






文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、幂等性
简介
例如:一次或者多次请求,得到的响应是一致的(网络超时等问题除外),多次执行以一次结果返回的结果是一致;
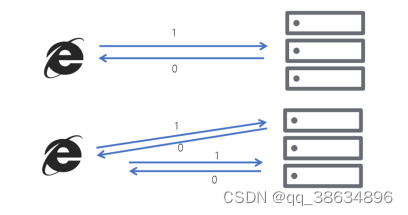
如果某个系统不具备幂等性,若用户重复提交了某个表格,就可能会造成不良影响。
KafKa消息的幂等性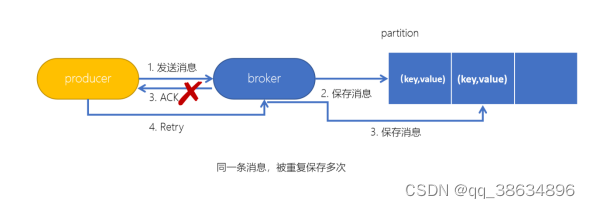
生产者在生产消息的时候,如果出现了retry,有可能一条消息将会被发送多次,若kafka不具备幂等性,就有可能会在partion中保存多条一模一样的消息;
配置幂等性
props.put(“enable.idempotence”);
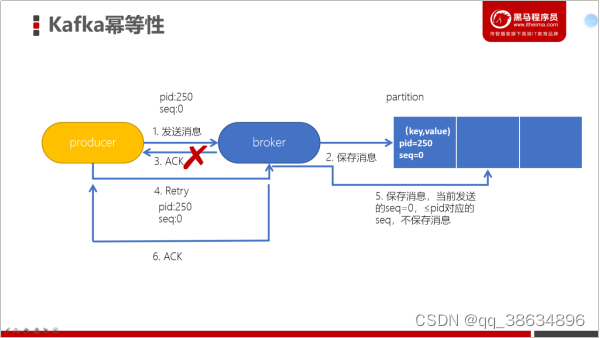
幂等性原理
为了实现生产者的幂等性,kaFka引入了 producer ID (PID) 和 Sequence Number的概念
PID:每个Producer在初始化的时候,都会分配唯一的id,对于用户来说,这个是透明的
Sequence Number: 针对每个生产者(对应的PID)发送到指定主题 分区消息都是对应从0开始的Sequence Number;
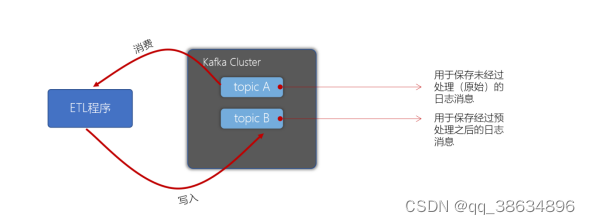
Kafka 事务
kafak 事务是指生产者生产消息 和消费者提交的offset的操作可以在一个原子操作当中,要么都成功,要么都失败;尤其是在生产者、消费者并存的时候,事务的保障尤其重要;
Kafka 事务 操作API
Producer 接口中定义了一下5个事务相关方法:
1.initTransactions(初始事务):要使用Kafka事务,就先要进行初始化操作;
2.beginTransaction(开始事务):启动一个kafka 事务;
3.sendOffsetsToTransaction(提交偏移量):批量的将分区对应的offset发送到事务中。方便后续一块提交;
4.commitTransaction(提交事务):提交事务;
5.abortTransaction(放弃事务): 取消事务;
Kafka 事务 编程
Kafka 事务 相关的属性配置
生产者
//配置事务的ID,开启了事务会默认幂等性
props.put("transactional.id", "first-transactional");
消费者
//消费者需要设置默认的隔离级别
props.put("isolation.level","read_committed");
//关闭自动提交
props.put("enable.auto.commit", "false");
Kafka 事务 编程
需求
在kafka的topic 中 【ods user】有一些用户数据
姓名,性别,出生日期
张三,1,1980-10-09
李四,0,1985-11-01
我们需要编写程序,将用户的性别转换为男,女(1.男;0:女)转换后将数据写入到topic【dwd user】 中 要求使用事务保障,要么消费了数据的同时写入到topic ,提交offset 要么全部失败;
启动生产者控制台模拟程序数据
# 创建名为ods_user和dwd_user的主题
bin/kafka-topics.sh --create --bootstrap-server node1.itcast.cn:9092 --topic ods_user
bin/kafka-topics.sh --create --bootstrap-server node1.itcast.cn:9092 --topic dwd_user
# 生产数据到 ods_user
bin/kafka-console-producer.sh --broker-list node1.itcast.cn:9092 --topic ods_user
# 从dwd_user消费数据
bin/kafka-console-consumer.sh --bootstrap-server node1.itcast.cn:9092 --topic dwd_user --from-beginning --isolation-level read_committed
编写创建消费者代码
编写一个方法createConsumer,该方法中返回一个订阅者,订阅【ods user】 注意:配置事务的隔离级别,关闭自动提交;
1.创建Kafka消费者消费者配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1.itcast.cn:9092");
props.setProperty("group.id", "ods_user");
props.put("isolation.level","read_committed");
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
1.创建消费者,并且订阅ods user 主题
//创建消费者
public static Consumer<String, String> createConsumer() {
}
二、使用步骤
1.引入库
代码如下(示例):
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









