






引言
深度学习领域有一个特别值得关注的趋势:以往许多特征、算法组件和一些设计上面临的选择都是通过人工设计和类似启发式的方式实现,但是这些方法正慢慢地被以数据驱动,“可学习”的方法取代。以目标检测算法为例:YOLO,Faster R-CNN,SSD等算法在生成候选框环节,都需要预先设定好的大小不同的Anchor,这就带有明显的人工设计痕迹;而最近提出的CornerNet则是Anchor-free的方法,即不需要预先人为设定Anchor。
当前几大流行的目标检测算法大致可以分为五个步骤:
- image feature generation
- region proposal generation
- region feature extraction
- region recognition
- duplicate removal
下图是这五个步骤在Faster R-CNN结构图上的对应关系。注意到上述步骤中除了步骤4天然地就完全依赖网络学习,不存在人为设计,而步骤1,2,3,5都有人为设计部分的存在,所以算法不是完全learnable的。
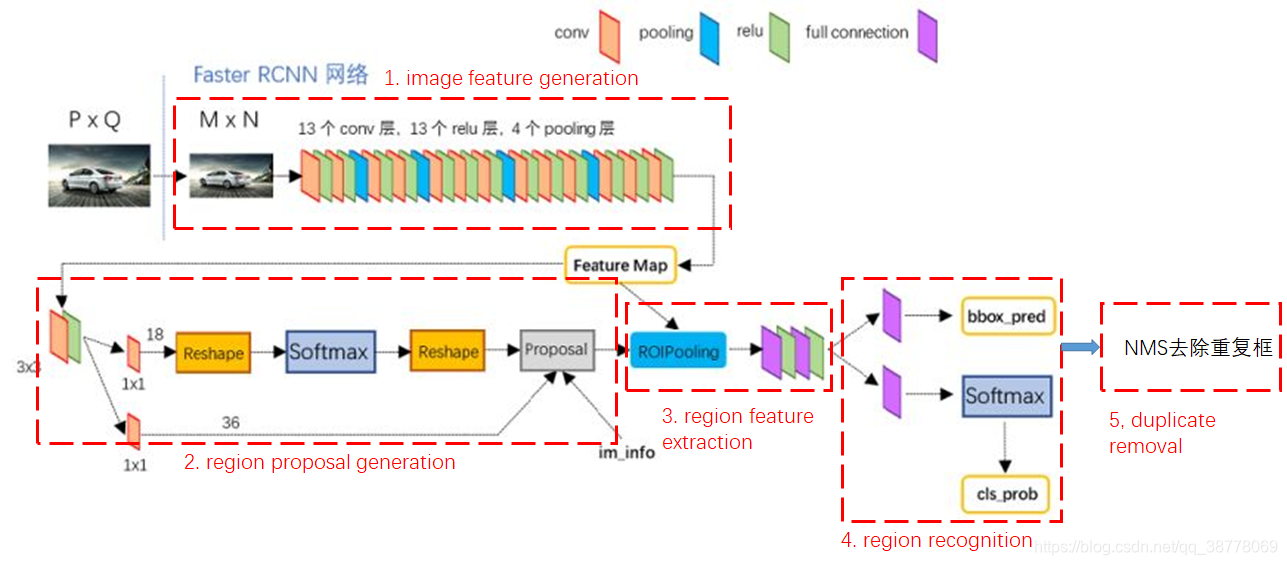
本文则是在目标检测算法的另一个环节:region feature extraction,提出了一种新方法来替代Faster R-CNN中的RoI Pooling方法。对于步骤3,常用RoI Pooling & RoI Align方法,可以参考这篇专栏:ROI操作:ROIPooling和ROIAlign
对Region Feature Extraction的形式化描述
假设从Image feature generation过程得到的feature map
x
\bf x
x的大小是
H
×
W
H \times W
H×W,通道数为
C
f
C_f
Cf,而Region proposal generation过程会生成一定数量的RoI,即候选区域。每个RoI表示为bounding box
b
b
b.
