








文章目录
Federated Reinforcement Learning for Collective Navigation of Robotic Swarms
1. 背景
1.1 集群机器人技术仿生背景
灵感来自群居昆虫,比如蚂蚁,它们利用信息素进行长距离觅食。由于群居昆虫能够集体完成单个个体无法完成的具有挑战性的任务,因此群体机器人系统有望在动态复杂环境下完成单个机器人难以完成的具有挑战性的任务。
示例1:蚁群协同工作

示例2 集群机器人协同工作

1.2 集群机器人设计难点
如何设计一个机器人在集群机器人中的个体行为
手工设计:
算法从目标群体行为中启发式地推导出个体行为规则,并通过迭代优化找到最优控制器。
局限性:
1.复杂的任务和复杂的环境手动派生单个控制器是非常具有挑战性
2.手动派生的控制器不能适应环境变化
自动设计:
强化学习(RL):RL允许从与环境的互动中找到最优控制器,在给定任务期间最大化总奖励。
深度强化学习(DRL):深度强化学习(DRL)以深度神经网络作为函数逼近器
优点:
单个机器人能够在不受外界干预的情况下自主找到最优行为。
局限性:
在现实世界中,大量机器人与中央服务器之间无法保证完美的、高带宽的通信。通信限制适用于机器人群特别有效的场景,例如水下检查、极端环境勘探或地下搜索和救援。在有限的通信条件下,集中式的、数据密集型的群集机器人系统训练方法在现实世界中应用可能变得无效甚至不可能。因此,需要采用减少大量机器人与中心服务器之间通信带宽的DRL训练策略。
个体行为容易解
协同工作设计难

1.3 联邦学习
联邦学习(FL)
联邦学习(FL)是一种新兴的具有大量智能体的机器学习模型的分布式训练范式。
优势:
1.大量减少与服务器的通信
在FL设置中,每个智能体使用本地收集的数据训练一个单独的模型。然后,将单独训练的模型定期与中央服务器共享,中央服务器将它们聚合起来,并将精细化的模型传回各个智能体。由于每个个体只与服务器通信共享模型,与传统的训练方法相比,交换的数据量可以大大减少。
2.隐私保护
由于它使用本地传感数据来训练局部模型,并且只发送模型,因此本地传感数据仍然隐藏在智能体内部。在战略基础设施或公共区域部署集群机器人系统时,这避免了安全和隐私问题。
3.定制化模型
由于个体模型是使用本地传感数据进行训练的,因此它能更好地适应实际智能体的个体特征。

