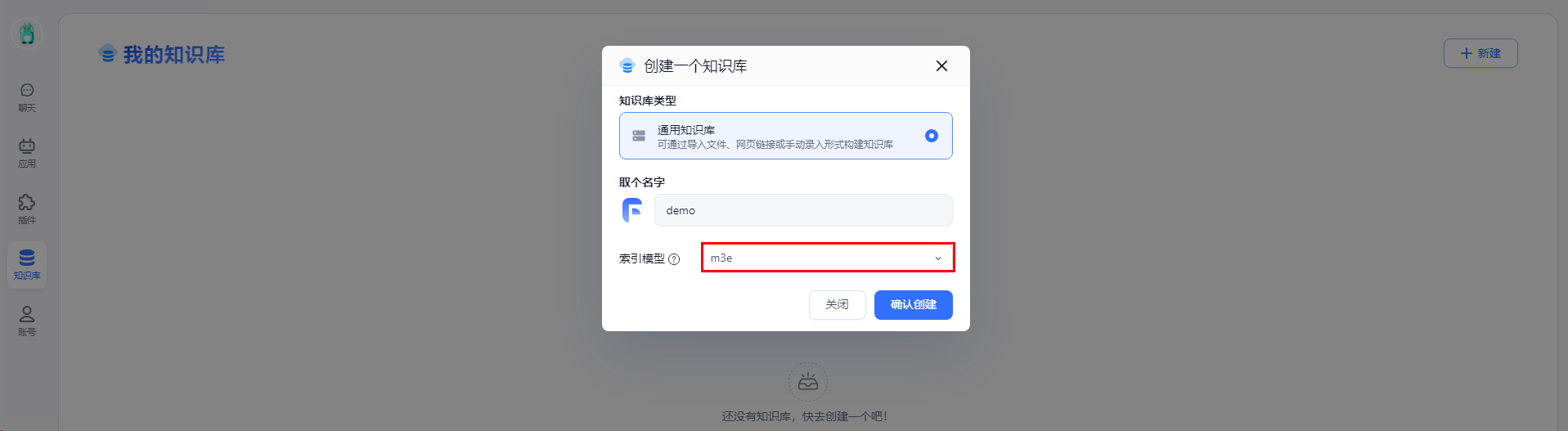
在知识库菜单栏,创建一个知识库,同时取一个名称,选择索引模型
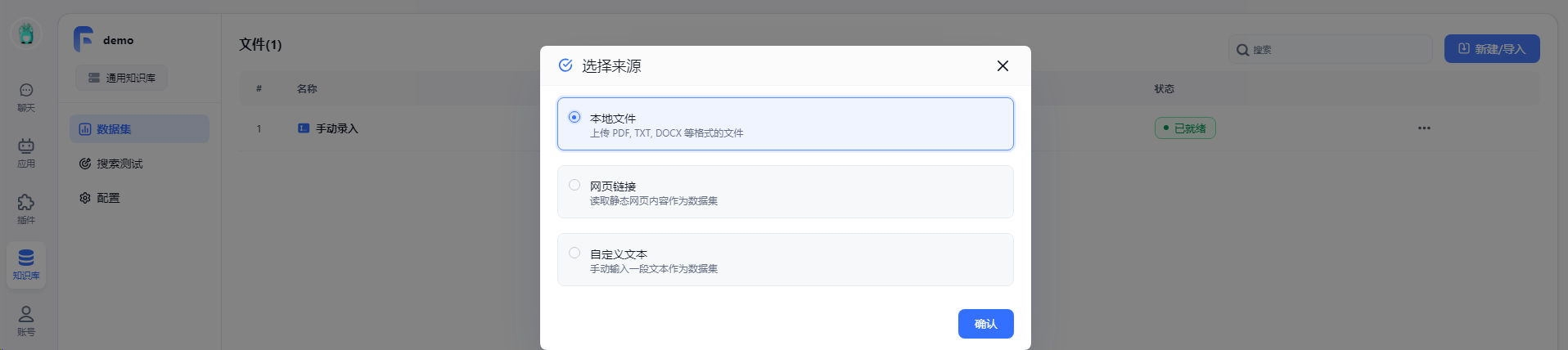
向demo知识库导入数据
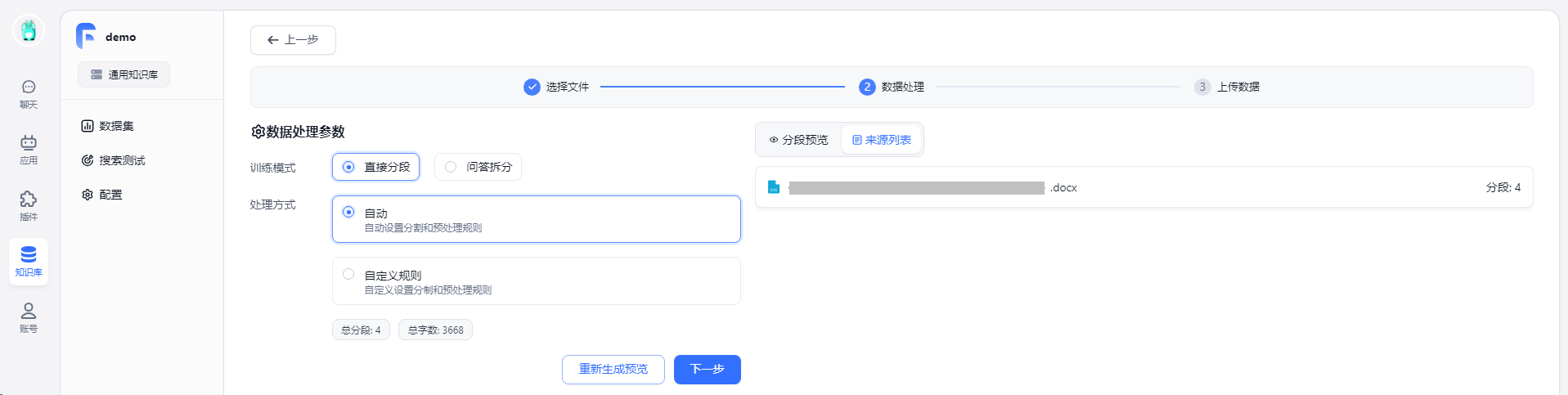