那么,Region feature extraction过程实现的就是根据
x
\bf x
x和
b
b
b来对不同大小的RoI产生相同大小的特征图表示
y
\bf y
y,从而输入到后续的region recognition环节。
这一过程用公式表述就是:
y
(
b
)
=
R
e
g
i
o
n
F
e
a
t
(
x
,
b
)
(1)
{\bf y}(b)=RegionFeat({\bf x},b) \tag 1
y(b)=RegionFeat(x,b)(1)
y
(
b
)
{\bf y}(b)
y(b)的维度大小为:
K
×
C
f
K \times C_f
K×Cf,其中
K
K
K表示RoI区域划分成的部分(parts)的数量。以RoI pooling方法为例,RoI pooling将输入的不固定大小的RoI切分成
7
×
7
7\times7
7×7个bins,每个bin通过avg或者max池化方式得到
1
×
C
f
1 \times C_f
1×Cf的向量表示,从而将不同大小的RoI的特征图统一到了
7
×
7
×
C
f
7 \times 7 \times C_f
7×7×Cf大小。这里
K
=
7
×
7
K=7 \times 7
K=7×7.
令
y
k
(
b
)
{\bf y}_k(b)
yk(b)表示结果中对应的第k个部分的特征图,在RoI pooling中就是第k个bin得到的向量表示。在RoI pooling中,
y
k
(
b
)
{\bf y}_k(b)
yk(b)的计算只和包含在第k个bin内部的特征图区域有关。而作者认为,
y
k
(
b
)
{\bf y}_k(b)
yk(b)的计算其实可以被推广到整个特征图
x
\bf x
x甚至是原图。具体地说,part feature(也就是
y
k
(
b
)
{\bf y}_k(b)
yk(b))的计算可以看作是第
k
k
k个部分关于
x
\bf x
x在一个support region
Ω
b
\Omega_b
Ωb里的所有位置
p
p
p上的加权求和,形式化表述如下:
y
k
(
b
)
=
∑
p
∈
Ω
b
w
k
(
b
,
p
,
x
)
⊙
x
(
p
)
(2)
{\bf y}_k(b) = \sum_{p\in \Omega_b}w_k(b,p,{\bf x}) \odot{\bf x}(p) \tag 2
yk(b)=p∈Ωb∑wk(b,p,x)⊙x(p)(2) 其中,
Ω
b
\Omega_b
Ωb包含的区域可以是RoI包含的区域,也可以包含更大的区域甚至整张图片。
x
(
p
)
{\bf x}(p)
x(p)表示p位置在
x
\bf x
x上的特征信息,
w
k
(
b
,
p
,
x
)
w_k(b,p,{\bf x})
wk(b,p,x)则是这些
x
(
p
)
{\bf x}(p)
x(p)在相加时的权重。权重值是归一化的,即
∑
p
∈
Ω
b
w
k
(
b
,
p
,
x
)
=
1
\sum_{p\in \Omega_b}w_k(b,p,{\bf x})=1
∑p∈Ωbwk(b,p,x)=1.
