







我们面对的很多数据其实是图(graph),图在生活中无处不在,如社交网络,知识图谱,蛋白质结构等。

图的概念
对于图,我们习惯上用 G = ( V , E ) G = (V,E) G=(V,E) 表示。这里 V V V 是图中节点的集合,而 E E E 为边的集合,这里记图的节点数为 N N N 。一个 G G G 中有 3 个比较重要的矩阵:
- 邻接矩阵 A A A:adjacency matrix,用来表示节点间的连接关系,这里我们假定是 0 - 1 矩阵;
- 度矩阵 D D D:degree matrix,每个节点的度指的是其连接的节点数,这是一个对角矩阵,其中对角线元素 D i i = ∑ j A i j D_{ii} = \sum\limits_j A_{ij} Dii=j∑Aij;
- 特征矩阵 X X X :用于表示节点的特征 X ∈ R N × F X \in \mathbb{R}^{N \times F} X∈RN×F,这里 F F F 是特征的维度;
数学表示是比较抽象的,下面是一个实例:
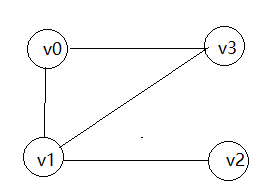
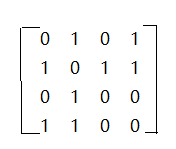
图卷积

以给图中每个节点增加自连接,实现上可以直接改变邻接矩阵:
A
~
=
A
+
I
N
\tilde{A} = A + I_N
A~=A+IN
可以对邻接矩阵进行归一化,使得
A
A
A 的每行和值为 1,在实现上我们可以乘以度矩阵的逆矩阵:
D
~
−
1
A
~
\tilde{D}^{-1}\tilde{A}
D~−1A~,这里的度矩阵是更新
A
A
A 后重新计算的。这样我们就得到:
H
(
k
+
1
)
=
f
(
H
(
k
)
,
A
)
=
σ
(
D
~
−
1
A
~
H
(
k
)
W
(
k
)
)
H^{(k+1)}=f(H^{(k)}, A)=\sigma(\tilde{D}^{-1}\tilde{A}H^{(k)}W^{(k)})
H(k+1)=f(H(k),A)=σ(D~−1A~H(k)W(k))
相比加法规则,这种聚合方式其实是对领域节点特征求平均,这里:
(
D
~
−
1
A
~
H
)
i
=
(
D
~
−
1
A
~
)
i
H
=
(
∑
k
D
~
i
k
−
1
A
~
i
)
H
=
(
D
~
i
i
−
1
A
~
i
)
H
=
D
~
i
i
−
1
∑
j
A
~
i
j
H
j
=
∑
j
1
D
~
i
i
A
~
i
j
H
j
\begin{aligned} (\tilde{D}^{-1}\tilde{A}H)_i &= (\tilde{D}^{-1}\tilde{A})_iH\\ &= (\sum_k\tilde{D}^{-1}_{ik}\tilde{A}_i)H \\ &= (\tilde{D}^{-1}_{ii}\tilde{A}_i)H \\ &= \tilde{D}^{-1}_{ii}\sum_j\tilde{A}_{ij}H_j \\ &= \sum_j\frac{1}{\tilde{D}_{ii}}\tilde{A}_{ij}H_j \end{aligned}
(D~−1A~H)i=(D~−1A~)iH=(k∑D~ik−1A~i)H=(D~ii−1A~i)H=D~ii−1j∑A~ijHj=j∑D~ii1A~ijHj
由于 D i i = ∑ j A i j D_{ii} = \sum\limits_j A_{ij} Dii=j∑Aij ,所以这种聚合方式其实就是求平均,对领域节点的特征是求平均值,这样就进行了归一化,避免求和方式所造成的问题。
更进一步地,我们可以采用对称归一化来进行聚合操作,这就是论文1中所提出的图卷积方法:
H
(
k
+
1
)
=
f
(
H
(
k
)
,
A
)
=
σ
(
D
~
−
1
2
A
~
D
~
−
1
2
H
(
k
)
W
(
k
)
)
H^{(k+1)}=f(H^{(k)}, A)=\sigma(\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}H^{(k)}W^{(k)})
H(k+1)=f(H(k),A)=σ(D~−21A~D~−21H(k)W(k))
