







文章目录
通常,我们将一个连续的GPS信号点序列称为一个轨迹(Trajectory),在拥有GPS数据轨迹的情况下,我们能通过这些数据信息挖掘出哪些有效信息是数据挖掘在轨迹信息上的重要研究内容。在该实验中我们使用UCI上公开数据集,利用该轨迹数据集尝试挖掘其中的隐藏信息,在信息挖掘之前,我们需要对原始数据信息进行数据预处理,以保证算法拥有较为优质的输入数据。
1. 实验概览
通常,我们将一个连续的GPS信号点序列称为一个轨迹(Trajectory),在拥有GPS数据轨迹的情况下,我们能通过这些数据信息挖掘出哪些有效信息是数据挖掘在轨迹信息上的重要研究内容。在该实验中我们使用UCI上公开数据集,利用该轨迹数据集尝试挖掘其中的隐藏信息,在信息挖掘之前,我们需要对原始数据信息进行数据预处理,以保证算法拥有较为优质的输入数据,因此整个实验一共分为以下几个步骤:
- 下载轨迹数据集
- 对轨迹数据集进行数据预处理
- 相关信息挖掘
接下来,我们按照该顺序进行依次讲解。
2. 数据集下载
本次实验我们选用UCI上的公开数据集(链接),数据集中共包括两个文件:go_track_tracks.csv 和 go_track_trackpoints.csv,两个文件内容分别如下所示:
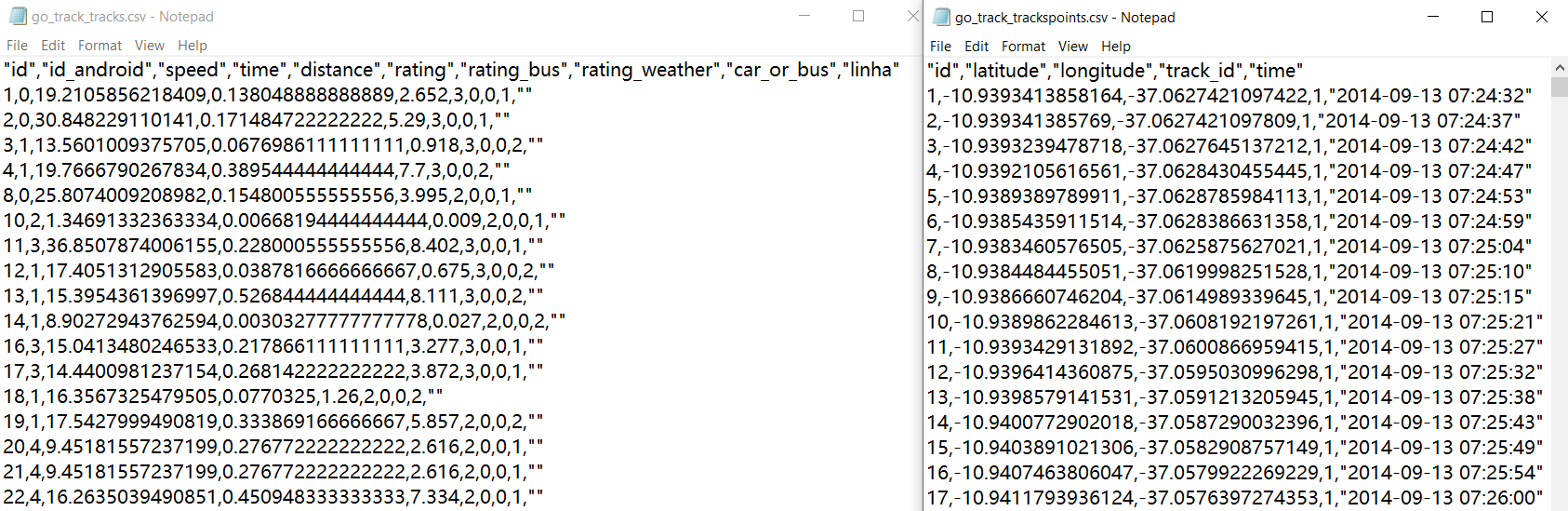