利用上述的形式化描述就将目前常用的region feature extraction方法统一起来。作者在文中描述了Regular RoI Pooling, Spatial Pyramid Pooling, Aligned RoI Pooling, Deformable RoI Pooling方法其实都是上述公式的特例,即对 w k ( b , p , x ) w_k(b,p,{\bf x}) wk(b,p,x)的不同具体实现和 Ω b \Omega_b Ωb指定的不同范围。
作者提出的方法
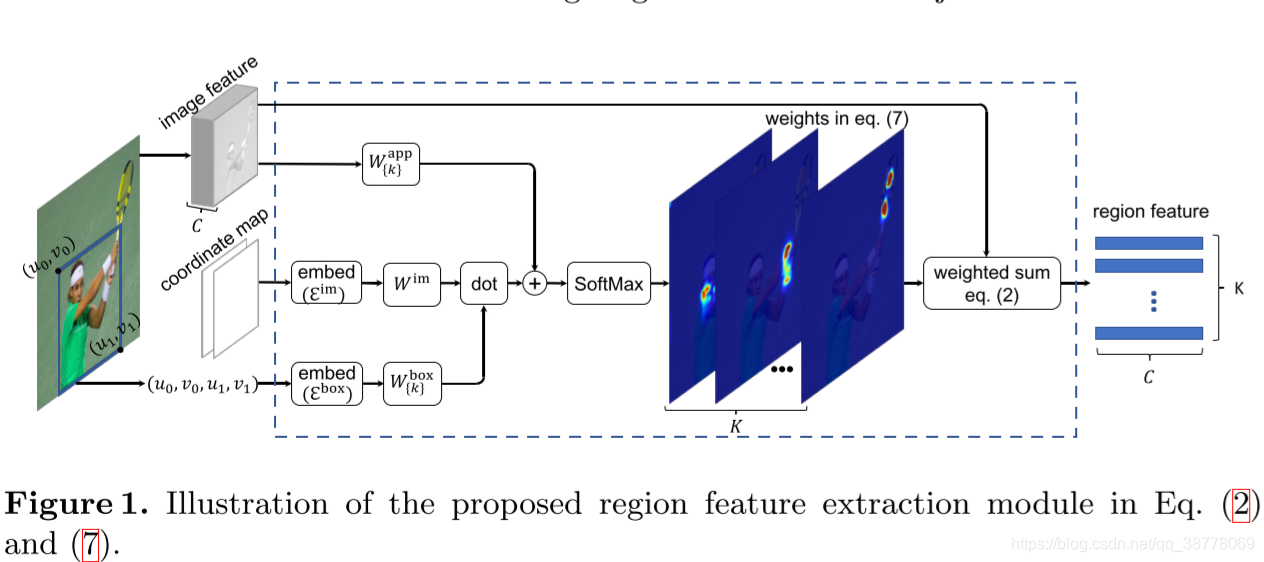
回到文章主题,作者想要做的就是"seek to learn the weight w k ( b , p , x ) w_k(b,p,{\bf x)} wk(b,p,x) in Eq.(2)"。作者从影响这个weight的两个因子出发:一个就是位置 p p p和RoI box b b b之间的几何关系,二是位置 p p p和image feature x \bf x x的自适应关系。然后作者设计了weight的计算公式如下: w k ( b , p , x ) ∝ exp ( G k ( b , p ) + A k ( x , p ) ) (3) w_k(b,p,{\bf x}) \propto \exp(G_k(b,p)+A_k({\bf x},p)) \tag 3 wk(b,p,x)∝exp(Gk(b,p)+Ak(x,p))(3)公式包含两个函数 G G G和 A A A, 分别针对上述两个影响因子。
1. G k ( b , p ) G_k(b,p) Gk(b,p)—captures geometric relation
G
k
(
b
,
p
)
G_k(b,p)
Gk(b,p)公式描述是论文最复杂的部分,
G
k
(
b
,
p
)
G_k(b,p)
Gk(b,p)计算公式如下:
G
k
(
b
,
p
)
=
⟨
W
k
b
o
x
⋅
E
b
o
x
(
b
)
,
W
i
m
⋅
E
i
m
(
p
)
⟩
(4)
G_k(b,p) =\left \langle W_k^{box} \cdot \mathcal{E}^{box}(b),W^{im} \cdot \mathcal{E}^{im}(p)\right \rangle \tag 4
Gk(b,p)=⟨Wkbox⋅Ebox(b),Wim⋅Eim(p)⟩(4) 首先,bounding box
b
b
b是表示框位置和大小的四维向量,position
p
p
p是表示点坐标的二维向量,
E
b
o
x
(
b
)
,
E
i
m
(
p
)
\mathcal{E}^{box}(b), \mathcal{E}^{im}(p)
Ebox(b),Eim(p)分别对
b
b
b和
p
p
p做embedding处理。定义
E
k
(
z
)
\mathcal{E}_k(z)
Ek(z)如下(注意力这里的
z
z
z是一个标量,我对原文中的公式稍作修改,更易理解一下):
E
k
(
z
)
=
{
sin
(
z
100
0
2
i
C
E
)
,
if
k
=
2
i
cos
(
z
100
0
2
i
C
E
)
,
if
k
=
2
i
+
1
(5)