这种新的聚合方法不再是单单地对邻域节点特征进行平均,这里:
(
D
~
−
1
2
A
~
D
~
−
1
2
H
)
i
=
(
D
~
−
1
2
A
~
)
i
D
~
−
1
2
H
=
(
∑
k
D
~
i
k
−
1
2
A
~
i
)
D
~
−
1
2
H
=
D
~
i
i
−
1
2
∑
j
A
~
i
j
∑
k
D
~
j
k
−
1
2
H
j
=
D
~
i
i
−
1
2
∑
j
A
~
i
j
D
~
j
j
−
1
2
H
j
=
∑
j
1
D
~
i
i
D
~
j
j
A
~
i
j
H
j
\begin{aligned} (\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}H)_i &= (\tilde{D}^{-\frac{1}{2}}\tilde{A})_i\tilde{D}^{-\frac{1}{2}}H\\\\ &= (\sum_k\tilde{D}^{-\frac{1}{2}}_{ik}\tilde{A}_i)\tilde{D}^{-\frac{1}{2}}H \\ &= \tilde{D}^{-\frac{1}{2}}_{ii}\sum_j\tilde{A}_{ij}\sum_k\tilde{D}^{-\frac{1}{2}}_{jk}H_j \\ &= \tilde{D}^{-\frac{1}{2}}_{ii}\sum_j\tilde{A}_{ij}\tilde{D}^{-\frac{1}{2}}_{jj}H_j \\ &= \sum_j\frac{1}{\sqrt{\tilde{D}_{ii}\tilde{D}_{jj}}}\tilde{A}_{ij}H_j \end{aligned}
(D~−21A~D~−21H)i=(D~−21A~)iD~−21H=(k∑D~ik−21A~i)D~−21H=D~ii−21j∑A~ijk∑D~jk−21Hj=D~ii−21j∑A~ijD~jj−21Hj=j∑D~iiD~jj1A~ijHj
可以看到这种聚合方式不仅考虑了节点i的度,而且也考虑了邻居节点
j
j
j 的度,当邻居节点j的度较大时,而特征反而会受到抑制 。
这种图卷积方法其实基于傅里叶理论的 谱图卷积 的一阶近似,关于更多的数学证明比较难理解,这里不做展开,详情可见论文。
GCN 之 tensorflow 2.0 实现
一般情况下,简单的应用可以直接使用函数式API编程,对于复杂的网络的定义和训练可以使用类继承的方式,这样的代码逻辑和封装性较好。本程序基于 Github repo 进行改编,更加符合 model 子类化的个人习惯,以下简述核心部分。
自定义 layer
定义了稀疏 SparseDrop 和 GraphConv 层分别用于稀疏输入的 Dropout 和 Convolution。
class SparseDrop(layers.Layer):
"""
Sparse dropout layer.
"""
def __init__(self, num_features_nonzero,
dropout=0.,
is_sparse_inputs=False, **kwargs):
super(SparseDrop, self).__init__(**kwargs)
self.dropout = dropout
self.is_sparse_inputs = is_sparse_inputs
self.num_features_nonzero = num_features_nonzero
def call(self, inputs, training=None):
x = inputs
# dropout
if training is not False and self.is_sparse_inputs:
x = sparse_dropout(x, self.dropout, self.num_features_nonzero)
elif training is not False:
x = tf.nn.dropout(x, self.dropout)
return x
class GraphConv(layers.Layer):
"""
Graph convolution layer.
