







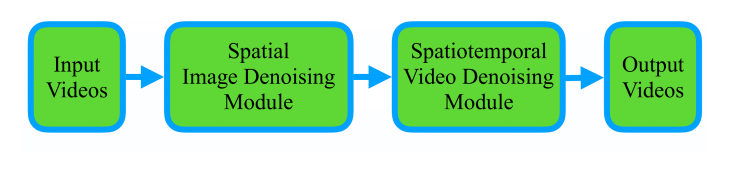
First image then video: A two-stage network for spatiotemporal video denoising
http://export.arxiv.org/abs/2001.00346
作者:王策 南开大学
本文针对的是视频中出现大运动。或者前景和背景由于弱光环境较弱时造成去噪性能差的问题而解决,论文时在FastDVDnet网络上的改进,相比较于SOTA的FastDVDnet和ToFlow方法,我认为本文的亮点可以归结为两个方面:
(1) 将去噪的阶段分为了两个部分增强了去噪的效果,
(2) 将图片无监督去噪网络的思想移植到了视频去噪上,可以解决数据集不足的问题。
摘要
问题:现存的 spatiotemporal processing去噪算法容易motion blur artifacts,即当对象快速移动时,光流计算失误,造成运动对象的边界会变得模糊
关于运动模糊的说明:the boundary of a moving object tends to appear blurry especially when the object undergoes a fast motion, causing optical flow calculation to break down.
解决办法:提出了a first-image-then-video two-stage denoising neural network,该算法首先在spatially 空间上降低intra-frame noise帧内噪声,然后应用spatiotemporal video denoising module.时空视频去噪,在任何地方都达到了较高的去噪性能,包括快速移动物体的边界
架构优势:图像去噪的第一阶段有效地降低了噪声水平,因此,时空去噪的第二阶段允许在任何地方进行更好的建模和学习,包括沿移动对象边界
the first stage of image denoising effectively reduces the noise level and, therefore, allows the second stage of spatiotemporal denoising for better modeling and learning everywhere, including along the moving object boundaries.
同时介绍一种:可以与有监督的方法相同性能的无监督方法。
1. 介绍
-
图像去噪:传统方法的性能还可以,目前为了进一步解决利用CNN的方法去噪,其效果在不考虑对输入的过多假设和要求下,性能可以。
-
视频去噪中的时间信息获取和分析:由于
object motion in videos而存在的inter-frame temporal deformation帧间变形,视频去噪可以通过适当建模完成。例如,最先进的 **TOFlow[36]**方法试图在端到端可训练网络中同时执行运动分析和视频去噪。然而,当这些物体经历如图 1 © 所示-
objects undergo a fast motion 快速运动时,
-
the foreground and background between these boundaries are of weak contrast due to say the low light environment. 边界之间的前景和背景由于弱光环境而具有较弱的对比度时,
-
我们经常在其去噪结果中观察``The blurry phenomenon`。是因为即使在如此精心设计的面向任务的流量估计方法中,视频中这些对象的运动估计也会失效。
此外,目前基于CNN方法虽然只对每一帧调用图像去噪算法是无效的,但像V-BM4D[17]这样的时空去噪,它通过在空间和时间维度上搜索相似的块来扩展BM3D [5]是有启发性的。FastDVDNet是一种SOTA VD,通过采用改进的U-Net[24]架构扩展了基于流的DVDNet[29],以实现具有强大CNN 表示的时空去噪。这避免了对物体运动的显式估计,但图 1(d) 所示的结果表明,spatiotemporal denoising block 仍然不能很好地处理high-speed moving objects,因为
(1)spatial noise distribution and temporal deformation are very different 空间噪声分布和时间变形
(2)dealing with them together in a mixed fashion is too challenging 两者以混合方式一起处理它们太具有挑战性了。
时空去噪块的有限能力带来了我们工作的主要动机:我们能否通过将基于CNN的时空去噪分成两阶段过程来应对这一挑战,其中第一个模块试图在空间上减少Nt中的帧内噪声第二个模块,仍然是常规的时空帧间视频去噪,是否能够在第一阶段的“处理”输入的帮助下处理这些情况?
The limited capability of spatiotemporal denoising block brings the main motivation of our work: Can we address this challenge by separating CNN-based spatiotemporal denoising into a two-stage procedure, in which the first module tries to spatially reduce the intra-frame noise in Nt and the second module, still as regular spatiotemporal inter-frame video denoising, is able to handle these cases with the help of “processed” inputs of the first stage?