2. 联邦学习算法设计
2.1 DRL训练算法
设计思路
当智能体需要连续的动作时,例如移动机器人,需要选择输出连续值的DRL算法,例如DDPG 、 PPO和TD3。而当需要离散动作时,如机器人在网格环境中移动,则需要使用离散动作的DRL算法,如DQN。
算法选择-深度确定性策略梯度(DDPG)算法
DDPG是一种针对具有连续观察和动作空间的代理的参与者-批评家、无模型的DRL算法。选择DDPG来训练集群机器人中的单个机器人。
在训练神经网络时,将过渡样本收集到经验回放记忆中,并从记忆中选择样本。由于内存可以被多个智能体访问,因此该算法可以用于多智能体的场景。
2.2 DDPG
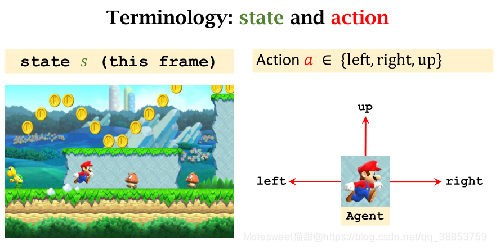
强化学习中的一些基础概念
动作随机变量A,样本a表征选取的动作
状态随机变量S,样本s表征当前的状态
策略函数
π
(
s
,
a
)
:
π
(
a
│
s
)
=
P
(
A
=
a
∣
S
=
s
)
π(s,a):π(a│s)=P(A=a|S=s)
π(s,a):π(a│s)=P(A=a∣S=s)表征取动作的可能性大小
例如:
π
(
l
e
f
t
│
s
)
=
0.2
π(left│s)=0.2
π(left│s)=0.2
奖励函数
r
e
w
a
r
d
reward
reward 记为
R
R
R
例如:收集一个金币
R
R
R=+1
状态转移:old state -> new state
例如:”up”action 产生了新的状态
折扣奖励
U
t
=
R
t
+
γ
R
t
+
1
+
γ
2
R
t
+
2
+
γ
3
R
t
+
3
+
…
U_t=R_t+γR_t+1+γ^2R_t+2+γ^3R_t+3+…
Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+…(奖励具有随机性)
动作价值函数
Q
(
s
,
a
)
Q(s,a)
Q(s,a)是策略函数的期望,给策略函数打分,反映的是一个智能体在状态s的情况下选取动作a的好坏。
Q
π
(
s
t
,
a
t
)
=
E
[
U
t
∣
S
t
=
s
t
,
A
t
=
a
t
]
Q_π(s_t,a_t)=E[U_t|S_t=s_t,A_t=a_t]
Qπ(st,at)=E[Ut∣St=st,At=at]
最优动作价值函数
Q
∗
(
s
,
a
)
Q^∗(s,a)
Q∗(s,a),最优动作价值函数也即选定使得期望最高的策略函数得到的期望
Q
∗
(
s
t
,
a
t
)
=
m
a
x
π
Q
π
(
s
t
,
a
t
)
Q^∗(s_t,a_t)=max_πQ_π(s_t,a_t)
Q∗(st,at)=maxπQπ(st,at)
状态价值函数,目的是评估调整策略
π
π
π,
V
π
(
s
)
V_π(s)
Vπ(s)评估当前状态的好坏
离散:
V
π
(
s
t
)
=
E
A
[
Q
π
(
s
t
,
A
)
]
=
∑
a
π
(
a
∣
s
t
)
⋅
Q
π
(
s
t
,
a
)
A
π
(
⋅
∣
s
t
)
V_π(s_t)=E_A[Q_π(s_t,A)]=∑_aπ(a|s_t) \cdot Q_π(s_t,a) A~π(\cdot|s_t)
Vπ(st)=EA[Qπ(st,A)]=∑aπ(a∣st)⋅Qπ(st,a)A π(⋅∣st)
连续:
V
π
(
s
t
)
=
E
A
[
Q
π
(
s
t
,
A
)
]
=
∫
π
(
a
∣
s
t
)
⋅
Q
π
(
s
t
,
a
)
d
a
V_π(s_t)=E_A[Q_π(s_t,A)]=∫π(a|s_t) \cdot Q_π(s_t,a)da
Vπ(st)=EA[Qπ(st,A)]=∫π(a∣st)⋅Qπ(st,a)da
TD Learning(时间差分算法)



主要思路是状态更新后,用部分已经真实发生变化的指标替代估计,会使得结果更加可信
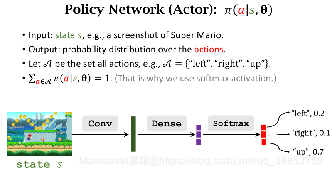
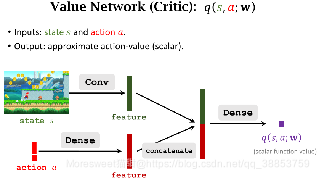
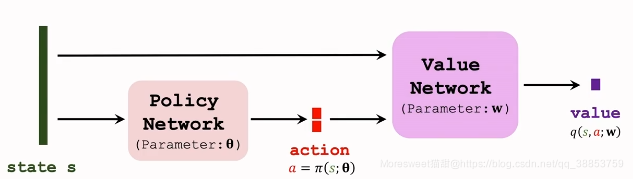
Actor-Critic Methods

状态价值函数

策略网络(Actor)

价值网络(Critic)

训练网络

深度确定性策略梯度(DDPG)算法



2.3 DRL训练策略
传统策略:
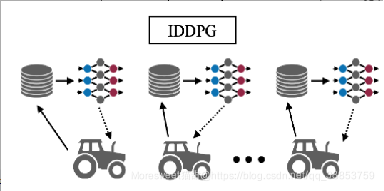
独立DDPG:IDDPG为集群中的每个机器人部署单独的神经网络和局部存储器。换句话说,机器人和服务器之间没有通信进行训练。
优点:
不使用中央服务器来共享数据样本或神经网络参数。
局限:
不允许利用群体机器人系统的集体性质进行学习。
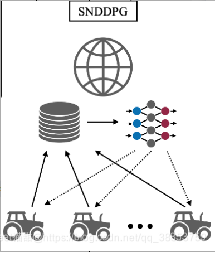
共享网络DDPG:在每个时间步中,机器人将转换样例数据传输到位于中央服务器的共享内存。在每个训练期间,网络更新由中央服务器执行,模型被分发给各个代理。
优点:
可以使用不同环境下不同代理收集的数据样本来训练中心服务器。它鼓励网络从更多样化的数据中学习,从而产生更通用的控制器。
局限:
它需要每个机器人与中央服务器之间频繁通信。机器人与中心服务器之间的通信越频繁,由于通信不稳定,训练越容易受到攻击。
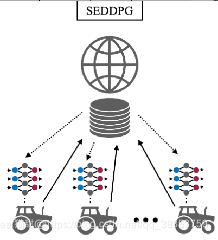
共享经验DDPG:智能体拥有独立的神经网络和共享的记忆。在原论文中,SEDDPG的优点是通过共享可以鼓励探索,从而更快收敛和更好的性能。
优点:
训练速度和性能都有所提高
局限:
机器人仍然与中央服务器共享收集到的数据,这需要很大的通信带宽。
基于FL的DRL训练策略
联邦学习的DDPG:仅在中央训练服务器中共享神经网络权值,而不共享本地收集的数据。
经验回放机制

