




关于开展“人工智能论文阅读与分享系列”的情况说明
一、核心宗旨
本系列活动以“深研AI论文、提升科研能力、共享学习成果”为核心宗旨,聚焦人工智能领域的经典与前沿论文,通过系统性阅读、深度拆解与公开分享,实现个人科研素养的提升与知识价值的传递。
二、 阅读范围与选择标准
1. 阅读范围与选择标准
- 核心领域:聚焦人工智能细分方向,包括但不限于大语言模型、计算机视觉、强化学习、多模态交互、AI伦理与安全等。
- 论文类型:
- 经典奠基论文(如《Attention Is All You Need》《ImageNet Classification with Deep Convolutional Neural Networks》等领域里程碑成果);
- 顶刊顶会前沿论文(近3年NeurIPS、ICML、ICLR、CVPR、ACL等会议及《Nature》《Science》子刊的热点成果);
- 具有实操价值的技术类论文(含开源项目、模型训练调优方法的论文)。
- 选择原则:兼顾“理论深度”与“可借鉴性”,优先选择对个人研究方向有直接启发、或包含可复现实验/代码的论文。
三、开展理由
-
定向提升科研能力
人工智能领域知识更新快、分支多,仅靠碎片化学习难以形成科研思维。通过“精读+拆解”论文,可系统训练“发现问题-分析方法-评估结果”的科研逻辑,逐步掌握学术写作规范(如创新点表述、实验论证方式)与研究设计思路(如如何选择对比方法、如何设计 ablation study),为后续开展原创研究奠定基础。 -
倒逼深度思考与知识内化
“分享”是检验理解的最佳方式。在准备分享内容时,需将论文的复杂逻辑转化为通俗易懂的表达,这一过程会倒逼自己发现知识盲区(如“某公式推导步骤不清晰”“创新点与传统方法的差异未吃透”),进而加深理解。同时,接收他人反馈(如“这个结论是否有前提条件?”)可拓宽思考维度,避免闭门造车。 -
构建个人知识体系与学术影响力
长期聚焦AI领域论文阅读与分享,既能按“技术演进脉络”(如从RNN到Transformer的发展)构建系统化知识网络,也能通过持续输出形成个人在细分领域的认知标签。例如,专注于“多模态大模型”的分享,可逐步成为该方向的“知识传播者”,为未来学术合作或职业发展积累资源。 -
促进开源精神与行业交流
人工智能的发展依赖开源与协作。分享论文解读与代码实践,既能为初学者提供入门参考(减少重复踩坑),也能通过同行交流获得新启发(如“有人提出用某方法改进原论文缺陷”),形成“输入-消化-输出-反馈”的正向循环。
四、总结
本系列活动的本质是“以读促研,以分享促深化”:通过精读论文定向提升科研硬实力,通过分享输出实现知识内化与价值传递。最终目标不仅是成为“AI论文的读者”,更希望能成为“AI领域的一名专家”和“技术创新的探索者”。
这一过程既是个人科研成长的“练兵场”,也是对实现“从学习者到研究者”的转变具有重要意义。
分割线
Qwen-Image:文图生成领域的创新先锋
摘要
近日,Qwen Team团队重磅推出Qwen系列在图像生成领域的全新力作——Qwen-Image。并公布了相关技术报告,里面详细阐述了这一基础模型在复杂文本渲染和精准图像编辑方面取得的突破性进展,为文图生成技术开拓了新境界。
在图像生成领域,长久以来存在一个棘手难题,即如何在生成的图像中精准渲染文本。像DALL-E 3、Midjourney这类主流图像生成模型,虽能产出充满创意与艺术感的图像,可一旦涉及文本渲染,无论是简单单词、复杂段落,还是中文这样的语素文字,都极易出错。Qwen-Image的诞生,正是为了攻克这两大核心挑战。
同时,Qwen-Image在图像编辑方面的表现同样可圈可点。它支持风格迁移、物体增减、姿态调整等多种编辑操作,普通用户利用它也能实现专业级的图像编辑效果。并且,通过独特的多任务训练范式,它在编辑过程中能够出色地保持图像的一致性,避免了编辑后图像风格突变、主体失真等问题。例如,当对一张人物图像进行“将人物的站姿由站立改为坐姿”的编辑操作时,Qwen-Image不仅能精准调整人物姿态,还能保证人物的面部特征、服饰纹理以及背景环境等都与原图保持高度一致,实现高保真度的图像编辑。