因此,本文提出FITVNet,我们使用图像到图像网络架构实现第一个模块,通过空间处理降低每个图像/帧内的噪声,第二个模块作为常规时空视频去噪网络。这两个模块由提出的损失函数共同监督,在不同的训练阶段彼此之间具有平衡的学习率。通过这样的训练过程,第一阶段的输出特征显示出降低帧内噪声的高去噪性能,尤其是在 TOFlow 和 FastDVD 无法恢复的对象边界上。
These two modules are jointly supervised by a proposed loss function with a balanced learning ratio between each other in different training phases.
2. 相关工作
简单概括(纯翻译):
图像去噪:…最近又提出了Noise2Void[13]Noise2Self[2]和noise-as-clean[34],缓解了Noise2Noise中成对图像必须具有相同场景、独立采样且噪声分布相同的硬性要求。在这项工作中,我们将把Noise2Noise的想法纳入FITVNet。
视频去噪:在视频去噪中采用传统的[23,35]方法进行流场计算。后续工作[7,10,22]提出了端到端网络的流量估计。
然后TOFlow[36]和DVDNet[29]进一步同时预测光流和去噪帧,而不是像[20]那样分离这两个任务,并获得了优于V-BM4D[17]的最新结果,这类似于VNLB[1]作为BM3D[5]的扩展。然而,使用估计的流场在相邻帧之间进行图像扭曲是非常耗时的。更糟糕的是,当物体经历快速运动或前景和背景之间的图像对比度较弱时,流计算往往不准确,导致去噪帧中物体边界的过度平滑和细节丢失。或者,ViDeNN[4]和FastDVDNet[30]提出了一个端到端网络来实现时空去噪,就像视频涂装中所做的[9][19][32]。这两种方法都将有噪声和无噪声的视频对馈入网络,依次降低输入帧的噪声。
同样,NLNet[6]在视频去噪中融合了CNN和自相似搜索策略,VINet[11]成功地将CNN应用于视频涂装中。此外,[8]提出了一种基于DnCNN[37]和Noise2Noise的盲去噪方法,这促使我们在视频去噪过程中采用了无监督图像去噪算法。在这项工作中,我们将超越一个时空视频去噪网络,并提出一个用于监督和非监督视频去噪的两阶段FITVNet。
3. FITVNet模型
理论背景:
相邻帧之间的object motion是很重要的内容,使用光流是很常见的方法。
目前2K个相邻帧$I_{t-k+i}(x)
,同时围绕着一个参考帧
,同时围绕着一个参考帧
,同时围绕着一个参考帧I_t (x)$,从而生产干净帧,此时假设的温度恒定“constancy of brightness”:
I
t
+
k
(
x
)
=
I
t
(
x
+
δ
k
x
)
;
k
∈
{
−
K
,
…
,
K
−
1
,
K
}
I_{t+k}(x)=I_{t}\left(x+\delta_{k} x\right) ; \quad k \in\{-K, \ldots, K-1, K\}
It+k(x)=It(x+δkx);k∈{−K,…,K−1,K}
2K个相邻帧,
I
t
I_t
It表示当前亮度恒定条件下,当前帧=参考帧+帧间光流场。
δ
k
x
δ_k x
δkx 表示估计的两针之间的光流场,如果the optical flow field光流场small magnitude较小,那么使用the first-order Taylor approximation一阶泰勒近似,从而使得temporal deformation becomes “additive”时间变形,变得加性。
I
t
+
k
(
x
)
≈
I
t
(
x
)
+
J
t
(
x
)
δ
k
x
I_{t+k}(x) \approx I_{t}(x)+J_{t}(x) \delta_{k} x