可以分析出,go_track_tracks.csv 文件中存放的是每一条 trajectory 的全局信息,例如该条 trajectory 的 id、该条 trajectory 是属于车辆的轨迹还是公共汽车的轨迹、平均速度等(具体细节参考前文UCI链接);而与之对应的,go_track_trackpoints.csv 文件中存放的是每一条 trajectory 中每一个轨迹点的记录信息,例如经纬度、时间戳等。
我们对轨迹数据进行解析,利用 OSMNX 将数据集中的轨迹做可视化,这里挑出其中一个轨迹,可视化结果如下:
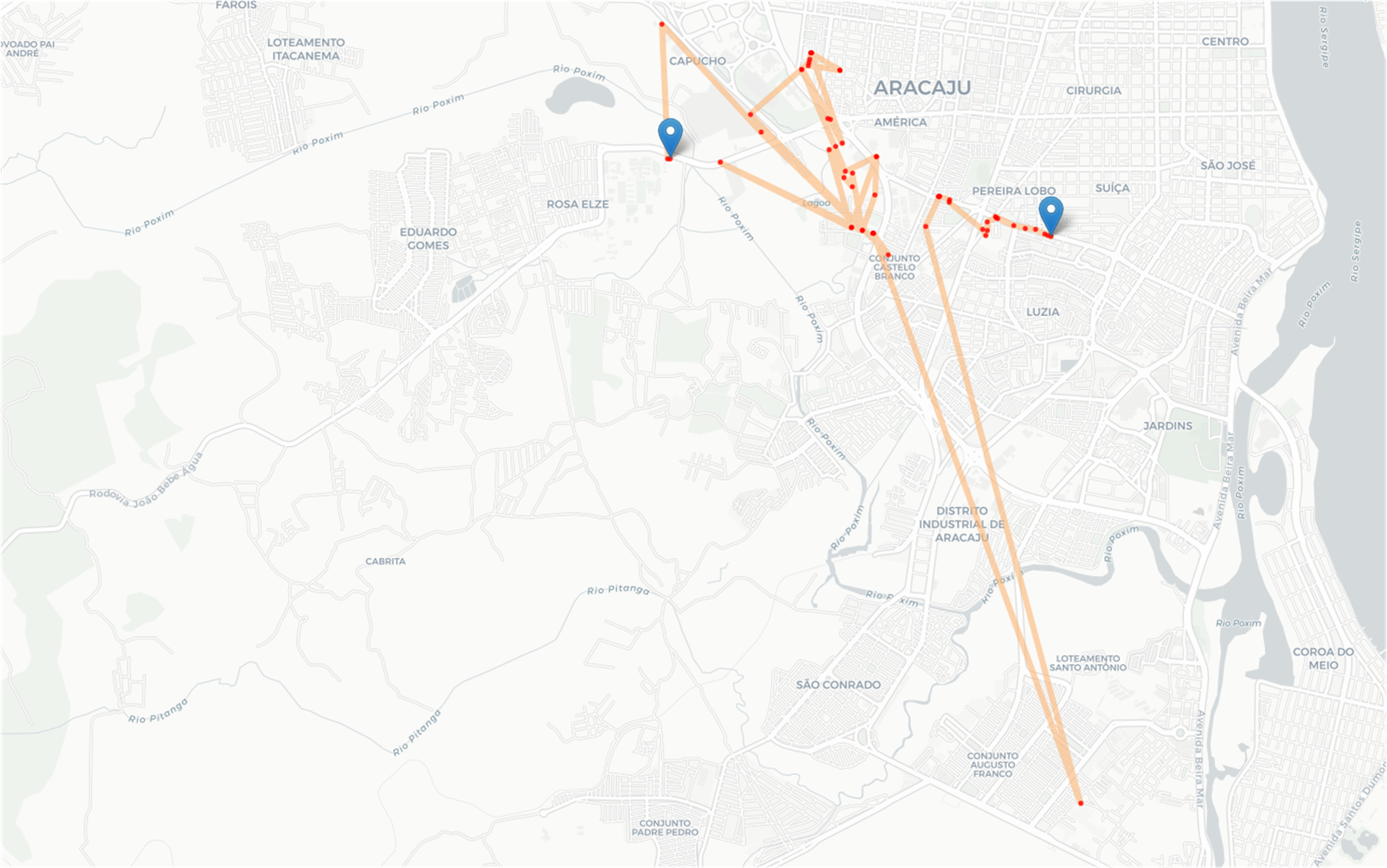
通过可视化可以看出,原始的轨迹信息十分杂乱,甚至会出现一些因为GPS设备误差而生成的不合理轨迹点。如上图中所示,可以看到一条轨迹中参杂了一个偏离非常远的轨迹点,使得整个轨迹非常突兀,因此在进行数据挖掘前,我们首先需要对这些原始数据集做数据预处理工作。
3. 数据预处理
数据预处理是在进行数据分析之前非常重要的一个步骤,对于轨迹数据的预处理,该实验中一共经历了3个阶段:
- 异常点去除
- 停留点与围绕点的检测与去除
- 轨迹分段
下面,我们就依照这个顺序将数据集中的轨迹数据进行一步步的清洗。
3.1 异常点去除
异常点是指因为GPS设备误差或者其他原因等产生的不合理的一些噪声信号点,识别异常点的一个方法是根据相邻两个点之间的间隔时间与间隔距离计算出行驶速度,将明显不符合实际速度的轨迹点给清除掉,部分代码如下:
# 遍历计算坐标轨迹中所有相邻点的距离和间隔时间并计算出速度,与最大速度阈值比较,筛选出符合正常速度区间的轨迹点
for i in range(1, len(origin_positions)):