以超级玛丽为例:Boss关的样本相当重要,但是Boss关的帧是非常少的,所以需要依靠经验池回放来扩充,使得策略可以更快收敛
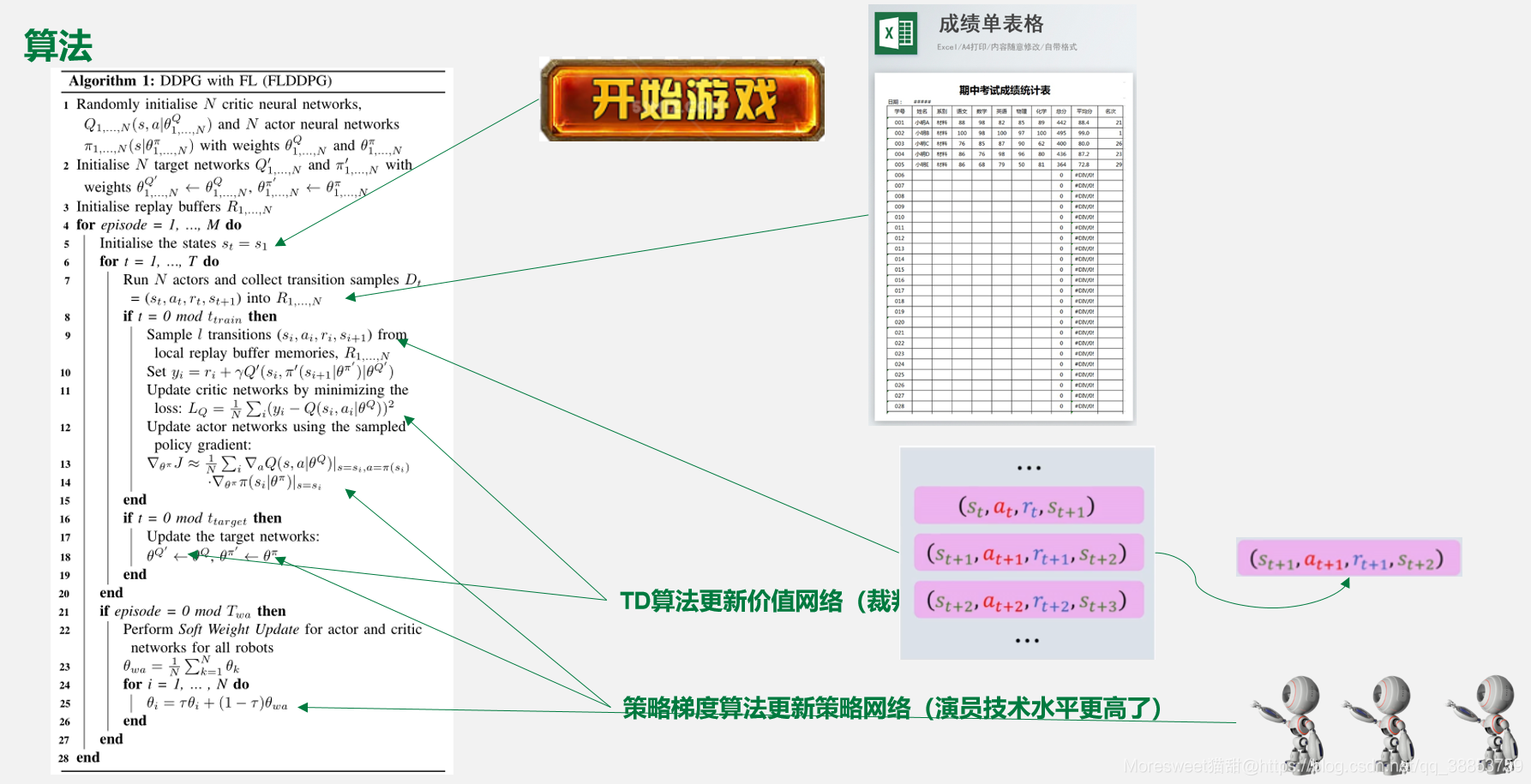
算法:

有的读者可能读到算法代码就头痛,实际上分块把握并不难,接下来我用图示分解:

3. 实验
3.1 设备布置
硬件设备
Turtlebot3
位姿信息:RPlidar A2
视觉传感:英特尔RealSense
工控机: 第8代Intel NUC i5
操作系统: Ubuntu 20.04
ROS版本:ROS Noetic
处理器: AMD Threadripper 3960X
显卡: Nvidia RTX 3090
内存: 64GB RAM
外部定位: 罗技C980(WhyCode基准 标记用于机器人的外部定位。WhyCode是一种低成本的基于视觉的定位系统,能够对大量黑白圆形基准标记进行实时姿态估计。)

场景布置

通信带宽限制
118MB(总数据量,即通信带宽和总通信时间的乘积)
3.2 策略模型
观察空间(在训练过程中,机器人收集观察数据,学习导航和避碰。)
导航时,收集目标与机器人当前位置在极坐标下的距离(d, θd)。为了避免碰撞,从激光测距仪上收集了24个传感器读数。在收集24个激光传感器读数后,将读数归一化到[0,1]之间,并将归一化读数反向,以便当障碍物接近机器人时,归一化传感器读数接近1,从而进行更有效的神经网络训练。当激光传感器的距离达到3.5 m时,只使用0.8 m以下的值来学习更有效的避碰算法。
运动空间(机器人的运动约束和安全性)
a
=
[
v
,
ω
]
a=[v, \omega]
a=[v,ω]
平动速度
v
∈
(
0
,
0.25
)
m
/
s
v \in(0,0.25) \mathrm{m} / \mathrm{s}
v∈(0,0.25)m/s
旋转速度
w
∈
(
−
π
2
,
π
2
)
r
a
d
/
s
w \in\left(-\frac{\pi}{2}, \frac{\pi}{2}\right) \mathrm{rad} / \mathrm{s}
w∈(−2π,2π)rad/s
奖励设计
导航
r
g
=
{
R
g
,
if arrived goal
0
,
otherwise
r
p
=
{
a
d
,
d
>
0
−
a
d
,
otherwise
r_{g}=\left\{\begin{array}{ll} R_{g}, & \text { if arrived goal } \\ 0, & \text { otherwise } \end{array}\right. r_{p}=\left\{\begin{array}{ll} a d, & d>0 \\ -a d, & \text { otherwise } \end{array}\right.
rg={Rg,0, if arrived goal otherwise rp={ad,−ad,d>0 otherwise
避障
r
c
=
{
R
c
,
if collision
0
,
otherwise
r
a
=
{
−
e
max
(
s
l
a
s
ϵ
r
)
∗
λ
,
any
(
s