It+k(x)≈It(x)+Jt(x)δkx
如果光流场较小,使用一阶近似,其中J表示雅可比矩阵.$ J_t (X)$ 表示雅克比矩阵,因此,在真实世界中,噪声帧可以表示为
I
^
t
+
k
(
x
)
=
I
t
+
k
(
x
)
+
N
k
(
x
)
=
I
t
(
x
+
δ
k
x
)
+
N
k
(
x
)
≈
I
t
(
x
)
+
J
t
(
x
)
δ
k
x
+
N
k
(
x
)
\begin{aligned} \hat{I}_{t+k}(x) &=I_{t+k}(x)+N_{k}(x) \\ &=I_{t}\left(x+\delta_{k} x\right)+N_{k}(x) \\ & \approx I_{t}(x)+J_{t}(x) \delta_{k} x+N_{k}(x) \end{aligned}
I^t+k(x)=It+k(x)+Nk(x)=It(x+δkx)+Nk(x)≈It(x)+Jt(x)δkx+Nk(x)
在真实世界中,其中
N
k
N_k
Nk 表示增加的噪声,例如AWGN(additive white Gaussian noise),对于实际当前帧==当前的干净帧+噪声将上述带入得3
在DVDnet中,通过学习近似映射函数T来实现。其本质包含两部分:1估计相邻帧和参考帧之间的光流 δ k ( x ) δ_k (x) δk(x); 2利用这些中间变量来预测干净的参考帧 I t ( x ) I_t (x) It(x)
I
t
(
x
)
=
T
(
{
I
^
t
+
k
(
x
−
δ
k
x
)
}
k
=
−
K
K
)
I_{t}(x)=T\left(\left\{\hat{I}_{t+k}\left(x-\delta_{k} x\right)\right\}_{k=-K}^{K}\right)
It(x)=T({I^t+k(x−δkx)}k=−KK)
虽然这两部分通过两个不同网络实现,但是TOFlow更进一步,通过端到端的网络,学习光流的同时估计和变形帧的融合,因此性能更好。但是如上图1,无法实现精确的运动估计,还是有问题。与此同时,FastDVDnet中通过时空去噪块,跳过了光流计算,可以表示为:
I
t
(
x
)
=
Φ
(
{
I
^
t
+
k
(
x
)
}
t
=
−
K
K
)
I_{t}(x)=\Phi\left(\left\{\hat{I}_{t+k}(x)\right\}_{t=-K}^{K}\right)
It(x)=Φ({I^t+k(x)}t=−KK)
Φ表示执行的是时空处理过程,通过CNN近似。但是其在 快速移动对象上发生 明显的模糊物体边界是失败。因此,本文受此启发,将其分为两个阶段。
I
t
(
x
)
=
Φ
(
{
Ψ
(
I
^
t
+
k
(
x
)
)
}
t
=
−
K
K
)
I_{t}(x)=\Phi\left(\left\{\Psi\left(\hat{I}_{t+k}(x)\right)\right\}_{t=-K}^{K}\right)
It(x)=Φ({Ψ(I^t+k(x))}t=−KK)
ψ过程是对每一个图片进行的单独去噪,ϕ 是采集相邻帧的时空信息进行补全。。即将图像去噪结果作为输入,送入到时空去噪模块中处理得到干净帧。

The spatial image denoising stage
采用的是 modified architecture of Noise2Noise来近似映射函数Ψ,其输入2K+1=5帧,然后共享相同的架构和参数。每帧使用L2损失函数
L
s
t
=
Σ
i
∥
Φ
γ
(
{
Ψ
θ
(
I
^
t
+
k
(
x
)
)
}
k
=
−
K
K
)
−
I
t
∥
2
,
\mathcal{L}_{s t}=\Sigma_{i}\left\|\Phi_{\gamma}\left(\left\{\Psi_{\theta}\left(\hat{I}_{t+k}(x)\right)\right\}_{k=-K}^{K}\right)-I_{t}\right\|_{2},