\mathcal{E}_k(z) = \begin{cases} \sin(\frac{z}{1000^{\frac{2i}{C_\mathcal{E}}}}), & \text{if } k=2i\\ \cos(\frac{z}{1000^{\frac{2i}{C_\mathcal{E}}}}), & \text{if }k=2i+1 \end{cases} \tag 5
Ek(z)=⎩⎨⎧sin(1000CE2iz),cos(1000CE2iz),if k=2iif k=2i+1(5)
k
k
k的取值范围为
[
0
,
C
E
−
1
]
[0,C_\mathcal{E}-1]
[0,CE−1],从而有
E
(
z
)
\mathcal{E}(z)
E(z)将标量
z
z
z embedding为维度为
C
E
C_\mathcal{E}
CE的一个向量。因为向量
b
b
b包含4个标量,所以
E
b
o
x
(
b
)
\mathcal{E}^{box}(b)
Ebox(b)的维数为
4
⋅
C
E
4\cdot C_\mathcal{E}
4⋅CE,同理,
E
i
m
(
p
)
\mathcal{E}^{im}(p)
Eim(p)的维数为
2
⋅
C
E
2\cdot C_\mathcal{E}
2⋅CE.
第二步,用权重矩阵
W
i
m
W^{im}
Wim和
W
k
b
o
x
W_k^{box}
Wkbox分别乘上
E
i
m
(
p
)
\mathcal{E}^{im}(p)
Eim(p)和
E
b
o
x
(
b
)
\mathcal{E}^{box}(b)
Ebox(b)。这里
W
i
m
W^{im}
Wim和
W
k
b
o
x
W_k^{box}
Wkbox在实际中通过卷积实现,也就是说,它们是可学习的。注意到,
W
k
b
o
x
⋅
E
b
o
x
(
b
)
W_k^{box} \cdot \mathcal{E}^{box}(b)
Wkbox⋅Ebox(b)复杂度特别高,因为
E
b
o
x
(
b
)
\mathcal{E}^{box}(b)
Ebox(b)的维数为
4
⋅
C
E
4\cdot C_\mathcal{E}
4⋅CE。这里作者用了一个特别的技巧:将
W
k
b
o
x
W_k^{box}
Wkbox分解为
W
k
b
o
x
=
W
^
k
b
o
x
V
b
o
x
W_k^{box}=\hat{W}_k^{box}V^{box}
Wkbox=W^kboxVbox,其中
V
b
o
x
V^{box}
Vbox对所有的
k
k
k都是固定的,从而降低了
W
k
b
o
x
W_k^{box}
Wkbox的参数量。
最后对两者求内积,得到的就是几何关系权重(geometric relation weight)。公式4其实是一个注意力模型,常用于捕获长距离的或者不同类别目标间的依赖关系。
2. A k ( x , p ) A_k({\bf x},p) Ak(x,p)—uses the image features adaptively
A
k
(
x
,
p
)
A_k({\bf x},p)
Ak(x,p)的计算公式如下:
A
k
(
x
,
p
)
=
W
k
a
p
p
⋅
x
(
p
)
(6)
A_k({\bf x},p) = W_k^{app} \cdot {\bf x}(p) \tag 6
Ak(x,p)=Wkapp⋅x(p)(6)
在代码实现过程中直接用
1
×
1
1\times1
1×1卷积方式对整个
x
\bf x
x卷积,就可以得到所有位置上的
A
k
A_k
Ak, 而卷积参数就是公式中的
W
k
a
p
p
W_k^{app}
Wkapp.