为实现这些突破,Qwen-Image团队精心设计了创新架构与训练策略。在数据处理上,构建了一套涵盖大规模数据收集、严格过滤、精准标注、高效合成以及合理平衡的综合数据管道,让模型得以接触海量优质的图文数据,为文本渲染学习筑牢根基。
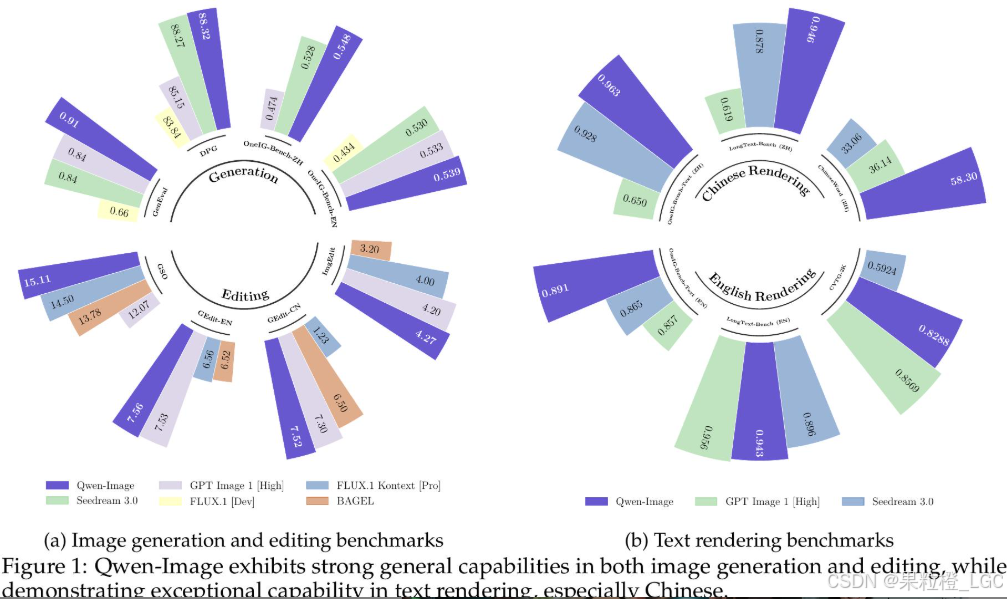
在多个权威基准测试中,Qwen-Image成绩斐然。在用于通用图像生成的GenEval、DPG和OneIG-Bench,以及用于图像编辑的GEdit、ImgEdit和GSO等测试中,均展现出顶尖水平。尤其在针对文本渲染的LongText-Bench、ChineseWord和TextCraft测试里,Qwen-Image优势显著,在中文文本渲染方面更是大幅领先现有先进模型 。
模型和代码原来地:
https://huggingface.co/Qwen/Qwen-Image
https://modelscope.cn/models/Qwen/Qwen-Image
https://github.com/QwenLM/Qwen-Image
研究背景
Qwen-Image的研究背景植根于图像生成领域的发展现状与未解决的核心挑战,具体可从以下两方面展开:
1. 图像生成技术的发展与成就
近年来,以文本到图像生成(T2I)和图像编辑(TI2I)为核心的图像生成模型已成为现代人工智能的基础组件,能够从文本提示中合成或修改视觉连贯、语义一致的内容。扩散架构(如Diffusion Models)的出现推动了该领域的显著进步,使其能够生成高分辨率图像并捕捉细粒度的语义细节,代表性成果包括DALL-E 3、Midjourney、FLUX等模型。这些模型在生成逼真图像、支持多样艺术风格等方面取得了突破,为数字内容创作、设计等领域提供了强大工具。
2. 现有技术的核心挑战
尽管进展显著,图像生成领域仍存在两个关键未解决的挑战,这也是Qwen-Image的研究出发点:
-
复杂文本渲染的对齐难题
现有模型(包括GPT Image 1、Seedream 3.0等先进商业模型)在处理涉及复杂文本的生成任务时存在局限:- 难以准确渲染多行文本、非字母语言(如中文等表意文字);
- 文本与视觉元素的局部插入和无缝融合能力较弱,常出现文本模糊、错漏或布局混乱。
-
图像编辑的一致性难题
在图像编辑任务中,现有模型难以同时满足“视觉一致性”和“语义连贯性”:- 视觉一致性:仅修改目标区域,同时保留其他视觉细节(如修改头发颜色但不改变面部特征);
- 语义连贯性:在结构变化中保持全局语义(如修改人物姿势但维持身份和场景一致性)。
这些挑战限制了图像生成模型在实际场景中的应用(如含复杂文本的设计、精准图像编辑等),因此需要通过新的技术方案突破现有瓶颈——Qwen-Image正是为解决这些问题而提出的图像生成基础模型。
Qwen-Image针对复杂文本渲染和精准图像编辑两大核心挑战,提出了一系列创新方法,具体解决方案如下:
一、解决复杂文本渲染挑战的核心方法
为突破文本渲染(尤其是中文等表意文字)的准确性和复杂性限制,Qwen-Image采用了综合数据工程与渐进式训练策略的组合方案:
-
构建全链路数据管道
设计涵盖大规模数据收集、严格过滤、精准标注、合成增强和类别平衡的完整数据流程,确保模型能接触到丰富且高质量的文本-图像对。其中,合成数据策略包含三种渲染方式:- 纯文本渲染(在简单背景上生成文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3441
3441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











