









逻辑回归
基本概念
1. 逻辑回归是经典的二分类模型
2. 逻辑回归的过程是面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏
3. 逻辑回归主要应用于研究某些事件发生的概率,本质是极大似然估计
4. 逻辑回归的代价函数是交叉熵,激活函数是Sigmoid
优点
1. 速度快,适合二分类问题
2. 简单易于理解,直接看到各个特征的权重
3. 能容易地更新模型吸收新的数据
缺点
对数据和场景的适应能力有局限性,不如决策树算法适应性那么强
代价函数是交叉熵而不是MSE
为什么模型要使用 sigmoid 函数
1.广义模型推导所得
2.满足统计的最大熵模型
3.性质优秀,方便使用(Sigmoid函数是平滑的,而且任意阶可导,一阶二阶导数可以直接由函数值得到不用进行求导,这在实现中很实用
逻辑回归算法之Python实现
import numpy as np
class LogisticRegression:
def __init__(self):
"""
初始化 Logistic Regression 模型
"""
self.coef = None # 权重矩阵
self.intercept = None # 截距
self._theta = None # _theta[0]是intercept,_theta[1:]是coef
def sigmoid(self, x):
"""
sigmoid 函数
:param x: 参数x
:return: 取值y
"""
y = 1.0 / (1.0 + np.exp(-x))
return y
def loss_func(self, theta, x_b, y):
"""
损失函数
:param theta: 当前的权重和截距
:param x_b: 修改过的数据集(第一列为全1)
:param y: 数据集标签
:return:
"""
p_predict = self.sigmoid(x_b.dot(theta))
try:
return -np.sum(y * np.log(p_predict) + (1 - y) * np.log(1 - p_predict))
except:
return float('inf')
def d_loss_func(self, theta, x_b, y):
"""
损失函数的导数
:param theta: 当前的权重和截距
:param x_b: 修改过的数据集(第一列为全1)
:param y: 数据集标签
:return:
"""
out = self.sigmoid(x_b.dot(theta)) # 计算sigmoid函数的输出结果
return x_b.T.dot(out - y) / len(x_b)
def gradient_descent(self, x_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
"""
梯度下降函数
:param x_b: 修改过的数据集(第一列为全1)
:param y: 数据集标签
:param initial_theta: 初始权重矩阵
:param eta: 学习率
:param n_iters: 最大迭代周期
:param epsilon: 当两次训练损失函数下降小于此值是提前结束训练
:return:
"""
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = self.d_loss_func(theta, x_b, y)
last_theta = theta
theta = theta - eta * gradient
i_iter += 1
if abs(self.loss_func(theta, x_b, y) - self.loss_func(last_theta, x_b, y)) < epsilon:
break
return theta
def fit(self, train_data, train_label, eta=0.01, n_iters=1e4):
"""
模型训练函数
:param train_data: 训练数据集
:param train_label: 训练数据标签
:param eta: 学习率,默认为0.01
:param n_iters: 最大迭代次数
:return:
"""
assert train_data.shape[0] == train_label.shape[0], "训练数据集的长度需要和标签长度保持一致"
x_b = np.hstack([np.ones((train_data.shape[0], 1)), train_data]) # 在原有数据集前加全1列
initial_theta = np.zeros(x_b.shape[1]) # 初始化权重值
self._theta = self.gradient_descent(x_b, train_label, initial_theta, eta, n_iters) # 使用梯度下降训练数据
self.intercept = self._theta[0] # 得到截距
self.coef = self._theta[1:] # 得到权重矩阵
return self
def predict_proba(self, x_predict):
"""
得到预测的实际结果
:param x_predict: 待预测值
:return: 预测的实际结果
"""
x_b = np.hstack([np.ones((len(x_predict)), 1), x_predict])
return self.sigmoid(x_b.dot(self._theta))
def predict(self, x_predict):
"""
对数据进行分类
:param x_predict: 待分类的数据集
:return: 数据集分类
"""
proba = self.predict_proba(x_predict)
# 由于sigmoid函数的输出值是在0-1的,因此将小于0.5的归为一类,将大于0.5的归为一类
return np.array(proba > 0.5, dtype='int')
LR里每个样本点都要参与核计算,计算复杂度太高,故逻辑回归通常不用核函数。
逻辑回归是线性模型还是非线性模型?