Lst=Σi
Φγ({Ψθ(I^t+k(x))}k=−KK)−It
2,
其中,
{
I
^
t
+
k
}
k
=
−
K
K
\left\{\hat{I}_{t+k}\right\}_{k=-K}^{K}
{I^t+k}k=−KK表示输入帧,
{
Ψ
θ
}
k
=
−
K
K
\left\{\Psi_{\theta}\right\}_{k=-K}^{K}
{Ψθ}k=−KK表示相应帧的映射函数。
θ
\theta
θ表示模块的网络参数,
{
I
^
t
+
k
}
k
=
−
K
K
\left\{\hat{I}_{t+k}\right\}_{k=-K}^{K}
{I^t+k}k=−KK表示输入帧的监督信号。
网络结构特别之处:将原来的池化层用步长为2的卷积层替代,保留更多细节,为下一层提取便捷。
作者提出了三种方法(更改不同的损失函数)以适用于不同目标信号:
FITVNet (base):不引入监督信号
FITVNet (+jsn):引入噪声帧作为目标监督信号 L p d = Σ k = − K K ∥ Ψ θ ( I ^ t + k ) − I ~ t + k ∥ 2 \mathcal{L}_{p d}=\Sigma_{k=-K}^{K}\left\|\Psi_{\theta}\left(\hat{I}_{t+k}\right)-\tilde{I}_{t+k}\right\|_{2} Lpd=Σk=−KK Ψθ(I^t+k)−I~t+k 2
FITVNet (+jsc): 引入干净帧作为目标监督信号 L p d \mathcal{L}_{p d} Lpd
在FITV(+jsn)中,作者引入了Nosie2Nosie的思想以具有噪声的帧作为目标监督信号,实现了一定意义上的无监督训练。
通过实验对比,FITVNet (+jsn)更成功。
注意,其他无监督的图像去噪方法,如Noise2V oid [13] Noise2Self[2]和Noise-AsClean[34]也可以使用,我们将在未来探索。
此外,FITVNet (+jsn)的成功,它以无监督的方式训练我们的第一个模块
The spatiotemporal video denoising stage
我们使用另一个网络来获取相邻帧之间的时间信息,即需要更多的帧作为输入来利用这些帧之间的物体运动信息。
通过之前图像去做输出的2K+1先验图像帧
ψ
(
I
t
−
K
)
ψ (I_t-K)
ψ(It−K)
ψ
(
I
t
−
K
−
1
)
ψ (I_t-K-1)
ψ(It−K−1)
ψ
(
I
t
+
K
)
ψ (I_t+K)
ψ(It+K),同时选取中心帧去噪输出,使用L2作为监督学习过程
L
s
t
=
Σ
i
∥
Φ
γ
(
{
Ψ
θ
(
I
^
t
+
k
(
x
)
)
}
k
=
−
K
K
)
−
I
t
∥
2
,
\mathcal{L}_{s t}=\Sigma_{i}\left\|\Phi_{\gamma}\left(\left\{\Psi_{\theta}\left(\hat{I}_{t+k}(x)\right)\right\}_{k=-K}^{K}\right)-I_{t}\right\|_{2},
Lst=Σi
Φγ({Ψθ(I^t+k(x))}k=−KK)−It
2,
其中
ψ
r
ψ_r
ψr表示去噪块的映射函数,
I
t
I_t
It表示输出的干净帧,然而,先前的去噪模块会影响当前的去噪性能,因此,在联合监督过程中,添加了一个衰减函数α来平衡。
最后的损失函数Loss
α
e
L
p
d
+
L
s
t
\frac{\alpha}{e} \mathcal{L}_{p d}+\mathcal{L}_{s t}
eαLpd+Lst
其中e表示本次迭代之前的epoch总数