根据具体需求,进行配置数据处理参数
当上传数据训练完毕就绪后即可使用

新建知识库,取个名字,从模板选择知识库+对话引导
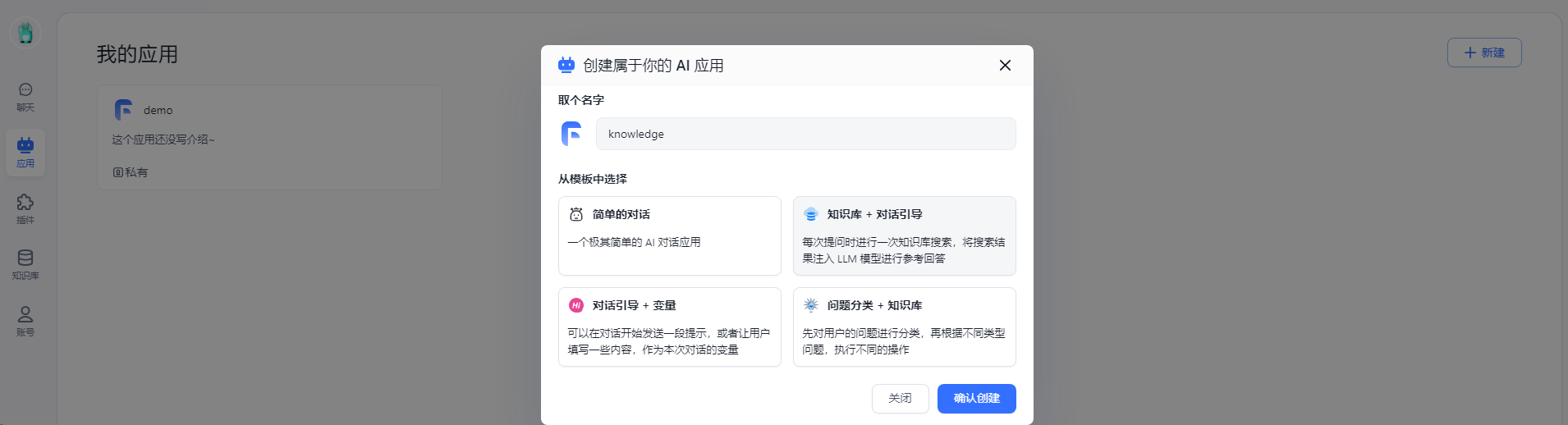
配置AI模型与关联知识库后,保存并预览,然后即可开始进行知识库的对话测试
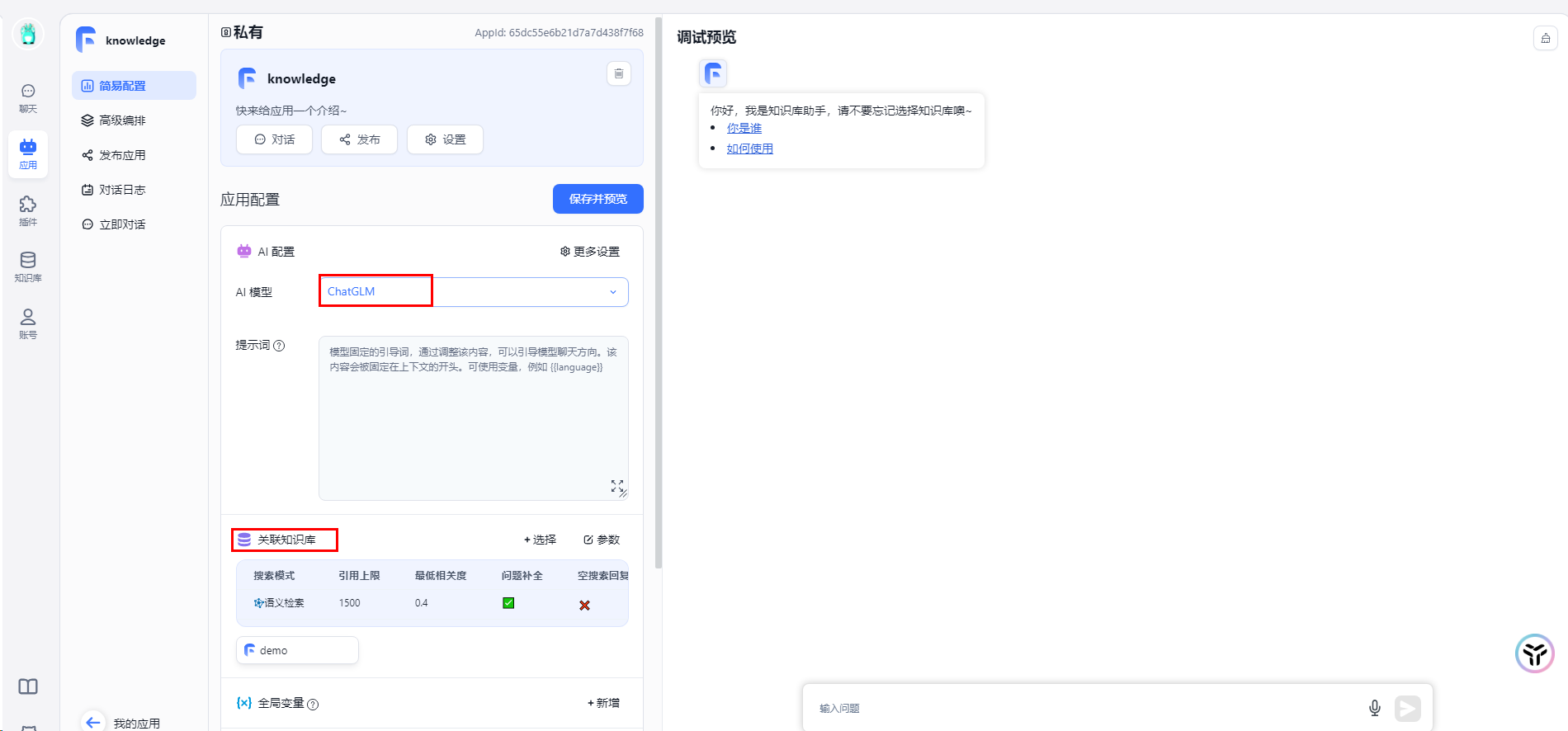