线性回归
基本概念
1. 假设目标值(因变量)与特征值(自变量)之间线性相关(即满足一个多元一次方程,如:f(x)=w1x1+…+wnxn+b.)
2. 然后构建损失函数。
3. 最后通过令损失函数(均方误差)最小来确定参数。
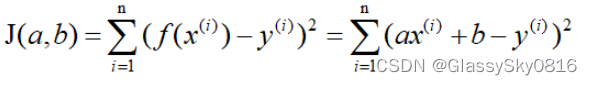
这里称J(a,b)为损失函数,明显可以看出它是个二次函数,即凸函数(这里的凸函数对应中文教材的凹函数),所以有最小值。当J(a,b)取最小值的时候,f(x)和y的差异最小,然后我们可以通过J(a,b)取最小值来确定a和b的值。
求解方法
下面介绍三种方法来确定a和b的值:
1. 最小二乘法
既然损失函数J(a,b)是凸函数,那么分别关于a和b对J(a,b)求偏导,并令其为零解出a和b。
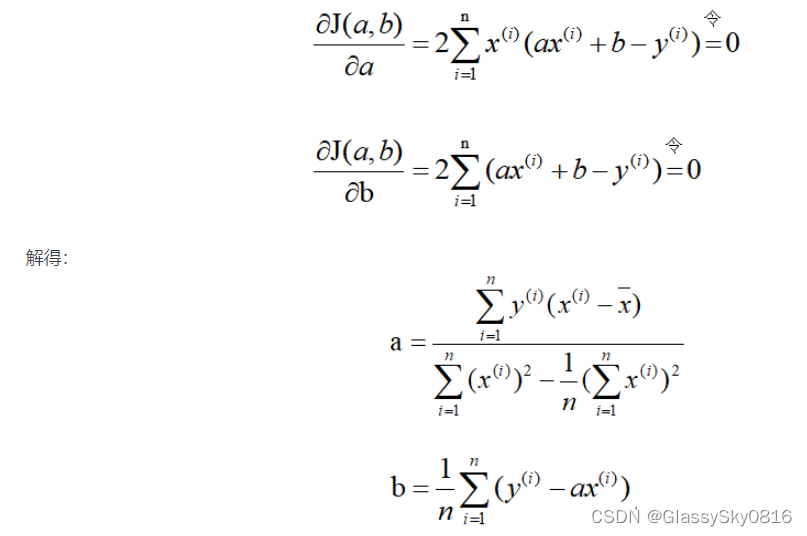
2.梯度下降法
梯度的本意是一个向量(矢量),表示某一函数(该函数一般是二元及以上的)在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。当函数是一元函数时,梯度就是导数。
- 梯度下降法是通用的,包括更为复杂的逻辑回归算法中也可以使用,但是对于较小的数据量来说它的速度并没有优势
- 正规方程的速度往往更快,但是当数量级达到一定的时候,还是梯度下降法更快,因为正规方程中需要对矩阵求逆,而求逆的时间复杂的是n的3次方
- 最小二乘法一般比较少用,虽然它的思想比较简单,在计算过程中需要对损失函数求导并令其为0,从而解出系数θ。但是对于计算机来说很难实现,所以一般不使用最小二乘法。
线性回归和逻辑回归的区别
-
线性回归适合连续型特征和标签的数据。逻辑回归适合离散型特征和标签的数据。
-
逻辑回归是逻辑函数里面套用回归函数。
-
线性回归重点是得出最佳拟合线。逻辑回归重点是得出决策面。
-
线性回归是通过决定系统R平方确定准确率。逻辑回归是通过正确率(概率值)决定模型是否准确。

















 5941
5941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