下图表示了作者提出的整个Region feature extraction 过程:
3. 存在的问题和解决办法
在公式(2)中,如果
Ω
b
\Omega_b
Ωb所指范围是
x
\bf x
x,那么公式(2)的求和计算与公式(4)的求内积操作计算量就特别大。
针对计算量大的问题,作者采用的方法是对
x
\bf x
x进行稀疏采样作为
Ω
b
\Omega_b
Ωb。此外,考虑到RoI内部的点对特征的“贡献”应大于RoI外部的点,所以采样也不是直接在整个feature map上均匀采样,而是在RoI内部的点的采样密度大于在RoI外部的点的采样密度。采样的步长设置如下:
- 在RoI b b b的内部: s t r i d e x b = [ W b / 196 ] A N D s t r i d e y b = [ H b / 196 ] stride_x^b = [W_b/\sqrt{196}] \quad AND \quad stride_y^b = [H_b/\sqrt{196}] stridexb=[Wb/196]ANDstrideyb=[Hb/196]其中, s t r i d e x b stride_x^b stridexb和 s t r i d e y b stride_y^b strideyb分别是在两个方向上的采样步长, W b W_b Wb和 H b H_b Hb是RoI的长宽。
- 在RoI b b b的外部: s t r i d e o u t = [ H W / 196 ] stride^{out} = [\sqrt{HW/196}] strideout=[HW/196]
采用稀疏采样后的计算量对比如下(公式序号和原文不对应):
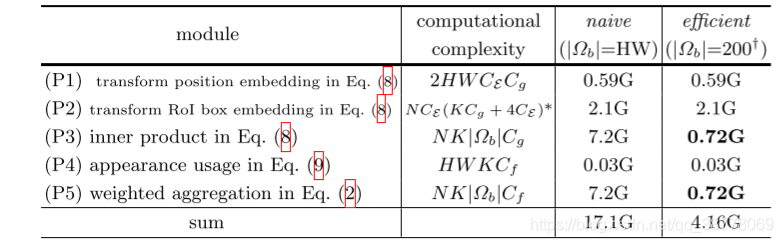
可以看到,那么公式(2)的求和计算与公式(4)的求内积操作计算量降低了10倍。作者指出,实验证明这种稀疏采样的方式较全特征图采样,最终结果在各种任务的精确度很接近。
实验
下面是在Faster R-CNN基础上,采用不同的region feature extraction方法的得到的对比结果:
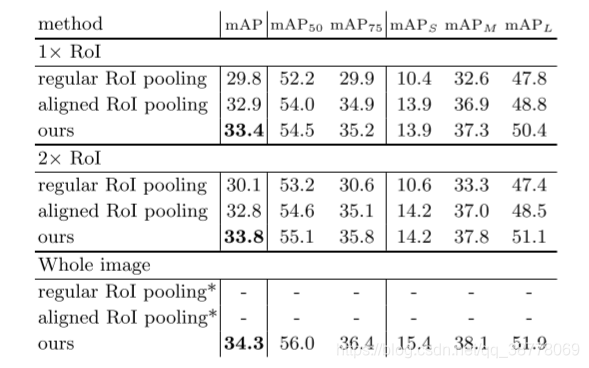
另外,作者还做了一系列的消融实验,具体包括:
- 对比不同大小的 Ω b \Omega_b Ωb对mAP的影响;
- 对比不同采样步长增加的计算量以及对mAP的影响;
- 对比权重计算中的 G k ( b , p ) G_k(b,p) Gk(b,p), A k ( x , p ) A_k({\bf x},p) Ak(x,p)对mAP的影响。
然后作者对训练后的权重
w
k
(
b
,
p
,
x
)
w_k(b,p,{\bf x})
wk(b,p,x)结果进行了可视化。结果显示,权重主要聚集到了RoI上,且更集中在前景上面。最有意思的一点是,作者最后计算了训练时的
w
1
,
w
2
.
.
.
w
K
w_{1},w_2...w_K
w1,w2...wK两两间的KL散度均值的变化,这一数值在第一轮训练后的迅速提升到趋于平稳展示了各个不同的部分(
k
k
k)确实在关注RoI的不同空间区域。这种对比KL散度的方法很值得借鉴。
最后作者也指出一个特别有意思的现象,这些权重好像学习了到了前景的具体位置,像给前景加上了mask,能否对语义分割任务有所启发?


















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