"""
def __init__(self, input_dim, output_dim,
is_sparse_inputs=False,
bias=False,
featureless=False, **kwargs):
super(GraphConv, self).__init__(**kwargs)
self.is_sparse_inputs = is_sparse_inputs
self.featureless = featureless
self.bias = bias
self.weights_ = []
for i in range(1):
w = self.add_variable('weight' + str(i), [input_dim, output_dim])
self.weights_.append(w)
if self.bias:
self.bias = self.add_variable('bias', [output_dim])
def call(self, inputs, training=None):
x, support_ = inputs
# convolve
supports = list()
for i in range(len(support_)):
if not self.featureless: # if it has features x
pre_sup = dot(x, self.weights_[i], sparse=self.is_sparse_inputs)
else:
pre_sup = self.weights_[i]
support = dot(support_[i], pre_sup, sparse=True)
supports.append(support)
output = tf.add_n(supports)
# bias
if self.bias:
output += self.bias
return output
自定义 GCN
class GCN(keras.Model):
def __init__(self, input_dim, output_dim, num_features_nonzero, **kwargs):
super(GCN, self).__init__(**kwargs)
self.input_dim = input_dim # 1433
self.output_dim = output_dim
print('input dim:', input_dim)
print('output dim:', output_dim)
print('num_features_nonzero:', num_features_nonzero)
self.d1 = SparseDrop(num_features_nonzero=num_features_nonzero,
dropout=args.dropout,
is_sparse_inputs=True)
self.c1 = GraphConv(input_dim=self.input_dim, # 1433
output_dim=args.hidden1, # 16
is_sparse_inputs=True)
self.a1 = Activation(activation='relu')
self.d2 = Dropout(args.dropout)
self.c2 = GraphConv(input_dim=args.hidden1, # 16
output_dim=self.output_dim) # 7
self.a2 = Activation(activation='softmax')
for p in self.trainable_variables:
print(p.name, p.shape, type(p))
def call(self, inputs, training=None):
"""
:param inputs:
:param training:
:return:
"""
x, label, mask, support = inputs
h = self.d1(x)
h = self.c1((h, support), training)
h = self.a1(h)
h = self.d2(h)
h = self.c2((h, support), training)
outputs = self.a1(h)
self.outputs = outputs
self.loss, self.acc = self.evaluate((label, mask), outputs)
return outputs
def evaluate(self, inputs, outputs):
label, mask = inputs
# Weight decay loss
loss = tf.zeros([])
for var in self.c1.trainable_variables:
loss += args.weight_decay * tf.nn.l2_loss(var)
# Cross entropy error
loss += masked_softmax_cross_entropy(outputs, label, mask)
acc = masked_accuracy(outputs, label, mask)
return loss, acc
def predict(self, inputs, training=None):
# outputs = self.call(self, inputs, training=training)
return tf.nn.softmax(self.outputs)
核心模块
# Create model
model = GCN(input_dim=features[2][1],
output_dim=y_train.shape[1],
num_features_nonzero=features[1].shape) # [1433]
optimizer = optimizers.Adam(lr=1e-2)
# model.compile(optimizer=optimizer, loss=)
for epoch in range(args.epochs):
# Training step
with tf.GradientTape() as tape:
outputs = model((features, train_label, train_mask, support))
loss, acc = model.evaluate((train_label, train_mask), outputs)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# validation step
outputs = model((features, val_label, val_mask, support), training=False)
val_loss, val_acc = model.evaluate((val_label, val_mask), outputs)
if epoch % 20 == 0:
print('Epoch %-3d' % epoch,
'loss=%-6.4f' % float(loss),
'acc=%-6.4f' % float(acc),
'loss=%-6.4f' % float(val_loss),
'val=%-6.4f' % float(val_acc))
outputs = model((features, test_label, test_mask, support), training=False)
test_loss, test_acc = model.evaluate((test_label, test_mask), outputs)
其实所谓的“模型子类化”就是自己实现一个类来继承 model类,构建一个model类的子类,需要实现三个方法,即:
__init__()
call()
compute_output_shape()
自定义层也是实现三个方法,分别是:
build(input_shape):
call(x):
compute_output_shape(input_shape):
总之,针对作业使用正确的 API。虽然模型子类化较为灵活,但代价是复杂性更高且用户出错率更高。如果可能,请首选函数式 API。















 2297
2297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