distance = geodesic(origin_positions[i-1], origin_positions[i]).km
hours_used = get_hours_from_two_time_string(time_list[i-1], time_list[i])
speed = max_speed_threshold if hours_used == 0 else distance / hours_used
if speed < max_speed_threshold:
result_positions.append(origin_positions[i])
result_time_list.append(time_list[i])
result = {
track_id: {
'positions': result_positions, 'time_list': result_time_list, 'mean_speed': mean_speed}}
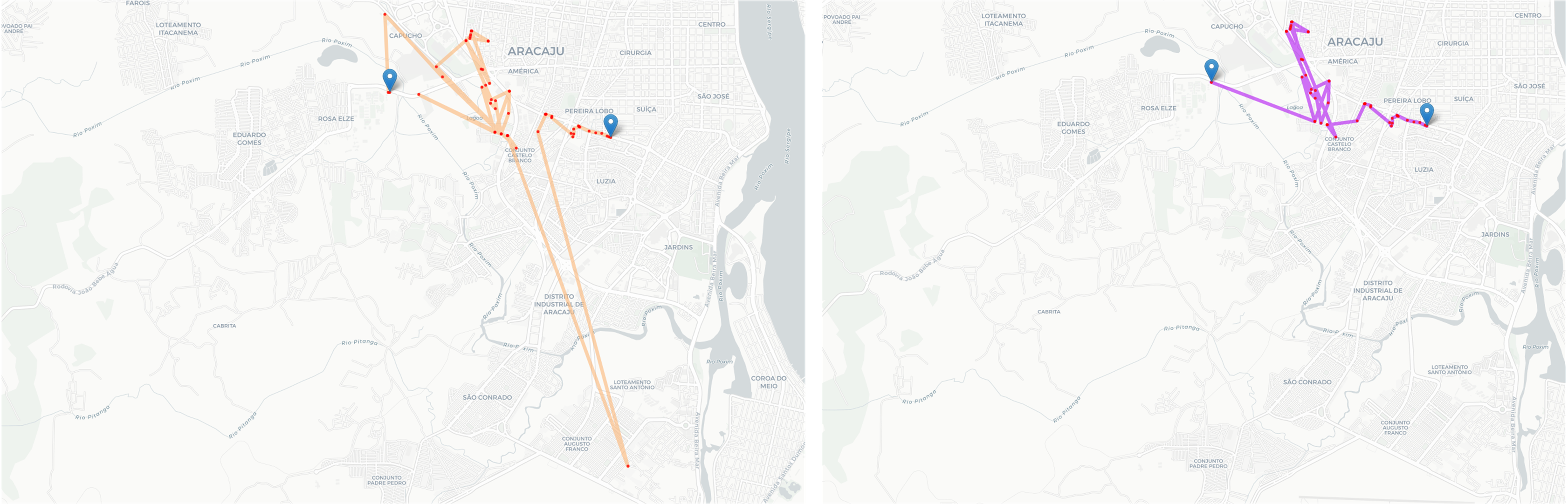
下图是我们未进行异常点去除和进行了异常点去除之后的对比图,可以看出,经过最大速度值为 150km/h 的条件筛选后,右下角的异常数据点已经被清除掉,轨迹变得比清洗前连续性显得更好。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7747
7747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