与 PWC-Net [26] 和 TOFlow [36] 等基于流的方法不同,这种基于CNN的时空去噪网络需要在一个模块内对空间噪声和时间变形进行建模。我们通过FastDVDNet[30]中采用的方法实现该模块,该方法使用一个块处理总共五个帧中的每三个连续帧,**然后将第一个块的连接输出特征馈送到另一个块,**如图所示。
避免了在这些基于流的模型中次优的显式流计算,实验表明,CNN 的代表性能力有助于避免在先验图像去噪的帮助下出现在TOFlow中的边界模糊。此外,还消除了基于流的方法中昂贵的翘曲操作计算。
Unsupervised FITVNet
在时空去噪阶段采用图像去噪,以及FITV(+jsn)的成功,说明有机会设计一种无监督的方法。
只需要把 I t I_t It用如下进行修改。这样避免了使用真实干净图像。(避免了真实数据集的不足。)
L s t = Σ i ∥ Φ γ ( { Ψ θ ( I ^ t + k ( x ) ) } k = − K K ) − Ψ θ ( I ^ t ) ∥ 2 \mathcal{L}_{s t}=\Sigma_{i}\left\|\Phi_{\gamma}\left(\left\{\Psi_{\theta}\left(\hat{I}_{t+k}(x)\right)\right\}_{k=-K}^{K}\right)-\Psi_{\theta}\left(\hat{I}_{t}\right)\right\|_{2} Lst=Σi Φγ({Ψθ(I^t+k(x))}k=−KK)−Ψθ(I^t) 2
同时,在训练过程中,我们放大衰减系数 α 以确保第一阶段有足够的迭代来学习映射更好的 Ψθ( I t I_t It),这将为第二阶段提供更清晰的信号。
4. Experimental
测试集:数据集Vimeo90K(ToFlow附带的数据集),由于原始数据集过大(89800 --256*448) ,随机选择700张称为Vimeo700
训练集:使用两种噪声:σ∈[5,80],标准差为 25.5 的高斯噪声和 10% 椒盐噪声的混合噪声(Vimeo-Mixed);
mini-batch = 16 ,loss function
α
L
s
d
+
L
s
t
\alpha \mathcal{L}_{s d}+\mathcal{L}_{s t}
αLsd+Lst 通过ADAM优化器进行优化,超参数采用默认设置。epoch=40,learning rate=0.0001
比较对象:与以前的方法进行比较,方法包括
flow-based networks基于流的网络和end-toend training networks端到端的训练网络。训练了两个模型。
1.加入Vimeo-Mixed 噪声进行训练,以便与TOFlow[36]进行公平比较,并证能够处理各类噪声。
2.加入AWGN噪声进行训练,以便与 FastDVDNet[30]进行公平比较,并证明我们提出的先验图像去噪阶段的优越性
指标:Peak Signal-to-Noise Ratio (PSNR) and Structural SIMilariry index (SSIM)
与flow-based methods进行比较
和TOFlow方法进行比较:
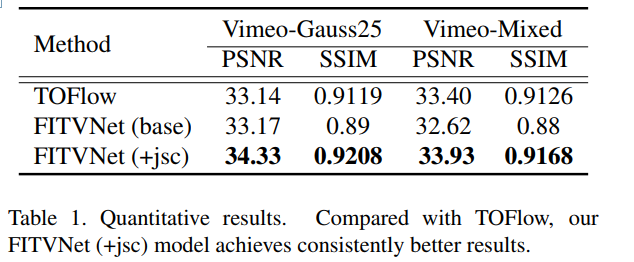
在Vimeo-Mixed上进行了40个epoch的训练,其中包含了前面提到的超参数。与TOFlow相比,我们的FITVNet (base)模型在PSNR和SSIM方面都取得了相当的性能,我们的FITVNet (+jsc)模型取得了一致更好的结果。上表证明了我们的模型除处理常用的高斯噪声外,还能处理混合噪声。

处理效果图:两阶段视频去噪方法也缓解了TOFlow中出现的过平滑现象,例如在图4的左栏中,这两个人所穿的衣服是绿色的,和他们周围的背景相似,TOFlow去噪后的结果无法恢复该区域的这些细节。类似的现象在右边一栏的结果中发生得更糟糕,篮球手移动得很快,在TOFlow去噪视频中,那个篮球的标志太模糊了。