进行知识库问答对话时,出现一个异常

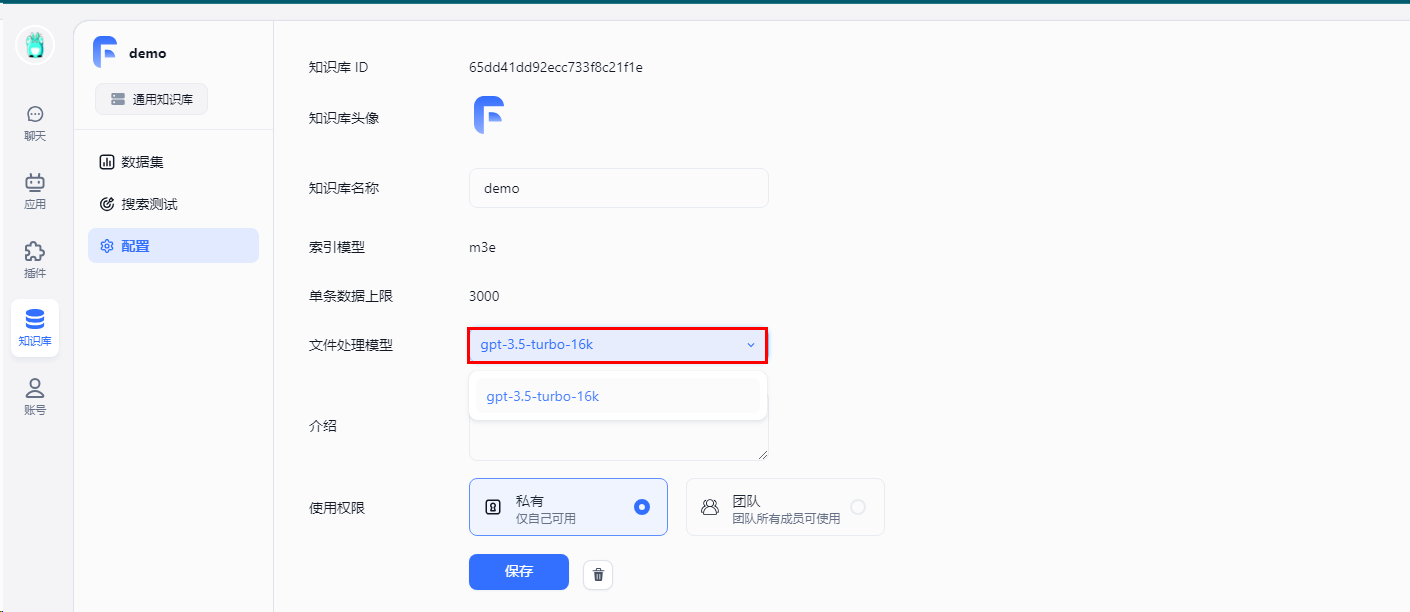
是因为知识库配置中,默认且只有一个文件处理模型,固定为gpt-3.5-turbo-1106,且目前没有配置该模型渠道
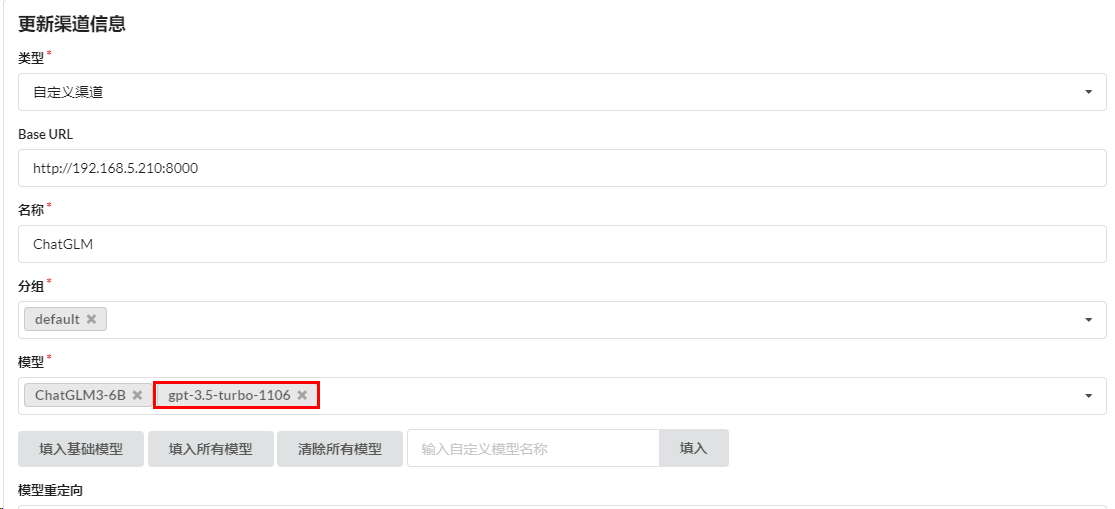
解决方案:
1.更新渠道,添加模型名称gpt-3.5-turbo-1106,意味着使用该模型的就会使用Base URL定义的模型
2.新建一个渠道,指定使用模型名称gpt-3.5-turbo-1106



















 3034
3034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