laser
)
>
0
0
,
otherwise
r_{c}=\left\{\begin{array}{ll} R_{c}, & \text { if collision } \\ 0, & \text { otherwise } \end{array}\right. r_{a}=\left\{\begin{array}{ll} -e^{\max \left(s_{l a s \epsilon r}\right) * \lambda}, & \text { any }\left(s_{\text {laser }}\right)>0 \\ 0, & \text { otherwise } \end{array}\right.
rc={Rc,0, if collision otherwise ra={−emax(slasϵr)∗λ,0, any (slaser )>0 otherwise
3.3 表现度量
训练表现度量
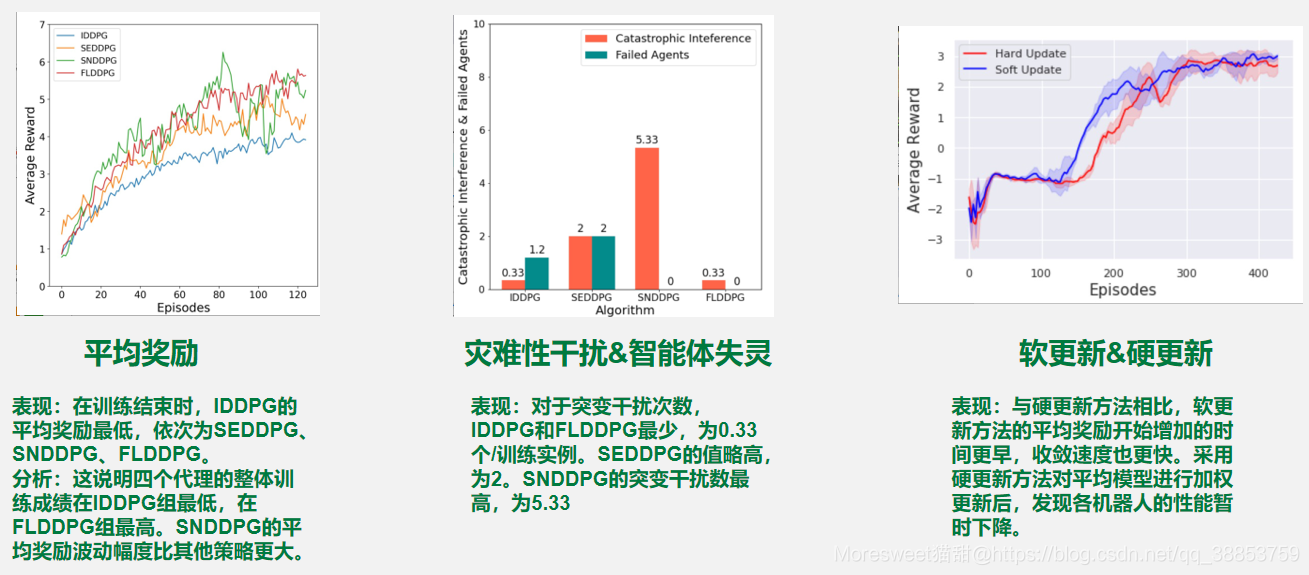
平均奖励(Average reward):实验中四个代理每一轮获得的奖励的平均值。
灾难性干扰(Catastrophic interference):当平均奖励变化超过平均奖励最大值和最小值之间的50%时的事件数。智能体失灵(Failed agent):表示在一个训练实例中失败的代理的平均数量。当训练过程中开始与结束时的平均报酬之差在1以内,最大值与最小值之差在1.5以内时,视为训练代理为失败代理。
a
=
[
v
,
ω
]
a=[v, \omega]
a=[v,ω]
评价表现度量
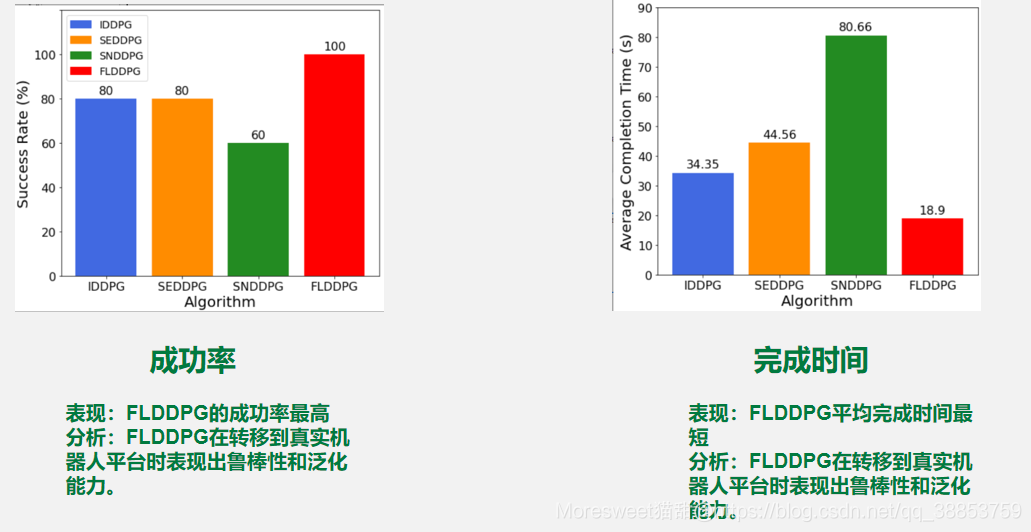
任务成功率(Success rate):是一轮训练内所有轮次中没有碰撞的成功轮次的比率。表示控制器的鲁棒性
任务完成时间(Completion time):表示所有机器人在不碰撞的情况下在时间限制内到达目标所花费的平均时间。表示每种训练策略的优化性能
实验方式
在模拟评价实验中,每个agent在训练阶段使用4个训练模型,在20次以上的环境中平均4个agent的表现,计算出成功率和完成时间。
Refernces
[1] Na S, Rouček T, Ulrich J, et al. Federated reinforcement learning for collective navigation of robotic swarms[J]. IEEE Transactions on cognitive and developmental systems, 2023.
[2] 王树森RL https://github.com/DeepRLChinese/DeepRL-Chinese















 7520
7520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