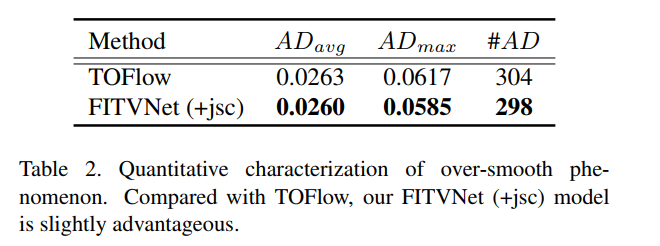
针对前景和背景很相似, 且弱光条件下,对象边界处理很模糊,但是FITVNet处理更好
表中AD是指生成图片与完好图片的偏差,可以看出FITVNet(+jsc)的生成的图片偏差更小
为了定量描述TOFlow中存在的这一问题,我们提出计算
平均偏差(Average Deviation, AD):即每个预测图像和干净图像间的差异图像。首先将图像划分k个32*32的块,计算每块的标准偏差,然后选择其中大于阈值的那些块,将其设置为所有块的偏差的平均值。最后,统一计算计算所有块的平均值AD作为指标。
运行时间:TOFlow改进了传统的基于流的网络,利用卷积网络来预测相邻帧的光流。然而,翘曲操作在整个过程中也需要更多的计算。相比之下,我们的FITVNet方法通过直接网络实现实现快速推理。如表3所示,256x448 RGB帧去噪只需要46.6ms,而TOFlow需要246ms。这些实验都运行在NVIDIA 2080ti卡的同一GPU上
与end-to-end methods进行比较
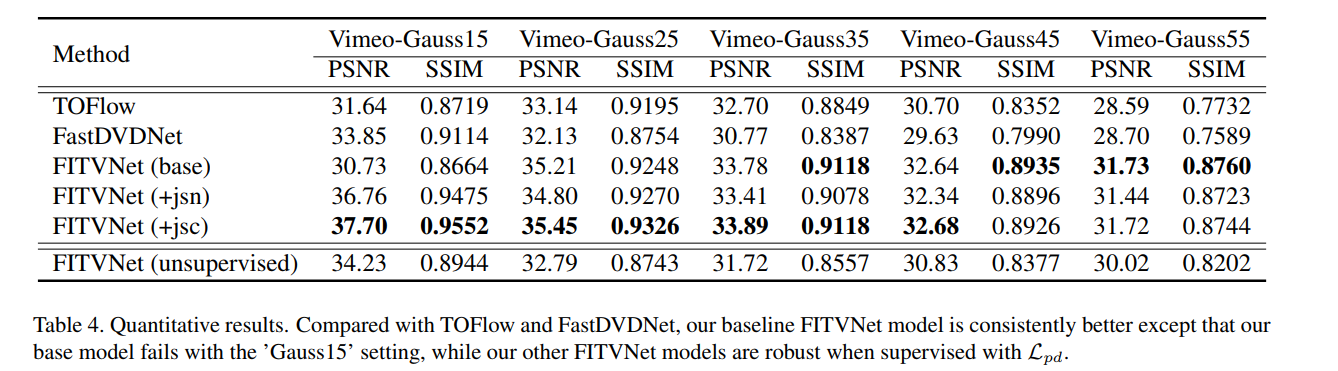
该模型与基于Vimeo700的不同AWGN的时空视频去噪算法FastDVDnet[30]进行了比较。模型均使用Vimeo90K进行训练,结果如表4所示。
由于我们无法访问TOFlow的训练过程,我们还使用TOFlow的开放检查点模型在Vimeo700上用高斯噪声测试TOFlow。TOFlow的结果是稳健的,但不如在Vimeo-Mixed上的性能好。
我们的FITVNet (base)模型在“Gauss15”中表现不太好,其他两个变体,FITVNet (+jsc)和FITVNet (+jsn),在 L p d \mathcal{L}_{p d} Lpd损耗的帮助下,在所有噪声水平上都很稳定
原文的图6忽略,一方面说明:先前去噪的模块会影响后面的空间时间去噪块的结果;另一方面说明:之前的图像去噪模块并没有去除所有的空间噪声,接下来的时空模块这次将学会同时对空间噪声和时间变形进行建模,说明两者的相互协作。

无监督实验
我们还测试了我们在第 3.4 节中介绍的无监督 FITVNet,结果也显示在表 4 中。虽然它的性能不如监督的干净帧的 FITVNet,但它在 PSNR 和在 Vimeo700 上与 TOFlow 的性能相当。请注意,FastDVDNet 和 TOFlow 都使用干净的帧进行监督。无监督 FITVNet 的运行时间与其他 FITVNet 模型相同。
此外,我们还在图 7(上图) 中定性地展示了我们的去噪帧。很明显,与 FastDVDNet 相比,我们的去噪帧表现出更少的空间噪声,这强调了先验图像去噪模块的重要性。我们完全无监督的去噪模型的成功也证明了我们对这种两阶段视频去噪框架的简单而有效的想法的力量。
5. 结论
图4中使用高斯15设定的基础模型的失败。表明直接使用时空网络的隐私运动估计 不如基于流的模型的稳定。未来,我们计算将流计算集成到我们的FITVNet中提高鲁棒性和性能。
,我们还在图 7(上图) 中定性地展示了我们的去噪帧。很明显,与 FastDVDNet 相比,我们的去噪帧表现出更少的空间噪声,这强调了先验图像去噪模块的重要性。我们完全无监督的去噪模型的成功也证明了我们对这种两阶段视频去噪框架的简单而有效的想法的力量。
5. 结论
图4中使用高斯15设定的基础模型的失败。表明直接使用时空网络的隐私运动估计 不如基于流的模型的稳定。未来,我们计算将流计算集成到我们的FITVNet中提高鲁棒性和性能。
同时计划在无监督去噪方法进行更多探索。















 4249
4249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









